
立足日本实施大动作,英特尔凭借“Chainer”AI代码项目向GPU开火

AI日活动于东京举行,现场还进行了一场真人版马里奥赛车竞赛。
不知道大家是否曾听说过“Chainer”这一用于创建神经网络的开源框架方案?
我个人直到昨天才有所耳闻,英特尔方面对此给予有力支持,使得此项目从母公司Preferred Networks的内部秘密成果真正转化为举世皆知的方案。
Chainer也确实由此才正式进入公众视野:这一诞生于2015年的项目于去年转向开源,尽管其GitHub代码库非常活跃,但却并没能引起业界的应有重视。
不过这种情况即使发生改变。英特尔公司决定将Chainer作为一种理想的AI工作负载开发途径,并以此为基础促进自家芯片的市场需求量。在双方的努力之下,Chainer将能够更为顺畅地同至强处理器进行协作,而不再像过去那样仅可对接英伟达GPU。英特尔与Preferred之间的合作关系意味着Chainer如今已经被正式纳入英特尔的技术架构,并转而由英特尔为该项目打造的GitHub代码库进行公布。
我们为什么有必要关于英特尔方面对Chainer的支持态度?
在纯技术层面看,双方应该能够建立起良好合作。Chainer CEO Toru Nishikawa昨天现身英特尔公司于东京举办的AI日活动,并通过一系列幻灯片演示表明谷歌的TensorFlow的图片净分类训练速度与其相比就像是儿童玩具。Nishikawa先生同时指出,Chainer最近已经被引入至Amazon.com的一项测试当中,用以训练机器人进行货品分捡。
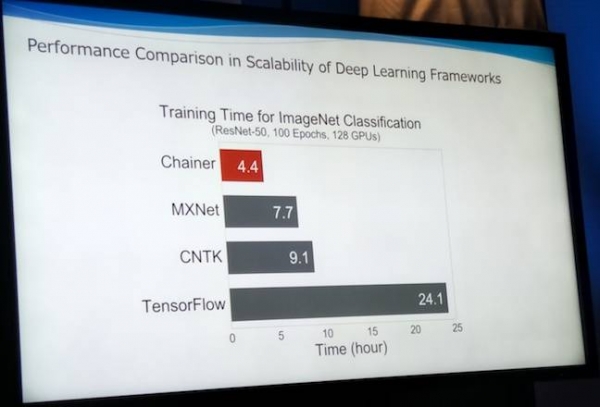
对于有意进军神经网络的朋友而言,对此视而不见显然相当不明智。
除此之外,Chainer的加盟亦显示出英特尔公司建立市场并证明自身在人工智能市场扮演领导者角色的勃勃雄心。毫无疑问,目前技术业界普遍认为这一领域正处于繁荣的黄金时期。
另外,必须承认这一市场目前正由GPU所主导。因此,英特尔公司希望能够建立起一整套产品组合,用以确保至强能够在AI领域作为支柱存在——而非被GPU抢了风头。
然而,英特尔对AI作出的定义仍然相当务实。Nervana公司前任CTO、现任英特尔AI部门负责人Amir Khosrowshahi更倾向于将AI描述为一种对于事件 进行密切观察以实现深度统计分析的方案,旨在帮助用户以令人满意的精度推断可能出现的各类结果。
现代硬件能够完成相关分析任务,并将收集到的庞大数据进行关联从而使分析结果具备现实意义,但在此背后需要强大的资源作为支持。专用硬件将加快整个执行流程,而这正是英特尔公司目前的主要思路,即通过构建及/或购买硬件并构建软件生态系统与之相匹配。
事实上,这样的状况早在虚拟化领域就曾经出现。当时英特尔公司曾在为其芯片提供扩展方案,从而确保其能够拥有出色的多虚拟机托管能力。芯片巨头亦曾引入Lustre与HDFS文件系统,旨在帮助运行有Lustre的高性能计算集群得以运行依赖于HDFS的Hadoop。英特尔公司在这一领域最终取得了成功:其投资于Hadoop供应商Cloudera,并帮助众多高性能计算客户利用英特尔芯片顺利完成了相关处理工作。另外,英特尔公司还针对消费者常用的视频转码工作负载进行CPU优化,意味着高清家庭录影内容将不必消耗一整晚才能渲染完成——这亦成为消费者们采购新电脑的重要理由之一。
英特尔目前正在AI领域采取同样的举措。收购现场可编程门阵列(简称FPGA)厂商Altera公司意味着英特尔能够利用其技术构建混合型至强处理器,从而提供集成化可编程能力,最终确保定制化版本能够在特定分析层面提供远超普通至强版本的速度优势。Altera公司目前正在致力于为FPGA开发代码,这意味着相关工作将由这批专家的嵌入式系统工程师负责进行——而非被强加给普通Java开发人员。
英特尔公司FPGA设计软件与知识产权营销与规划负责人Bernhard Friebe表示,英特尔方面正在为通用型AI任务开发代码库,并通过向公开发布并提供构建工具的方式帮助开发人员轻松编写出适用于FPGA的代码内容。
收购Nervana公司意味着英特尔将拥有专门面向AI领域的芯片方案,而这恰好能够满足大多数软件开发者的切实需求。
两家公司亦为英特尔带来了众多可潜在引入至强处理器的技术成果,这将最终使得至强这一服务器领域的主宰级品牌拥有更强大的AI类数据处理能力。
此类产品将于2017年晚些时候正式推出,届时“Lake Crest”一代至强处理器将加入面向AI工作负载的AI加速机制。而代号为Knights Crest的FPGA联协式Skylake至强处理器亦将于同年晚些时候出现。英特尔公司目前并未公布相关细节信息,但二者皆将采用专有的芯片间链接并立足于一套名为“Flexpoint”的新架构以提高其并行能力。作为早期产品,二者皆承诺提供10倍于当前的并发能力。到2020年,英特尔公司承诺将把AI模型的训练时长缩短到目前的百分之一。
不过其中的关键是向至强处理器当中添加AI功能,这意味着英特尔必须通过主流用户们所熟知的工具包保证开发平台的无缝化转移,即最终摆脱对GPU的高度依赖。而面向Chainer以及其它多个软件项目的大力投资亦证明,目前开发者们实际并不会将CPU作为AI开发的首选平台。
英特尔公司“加速器工作小组”总经理Barry Davis在接受采访时表示,英特尔方面将于2018年下半年推出“Knight’s Mill”,即面向AI进行优化的下一代至强Phi协处理器。关于该产品的细节信息尚不明确,但英特尔方面证实称其将能够对接高达400 GB内存容量,远超当前的CPU产品。
在至强家族全面进行AI优化之后,可观的市场占有率将令用户很难对其视而不见。以至强Phi与基于FPGA之至强版本为代表的各类特殊产品亦将运行在云端,意味着用户能够在无需承担前期资本支出的情况下对其进行试用。
随着AI相关芯片方案的快速发展成熟,Chainer亦将拥有约三年的英特尔硬件运行经验,这很可能进一步促成英特尔方面掌握更理想的技术支持能力。
虽然这并不代表我们在考虑进军AI领域时优先考虑英特尔生态系统,但将Chainer引入英特尔储备体系的举措还仅仅是芯片巨头的实际措施之一。除此之外,英特尔还将投入巨资进行技术收购、以开源方式为相关项目带来巨大推动力,同时为服务器制造商提供更多引导性政策。
结合这一切,英特尔将最终建立起一整套“供应商在考虑涉足AI”时所很难忽视的重要生态系统。
当然,市场绝不会静止不动而坐视英特尔逐步完成积累。但很明显,芯片巨头有信心在面对任何竞争对手时继续保持自身统治地位。
不过在这方面,英特尔公司也曾经折戟沉沙。英特尔曾经在移动领域亦占据领先地位,并一味坚持自身思路最终导致其几乎被ARM彻底挤出这一市场。
Barry Davis认为英特尔公司已经找到失败的原因:根据各历史版本来看,ARM方面一直希望从网络边缘起步,并最终渗透至数据中心之内。而在移动领域,英特尔公司则试图重复PC领域的成功途径。在英特尔公司的各位高管人士看来,ARM虽然在AI领域同样会带来一定威胁,但其在数据中心领域还未能成为一股重要力量,意味着其很难解决满足企业及开发人员之生态系统需求所带来的严峻挑战。
当然,出于英特尔公司的立场,这样的结论完全不会令人意外。要找到问题的真正答案,也许我们还需要立足于这套负责密切观察事件并进行深度统计分析的系统,了解其是否能够真正带来精度令人满意的推理结果。
好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

马萨诸塞大学的研究者们证明了:搜索引擎的“比较策略“在数学上优于传统方法
马萨诸塞大学从数学角度证明,MaxSim评分策略在理论能力上超越传统单向量内积方法,并提出Signed MaxSim扩展,显著改善否定查询性能。


新加坡国立大学与英伟达研究院联手打破视频生成的“非此即彼“困局:一个模型,两种能力,任意切换
新加坡国立大学与英伟达联合提出Flex-Forcing框架,通过时间帧和去噪步骤两个维度的灵活分块,将双向扩散和自回归视频生成统一到单一模型中,实现质量与效率的自由权衡。
2017
04/10
09:40
分享
点赞

“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
牙科诊所软件漏洞修复:患者医疗记录曾遭泄露
关键基础设施巨头Itron确认遭遇网络攻击
Vercel数据泄露范围扩大,黑客早于已知时间节点已入侵
苹果与博通签署300亿美元协议,共同生产美国本土无线芯片
摩托罗拉领投BRINC 1.25亿美元,推动紧急救援无人机大规模扩张
AI赋能芯片设计:前景广阔,疑问犹存
Arm今夏将推出自研芯片,Meta成首批客户
