
至顶AI实验室硬核评测|落定个人AI超算下一块“拼图” NVIDIA DGX Spark实现本地千亿级参数模型推理 原创
前几天,我们在开箱NVIDIA DGX Spark的文章中给出了一个论断,在如今大模型爆发的时代,每个人都应该拥有一台属于自己的AI超算。

从工程实践角度出发,云端算力虽然强大,但其短板同样明显。
具体而言,首先是网络问题。由于云端高度依赖网络传输,在交互过程中,如果有网络时延,最终将影响整体效率;接下来是数据问题,无论处理的是企业数据、个人隐私,还是尚未公开的业务素材,合规性和安全成本。紧接着是经济账,云端算力按时计费的模式或导致用户不断消耗资源,尤其是用户高频次使用模型时,难以保持稳定。
所以,对于NVIDIA DGX Spark这类桌面级超算而言,把算力与数据都留在身边,让开发与验证在本地形成闭环,往往才是效率、合规与成本三者的更优解。
硬件提供了强大的算力基础,而系统则赋予了这台机器真正的灵魂。
NVIDIA为NVIDIA DGX Spark定制了DGX OS,一款基于Ubuntu深度优化的系统。桌面预装的DGX Spark Resources类似工具箱,把NVIDIA面向不同场景的能力集中提供——从大模型推理到多模态训练,从代码生成到数据科学,都能通过对应的NIM微服务快速启用,真正做到了开箱即用。
对用户来说,直接的体验就是少走配置路,软硬一体的交付方式,可以让用户把注意力放在生产力上。
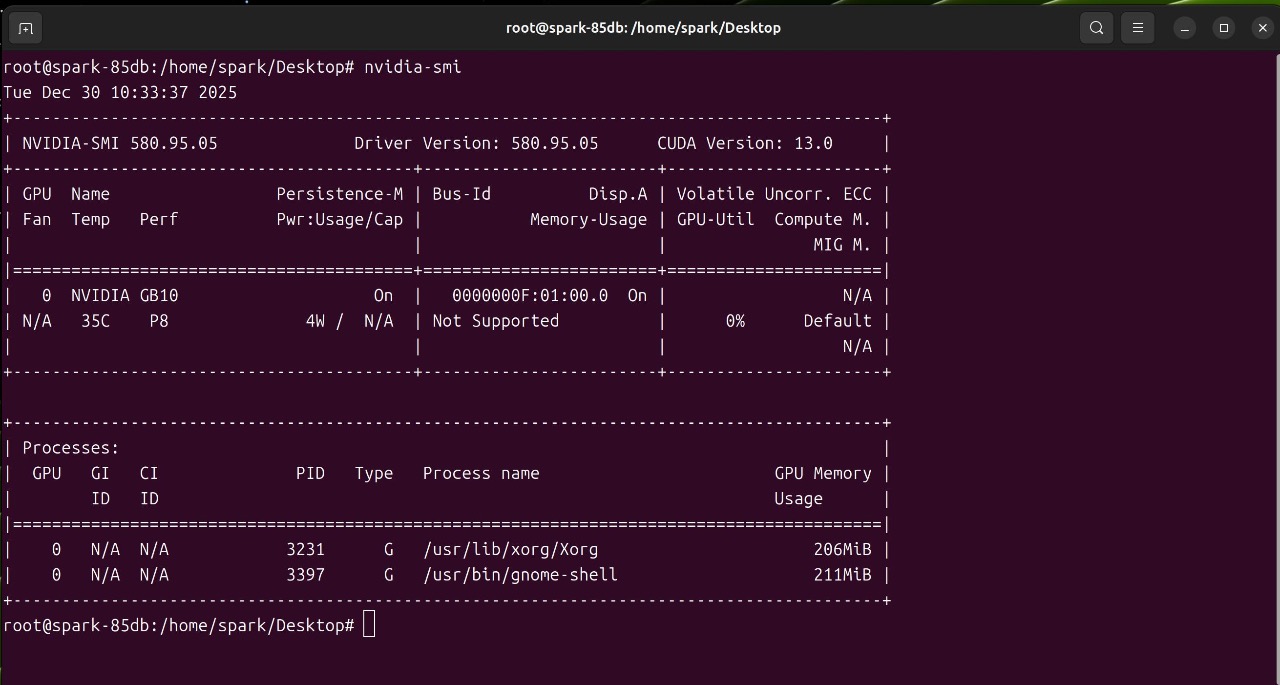
我们直接在DGX Spark Resources中选择了Isaac Sim,并在本地部署运行了这款基于NVIDIA Omniverse的机器人仿真平台,整体部署过程非常顺滑,仿真交互与场景加载展现出了极高的流畅度。Isaac Sim对硬件的要求较高且特殊。不仅需要Tensor Core支撑AI相关推理,也需要RT Core支撑光线追踪渲染;同时,物理仿真/解算也依赖其GPU计算能力(CUDA/PhysX路径)。
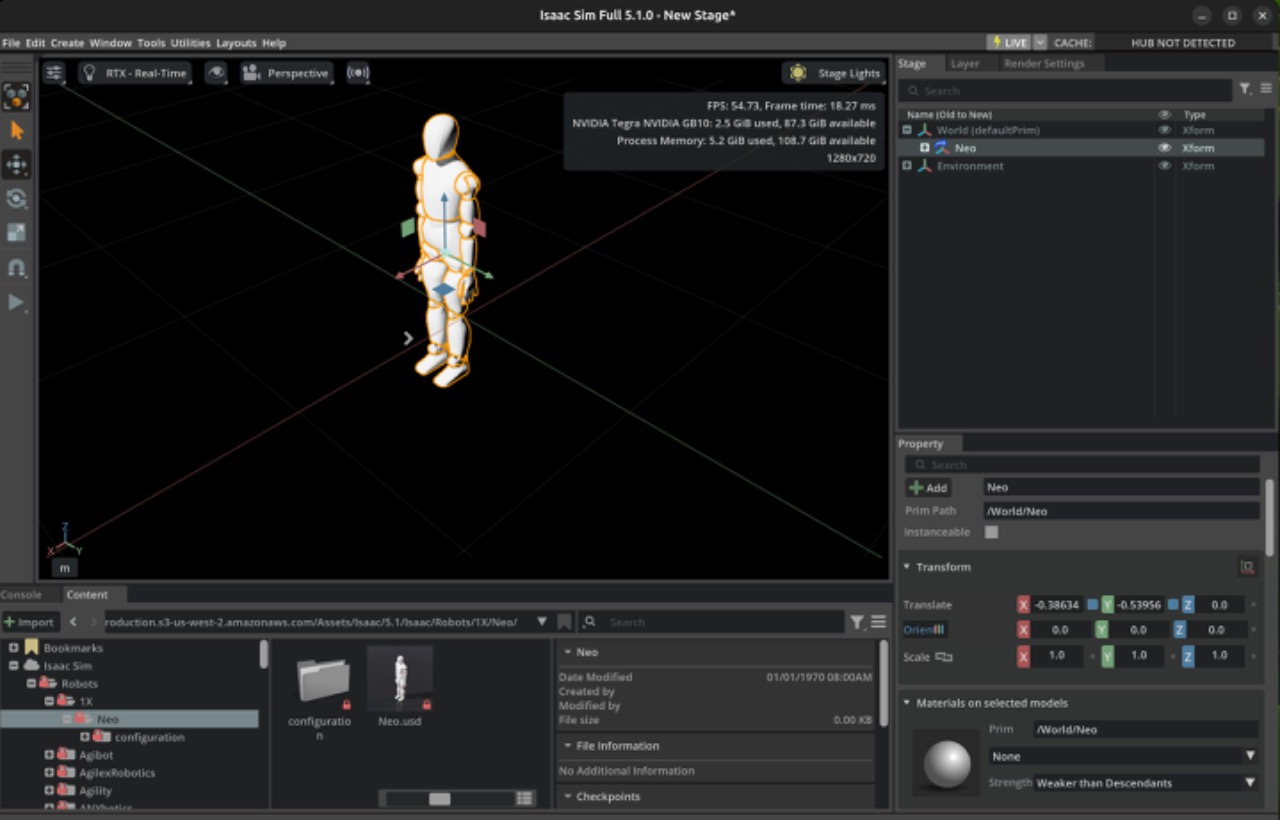
NVIDIA DGX Spark的流畅表现,验证了其高性能推理引擎的性能,更体现了系统层对“计算-图形-物理”混合模态负载的深度优化。这一软硬耦合的极致调教,也正是其实现真正“开箱即用”的坚实底座。
01 统一内存+片上协同 将“4路32B”本地推理拉入“稳态区间”
开箱即用解决的是部署门槛,能否在日常高频任务中提供稳定、可预测的吞吐与延迟,还需要通过实测给出答案。
为了测试NVIDIA DGX Spark在更贴近日常的常规应用场景表现,我们首先选择了当前开源社区活跃度极高的主流中等参数模型Qwen3-32B(320亿参数)。
在本地单一模型推理测试中,NVIDIA DGX Spark整次推理任务的总耗时为约60.97秒。其中,模型加载时长约3秒,这意味着在常驻模型或长时间运行场景下,启动的开销对整体体验影响极小。
在生成阶段,NVIDIA DGX Spark生成520token,耗时约60.69秒,对应的实际生成速率为8.57 tokens/s。这一数值意味着在本地部署的中等参数规模(32B)模型下,DGX Spark 的推理性能已经进入“稳态区间”,不会因短时波动而出现明显抖动。
从体验层面来看,8.57token/s的推理速度恰好处在“人类阅读与交互的舒适区”。无论是代码补全,还是实时对话式交互,这一速度都完全可用,交互延迟不会构成明显干扰。
![]()
在评估一台桌面级AI超算的真实能力时,单路推理的测试并不足完全说明问题,更关键的是其在多任务并行条件下的表现。毕竟,在实际工作中,一台本地超算往往同时承担多项任务。
于是,在NVIDIA DGX Spark上,我们进行了4个Qwen3-32B模型的本地并发推理测试。结果显示:模型平均加载时长约5.7秒;提示词阶段单路平均处理时长0.2775秒,对应约60.1 tokens/s的平均处理速率;在生成阶段,平均生成时长约62.6秒,生成速率平均稳定在7.5 tokens/s。
![]()
数据上看,在4个 Qwen3-32B模型持续生成文本的条件下,各项指标没有出现明显波动,整体推理过程节奏平稳,这也证明了NVIDIA DGX Spark在中等模型的本地并行推理场景中,能够提供稳定、持续且高度可预测的性能输出。
这一结果首先得益于其128GB LPDDR5x统一内存架构。在4并发场景中,32B参数规模模型的权重、上下文缓存与中间数据均可完整“常驻”于同一物理内存池,避免了多实例运行时常见的显存切分和数据搬运问题。配合256-bit接口与273 GB/s的内存带宽,系统能够在多路生成同时进行时,持续向GPU提供稳定的数据吞吐,这是保障生成速率的关键基础。
另一方面,GB10 Grace Blackwell Superchip(后文简称“GB10”)的片上协同设计放大了并发优势。20核的Grace CPU负责提示词预处理、请求调度与系统协同,而Blackwell架构GPU则专注于大规模矩阵计算。两者通过NVLink-C2C建立高带宽、低时延互连,使多路请求在进入GPU推理阶段时的数据交付成本显著降低,从而避免“CPU–GPU”数据交付在并发条件下成为瓶颈,继而让提示词响应能够维持稳定而高效的处理节奏。
生成阶段的稳定表现,也体现出第五代Tensor Core在并发推理中的多流、多批次计算中保持的高效算子执行密度。GPU能在同时处理多路推理负载时,算子执行与内存访问保持良好平衡,使性能曲线呈现出平滑的线性分布。
02 原生推理加速 让NVIDIA DGX Spark跑起千亿参数模型
32B的模型并不是“终点”。在真实应用中,随着模型逐步向更长上下文、更强推理能力演进,开发者同样关心的,是一台桌面级AI超算在更大参数规模下是否依然具备可用性与工程价值。
所以,我们加测了一个项目,将测试负载提升到了千亿参数级别,利用120B(1200亿)参数的GPT-oss进一步检验DGX Spark在大模型本地化推理场景中的能力边界。
![]()
从整体测试结果上看,模型加载时长为12秒,即便面对千亿级以上参数规模,启动开销依旧维持在极低水平,这使得大模型以常驻方式运行成为现实可行的选择。提示词输入74token,处理耗时32.06毫秒,这一阶段几乎不构成可感知的延迟。
真正拉开差距的,是生成阶段。本次测试共生成165token,耗时约4.66 秒,对应的实际生成速率达到35.41tokens/s。对于一款在本地运行的120B级模型而言,这已经不只是“可用”,而是足以支撑连续对话、复杂推理乃至交互式应用的实时响应。
整体来看,测试的结果不仅意味着DGX Spark能“装下”千亿级的模型,更能够在实际推理过程中提供高频、低延迟的输出能力。如果放在传统工作站上,这样的效果几乎难以实现。
传统工作站往往依赖系统内存进行“显存交换”,模型参数部分驻留在GPU显存,另一部分滞留在CPU内存中,推理过程中通过PCIe总线不断搬运数据。这种模式下,加载时间与推理延迟都会被显著放大。
而DGX Spark得益于其128GB的统一内存,可以将整个模型一次性完整加载进同一可寻址的内存空间,不需要任何形式的显存交换。这一点在两个关键指标上被明显放大——加载时间和推理速度。
值得注意的是,在不同参数规模的测试中,出现了颇具“反直觉”意味的现象。120B参数GPT-oss的推理速度为35tokens/s,显著快于32B参数Qwen3的8.57 tokens/s。
一般而言,模型参数规模越大,推理速度理应越慢。但这一结果,恰恰体现出Blackwell架构与GB10芯片的优势所在。
一方面,是对FP4(4-bit Floating Point)的原生支持与加速GPT-oss-120b使用MXFP4 量化(主要针对MoE权重),而Blackwell架构的Tensor Core原生支持FP4数据格式的计算指令与执行路径,使该精度推理在硬件层面可获得更高的执行吞吐,从而带来显著的推理加速效果。
另一方面,是MoE(混合专家)架构带来的潜在加成。在单次推理过程中,真正被激活并参与计算的参数量,事实上低于理论参数。当FP4精度下的高吞吐计算路径与MoE 的“按需激活”机制叠加时,参数规模与实际计算负载之间的解耦则被进一步放大。
这一原因,或许也预示着,硬件的迭代升级,需要与模型和推理范式同步演进,才能真正转化为可感知的性能跃迁。
而事实上,DGX Spark的意义之一,也正在于此。其实质性地打破了两个长期存在的经验桎梏。——一是“千亿参数模型必须上云”;二是“本地运行大规模参数模型须依赖多卡集群”。
03 跨越“基础生图”到“8K负载” NVIDIA DGX Spark“零降频”
当AI创作走向真实的生产应用场景,核心问题就已经不再是模型能否跑起来,而是不同模态的模型,能否被连续、稳定地串联进同一条“生产管线”。
文本、图像、视频、3D,跨越每个模态,算力形态、显存占用与带宽压力都会发生质变。所以,我们在NVIDIA DGX Spark上搭建并运行完整的多模态创作蓝图(BluePrint)——以FLUX.1为起点完成文本到1080p图像生成,经由超分模型将分辨率暴力拉升至8K,随后接入阿里通义Wan 2.1实现图生视频,再利用腾讯混元3D模型完成二维到三维的维度升级,最终落地Blender进行工业级精修。
从FLUX文生图开始,我们选择在ComfyUI中直接加载标准的FLUX工作流,通过模型加载、提示词输入、分辨率设定、采样器选择、解码与输出的步骤,完整复现普通创作者最常见的生图路径。
运行工作流,生成在1080P分辨率图片时,从设备内存占用看,NVIDIA DGX Spark的显存占用大约维持在一半左右,负载曲线平稳,没有明显的峰值抖动。单张图片生成时间为1分27秒。在FLUX当前的模型体量和计算复杂度下,这已经是相当“顺滑”的体验,更重要的是,全程没有出现任何需要人为干预的异常状态。
![]()
真正的考验来自8K分辨率。
8K(7680×4320)并不是简单的分辨率翻倍,其像素规模会直接跃升至4K分辨率的四倍,对显存能力、带宽,以及硬件能力提出了同步、全面的压力。
在不改变工作流结构的前提下,直接切换至8K超分工作流后,NVIDIA DGX Spark在1分30秒就完成了8K图像的生成。在放大查看细节时可以清晰看到,无论是人物皮肤纹理,还是复杂材质的层次过渡,都没有出现糊边、断层或噪点堆积。
![]()
从架构层面回看,NVIDIA DGX Spark在8K生图上取得优质表现的原因,在于其大容量、高带宽的LPDDR5X统一内存,使得Diffusion在超大分辨率下产生的中间特征图得以完整驻留。
同时,其GB10芯片的Blackwell架构针对Diffusion与Transformer路径有深度优化的Transformer Engine,通过混合精度与算子级调度优化,使Attention在超大分辨率场景下的实际性能曲线显著趋于平滑,避免了传统架构中随分辨率提升而出现的非线性性能坍塌。
04 时空“双重奏” NVIDIA DGX Spark让视频不崩、3D不破
完成图片生成后,下一步就是让画面动起来。
在这一阶段,利用阿里通义万相Wan2.2图生视频模型,直接将前一阶段生成的8K静态图作为输入,验证其在高信息密度素材下的时序生成稳定性。整体工作流依然保持常规配置,并将输出分辨率设定为1280×720,以模拟现实创作中较为常见的视频生成需求。
与静态图像不同,这一阶段的计算模式已经从单帧扩散,转变为多帧时序Transformer 与Diffusion叠加的混合负载。在实测过程中可以看到,NVIDIA DGX Spark的显存占用始终维持在高度可控的区间内,没有出现视频生成模型中常见的“前期平稳、后期突刺”的负载特征。最终完整生成耗时8分40秒。
从结果来看,生成视频的动作衔接自然,镜头运动连续平滑,没有明显的帧间结构性失真。这种稳定性,取决于NVIDIA DGX Spark在长时间连续推理过程中的带宽一致性与算子调度能力。
![]()
从架构视角看,由于Wan2.2作为引入了复杂时空注意力机制(Spatio-Temporal Attention)的混合负载,本质上是对显存热稳定性与持续带宽输出能力要求较高。在接近9分钟的持续高负载运行中,始终保持“零降频”的状态,同时显存占用曲线平滑。这也意味着NVIDIA DGX Spark在处理长序列KV Cache时具备充足的热设计功耗(TDP)冗余度。
这一结果也进一步印证,NVIDIA DGX Spark能够成功将算力转化为生产环境下可持续输出的有效算力,从而避免因硬件热节流(Thermal Throttling)导致的帧间时序一致性崩塌——这正是多模态任务中容易被忽视但却“致命”的稳定性底线。
如果说图生视频是负载升级,那2D图像3D化则是维度跃迁。
这一阶段,利用NVIDIA DGX Spark运行腾讯混元3D 2.1模型,直接将已有图片3D化。实测结果显示,NVIDIA DGX Spark用时53秒完成完整的图片3D化生成流程。
对生成的3D化模型进行预览时,从结构完整性来看,3D模型没有出现大面积破面或明显的比例失衡,整体几何关系保持稳定。
![]()
从推理特性上看,这类图像3D化呈现出不同的负载形态。计算密度较高,但持续时间相对较短,这对GPU的瞬时吞吐能力、内存访问效率,以及算子调度响应速度都非常敏感。
从工程角度看,3D建模本质上是围绕瞬时算力释放能力与内存系统协同效率展开的“闪电战”。模型需要在多视角Diffusion推理与稀疏几何重建(Sparse Geometry Reconstruction) 等不同计算阶段之间频繁切换。而NVIDIA DGX Spark能在53 秒内完成该过程,则在于其本身高带宽内存支持下,对算子调度、缓存命中与计算并行性的整体优化,有效降低了阶段切换带来的隐性开销。
这种“干脆”的体验,意味着NVIDIA DGX Spark不仅擅长承载长序列、高吞吐的持续负载,在面对计算密度极高、对调度与内存系统高度敏感的“脉冲式推理任务”时,其执行效率同样能够保持在高度可预测的工业级水准。
05 写在最后
在本地推理测试中,NVIDIA DGX Spark的128GB统一内存与Blackwell架构FP4加速的“组合技”之下,让开发者可以在桌面尺度上,以35 tokens/s 的速度流畅运行千亿级别的开源模型。这种体验,曾经只存在于数据中心环境。
这背后,或许也是NVIDIA在Post-Training时代将数据中心级推理能力,系统性地延伸到个人计算平台之上的深刻布局。
从多模态创作蓝图(BluePrint)结果上看,NVIDIA DGX Spark的核心优势,在于多分级的BluePrint能够在一台桌面级设备上稳定运行。其GB10的Blackwell架构针对Diffusion与Transformer的硬件级加速,也使显存容量、算力密度与调度效率达成了良好平衡。这对于AI艺术家、游戏开发者、视频创作者、3D设计师等从业者而言,意味着他们可以在不同模态间频繁切换,无需分心管理算力。
NVIDIA DGX Spark的发售也预示着“云端算力本地化”的最后一块拼图基本落定。通过高能效比与统一内存体系,有效打破了以往传统工作站显存碎片化导致的“算力孤岛”,将分散在集群中的异构计算负载无缝折叠到一台桌面设备中,实现了全链路推理对云端 I/O 延迟的独立性。这一优势,也为创作者带来了真正的“计算主权”。
从生产力视角审视,NVIDIA DGX Spark的推出,也意味着AI生产力从“租赁制”向“内生化”迁移的拐点。
一方面,其彻底消弭了云端不可避免的网络抖动与TTFT(首字延迟),让交互进入了真正的“零感”时代。NVIDIA DGX Spark毫秒级的响应,决定了AI还能是与用户思维同频、甚至预判意图的实时Copilot。
更关键的变革在于“Agent 经济学”的逻辑重构。Agentic AI的演进之下,由无数Agent 组成的自主循环(Loop),需要在智能系统内部进行“推理-反思-搜索-修正”的上百次迭代。在云端上,这是价格昂贵的Token;而在 DGX Spark上,这是固定成本下的强大算力。128GB的统一内存为超长Context Window(上下文窗口)和庞大的本地知识库(RAG)提供了物理载体,让开发者可以零边际成本地跑通复杂的思维链(CoT),在本地建立起自动化的生产闭环。
另外,真正的专业壁垒往往隐藏在私密数据中,云端模型永远通用,而个人超算允许用户在本地利用LoRA等技术对千亿级参数模型进行深度微调。用户可以让模型完全适应自有的代码规范、画风、文法,打造真正懂人、且完全忠诚于个人的电子替身。
或许,NVIDIA DGX Spark的推出,也是一种新的生产资料形态的转化,其让个人用户首次在本地掌握接近数据中心级别的AI能力,能把“想法”稳定、高效地转化为“可交付成果”。
而在这个能够本地掌握AI生产力的拐点之上,每个人,都应该拥有一台属于自己的AI超算。
来源:至顶网计算频道
好文章,需要你的鼓励


Cyera获得4亿美元融资专攻AI数据安全,估值达90亿美元
人工智能和数据安全公司Cyera宣布完成4亿美元后期融资,估值达90亿美元。此轮F轮融资由贝莱德领投,距离上次融资仅6个月。随着95%的美国企业使用生成式AI,AI应用快速普及带来新的安全挑战。Cyera将数据安全态势管理、数据丢失防护和身份管理整合为单一平台,今年推出AI Guardian扩展AI安全功能。

上海AI实验室研究者想出妙招:让AI像优秀学生一样高效思考,告别“想太多“毛病
上海AI实验室开发RePro训练方法,通过将AI推理过程类比为优化问题,教会AI避免过度思考。该方法通过评估推理步骤的进步幅度和稳定性,显著提升了模型在数学、科学和编程任务上的表现,准确率提升5-6个百分点,同时大幅减少无效推理,为高效AI系统发展提供新思路。

SAP推出全新AI功能助力零售业数字化转型
SAP在2026年全国零售联盟大展上发布了一系列新的人工智能功能,将规划、运营、履约和商务更紧密地集成到其零售软件组合中。这些更新旨在帮助零售商管理日益复杂的运营,应对客户参与向AI驱动发现和自动化决策的转变。新功能涵盖数据分析、商品销售、促销、客户参与和订单管理等领域,大部分功能计划在2026年上半年推出。

MIT团队让机器人终于不再“卡顿“:一种让机器人像人一样流畅反应的突破性技术
MIT团队开发的VLASH技术首次解决了机器人动作断续、反应迟缓的根本问题。通过"未来状态感知"让机器人边执行边思考,实现了最高2.03倍的速度提升和17.4倍的反应延迟改善,成功展示了机器人打乒乓球等高难度任务,为机器人在动态环境中的应用开辟了新可能性。
2026
01/08
10:45
分享
点赞

谷歌将Gemini AI功能推送至Gmail,用户可选择关闭
AI竞赛点燃欧洲数据中心债券市场热潮
IBM API Connect关键漏洞可导致身份验证绕过
CES 2026智能戒指新品:Pebble Index 01记录想法不追踪健康
AI聊天机器人让人上瘾的隐秘手段揭秘
AI将在2026年重塑网络安全策略
CES主题演讲分析:智能体AI如何为现实世界影响奠定基础
Snowflake收购Observe以增强其可观测性能力
三星Galaxy Tab A9 Plus限时降价70美元
Disney+将在美国推出竖屏视频功能
美国增长最快的五大AI职位出炉:LinkedIn数据揭示就业新风口
英伟达授权Groq推理芯片技术并聘用其领导团队
