
思科的服务器困局:投资增长,还是退出? 原创
思科错过了从刀片到机架服务器的过渡,销售增长表现不尽如人意,没有很好地面向云提供商售卖,市场份额较小。思科是应该投资以实现增长,还是完全退出服务器业务?

思科在2017财年第三季度的结果令人失望,收入同比减少1%至119亿美元。数据中心部分(主要是UCS服务器)收入为7.67亿美元,减少5%,只占到思科总收入的6%。
上个季度思科的数据中心收入为7.9亿美元,同比减少4%,上个季度为8.34亿美元,同比减少3%,进入下滑模式。
Stifel分析师和MD Aaron Raker绘制了下面的表格,表格显示了思科的数据中心收入和同比变化:
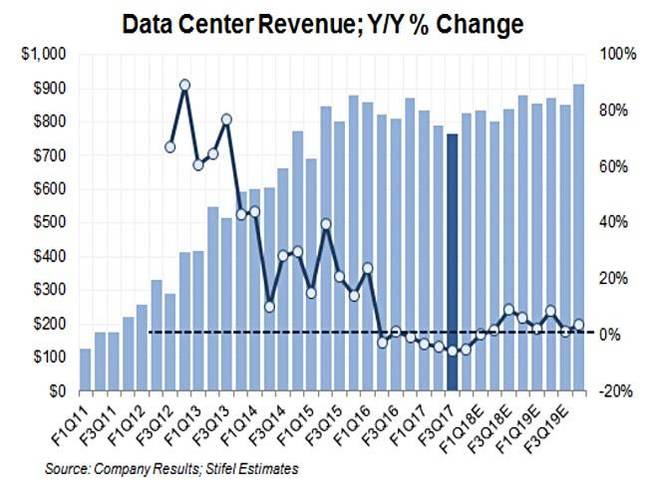
这个表格显示了实际数字以及9个季度的评估。
UCS服务器首次推出的时候是一颗耀眼的明星,接下来呢。
根据Gartner和IDC的数据显示,服务器整体销售下滑,戴尔和HPE领跑市场,其次是IBM、联想和华为。
根据IDC的数据,2016年第四季度思科的市场份额为6.3%,HPE为23.6%,戴尔为17.6%,IBM为12.3%,联想为6.5%。原始设备制造商(ODM)提供商占到了7.9%,思科为什么落后了?
Rakers根据架构种类绘制了过去几年的季度服务器销售情况:
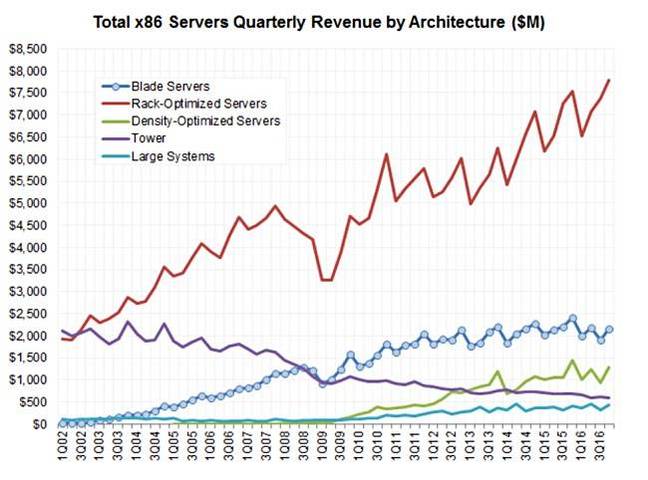
机架优化的服务器销售是最大赢家,刀片服务器销售位列第二,与第一差距较大,增长停滞。密度优化的服务器销售持平,塔式服务器下滑,大型系统份额最小,不过有小幅增长。
Rakers还以刀片和机架划分了思科的UCS服务器销售,显示收入和收入比例:
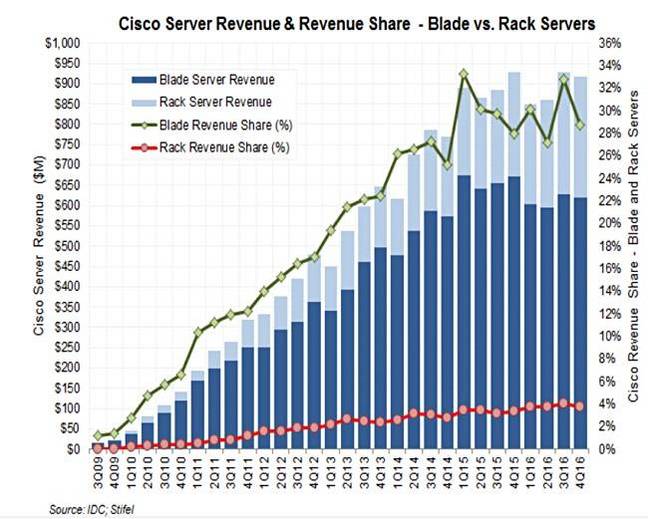
思科UCS的收入主要来自于刀片服务器(下滑到第二位的架构)而不是机架服务器(主流且还在增长)。结论是不可避免的,思科误导了服务器市场,收入增长放缓,然后从2015财年第一季度开始停滞。
Rakers表示:“思科继续面临着从刀片到机架服务器的混合组合,思科有大约30%的刀片份额,不到4%的机架服务器份额。”
思科把自己的服务器售卖给企业,而不是查大规模数据中心或者云服务提供商,还有像超微这样的ODM,或者浪潮这样的中国服务器提供商。
思科一直在推动自己的HyperFlex超融合基础设施一体机(HCIA),使用OEM自Springpath的软件。3月思科表示,在经过9个月的销售之后,HyperFlex累积获得1100家客户。Nutanix有大约5400家客户,Dell EMC预计很快也会进入这个区间。
在第三季度的财报公告中,思科并没有更新1100家客户这个数字。一份Stifel对思科VAR/经销商的调研发现,有16%的受访者认为HyperFlex在HCIA市场中处于最佳位置,而40%的受访者则认为Nutanix是领导者。有66%的受访者把HyperFlex售卖给现有的思科客户,而不是卖给新客户。
Rakers表示,有20%的服务器收入来自于面向公有云的售卖,在这方面思科并没有涉及,ODM和白盒服务器有大约40%的份额。
小结
总而言之,思科服务器在其整体收入中占比6%,这部分收入连续四个季度下滑。思科在整体市场中占比6.3%,但是在更大、增长中的机架服务器市场占比不足5%。思科在HCIA市场取得的进展是一个很好的开端,但是还远远落后于Nutanix和Dell。HPE通过收购SimpliVity正在成长为一个实力强大的竞争对手。
在我们看来,为了在服务器方面取得进展,思科需要全力进入机架服务器市场。但是有一个根本问题:目标是什么?是想成为领先的服务器提供商,赶超Dell和HPE?还是满足于不到10%的市场份额,向自己的客户群进行售卖,面对着来自Dell、HPE、各种中国厂商和ODM提供商的攻击?
如果思科想要成为领导者,那就需要在工程开发方面投入大量资金。这在总体收入下滑的情况下是一件困难的事情,况且服务器只占其业务收入的6%,而且还在裁员。
思科思科应该后退一步,深呼吸,决定退出服务器市场,也许把UCS服务器卖给联想。也许另一方面,思科可以尝试一些极端的做法,例如收购超微。
我们认为思科进入到服务器这个核心网络市场相邻的市场总是感觉不太对,然后进入存储这个服务器相邻市场,失败了。我们认为思科认为服务器市场前景受限,不足以进行所需的投资使其成为前四或者前五的服务器提供商。
展望未来,我们认为思科可能会调整产品线,重新承诺和下决心,但实际情况几乎不会改变。就思科的总收入来看,服务器既不是足够大的业务能随便丢掉,也不是一个很小的业务值得重金投资,也还没有到需要彻底修复的程度。他们现在陷入了一个困境,很可能会困在其中。
好文章,需要你的鼓励


Glean年收入突破3亿美元,削减AI成本成核心卖点
企业AI搜索公司Glean宣布年度经常性收入(ARR)达3亿美元,较15个月前的1亿美元增长三倍。尽管谷歌、微软、OpenAI等科技巨头纷纷入局企业AI搜索市场,Glean凭借"上下文图谱"技术深度理解企业业务需求,并帮助客户显著降低AI计算成本。该公司提供按用量计费和混合定价两种模式,客户涵盖Databricks、Reddit、Pinterest及三星等企业。Glean上轮融资后估值达72亿美元。

香港中文大学与MiniMax联手破解AI图像描述的“说多错多、说少漏多“困局
香港中文大学与MiniMax提出ClaimDiff-RL框架,将图像描述的AI训练从整体打分升级为逐条核查,有效解决了传统方式导致AI"少说保平安"的问题,同时在多项基准测试上超越Gemini-3-Pro-Preview。

蓝色起源“新格伦“火箭在佛罗里达测试中发生爆炸
杰夫·贝索斯旗下的蓝色起源公司在佛罗里达卡纳维拉尔角进行静态点火测试时,新格伦重型火箭发生爆炸。这是美国历史上最大规模的火箭爆炸之一,也是蓝色起源公司遭遇的最严重失败。所有人员安全,但该事故可能导致新格伦火箭项目长期暂停。此前该火箭已成功完成三次发射,并实现了助推器回收和重复使用。

NTU、HKU等多所顶校联手,让AI同时“多角度看片“——视频理解的并行探针革命
ParaVT是一个由南洋理工等多校联合提出的并行视频工具调用框架,通过让AI同时分析多段视频并引入PARA-GRPO算法解决训练中的格式崩溃与工具跳过问题,在六项长视频理解测试中平均提升约7.9%。
2017
05/19
18:00
分享
点赞

Glean年收入突破3亿美元,削减AI成本成核心卖点
蓝色起源"新格伦"火箭在佛罗里达测试中发生爆炸
智能体AI正在重塑企业架构与Token经济学
堪培拉理工学院如何借助技术革新重塑课堂教学体验
Gemma 4携手Arm:优化端侧AI,加速移动应用体验
制药公司与初创企业如何携手推动AI落地
《星球大战》导演盛赞生成式AI:电影制作的革命性工具
Salesforce借助Informatica布局企业级无头数据管理架构
几乎所有M5 MacBook Air配置现在都降价近200美元
大模型评测风向变了,Testin云测如何构建企业级AI质量标尺?
因民事养老金管理失误,英国政府拒绝向Capita授予5.63亿英镑合同
YouTube提升AI生成视频标签的显示效果
