
CES 2026 | AMD扩张“边缘统治力” “芯片级异构”塑造汽车、工业边缘应用“新法则” 原创
如果回看几年前的边缘AI形态,会发现一个明显的特征——负载高度单一。
无论是安防监控、工业质检,还是交通识别,边缘侧AI的主流工作负载几乎全部围绕计算机视觉展开。边缘智能以CNN为主,数据流稳定,推理路径固定,对实时性的要求也相对可控。在这一范式下,约10 TOPS级别的NPU峰值算力,已经足以覆盖大多数工程需求。
但这一范式模型,在这两年来开始迅速发生变化......
01 算力向左,功耗向右:异构堆叠走向SoC内协同
变化的根源,在于边缘设备承担的计算职责发生了根本变化。一方面,LLM通过剪枝、蒸馏与量化,逐步脱离云端依赖,开始在端侧承担语音理解、语义控制和生成式推理任务;另一方面,计算机视觉模型本身也在向Transformer架构迁移,感知任务从“识别”演进为“理解”。
结果是,边缘设备不再运行孤立的AI,而是同时运行一组强耦合的模型系统。
而在这一负载结构下,算力需求的增长便不再是线性的。即便单个模型已经过充分压缩,多模型并行带来的吞吐需求、调度复杂度和内存访问压力,仍然会迅速推高系统的算力门槛。实践中,要在端侧维持可接受的交互延迟与稳定性,NPU的有效算力需求被逐渐推高。
如果算力问题只是“算得不够快”,事情反而简单。但边缘计算的现实约束,恰恰来自物理世界。
在工业控制柜、车载仪表台、医疗影像终端等典型边缘应用场景中,散热空间、供电能力和结构尺寸长期保持稳定。出于对可靠性、噪声和维护成本的考虑,被动散热(Fanless)设计仍然是主流工程前提。这意味着,嵌入式处理器的热设计功耗(TDP)被严格限制,避免引发系统级设计失控。
于是,一个越来越尖锐的矛盾出现了:算力需求呈非线性增长,而功耗预算几乎原地踏步。
过去几年中,行业应对这一矛盾的常见方式是用异构的方式进行板级堆叠——CPU+独立GPU+NPU/FPGA/MCU。
尽管该方案在功能上成立,但在工程实践中,功耗与散热被切割、跨芯片通信延迟不可控、BOM成本与PCB面积持续膨胀。更重要的是,当系统开始承载混合负载(如实时控制与AI推理并存)时,跨芯片的不确定性会直接放大为系统风险。
在这一背景下,堆叠“加速”显然不再是持续的工程路径。边缘计算逐渐走向新的解法——在单一SoC内完成算力整合,并通过异构协同而非板级拼装来对抗功耗约束。
02 AMD P100/X100 以“芯片级异构”塑造边缘AI工程“基线”
在CES 2026上,AMD推出的AMD锐龙AI嵌入式 P100系列处理器(简称“ P100”系列),正是围绕这一工程痛点展开回应。AMD的答案是——“芯片级异构”。P100系列不仅追求性能指标的处理器,更是针对空间受限、功耗受限系统高度优化的异构SoC。

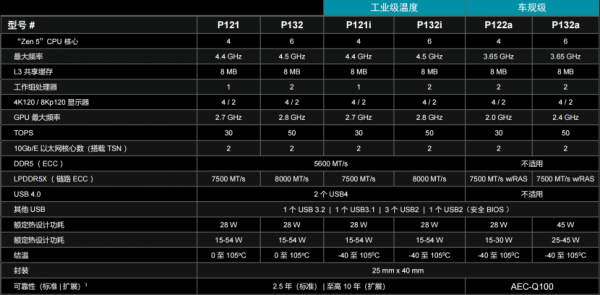
从架构层面看,P100系列基于4nm工艺节点,对Zen 5 CPU、RDNA 3.5 GPU与XDNA 2 NPU三大核心架构进行了精细的能效平衡。
与消费级市场通过拉高频率获取性能不同,嵌入式场景下的首要任务是长期稳定运行。所以P100系列配置了4~6个Zen 5核心,其设计取向围绕能效与确定性展开。相较于上一代产品,Zen 5带来的是IPC(每时钟周期指令数)的提升,多线程与单线程性能提升至高2 倍,用于安全控制和应用服务,更关键的是在产品线上完整保留了AVX-512指令集。
从系统设计角度看,这为P100系列提供了一层可靠的“算力兜底”——当NPU 专注于大模型推理时,CPU仍然能够稳定承担实时控制与传统算法负载,而不引入额外的硬件复杂度。
如果说CPU 构成系统的逻辑骨架,那么GPU则决定了边缘设备的交互能力。P100系列集成的RDNA 3.5架构GPU,配备2个WGP(工作组处理器),整体渲染速度较前代提升约35%。

这一性能提升的价值体现在系统整合能力上。P100系列的GPU不仅承担图形渲染任务,还同时覆盖通用计算(GPGPU)与多传感器数据处理需求。
真正使P100系列与前代边缘处理器拉开代际差距的,是其集成的XDNA 2架构NPU。
P100系列的NPU性能对应峰值算力达到50TOPS。事实上,10TOPS级别算力下,边缘设备通常只能运行轻量化CNN 模型,而50TOPS 的算力水位,使得在端侧可以部署基于Transformer架构的模型,包括视觉Transformer以及轻量化的语言模型。
更重要的是,XDNA 2并非沿用传统冯·诺依曼架构,而是采用空间数据流(Spatial Dataflow)设计。通过在片上完成数据的就近计算,显著减少了推理过程中数据在存储与计算单元之间的搬运,从而在功耗受限环境中获得更高的能效比。
值得注意的是,P100系列并非AMD在边缘AI 计算上的性能终点,而是其新一代边缘计算设备芯片的工程基线。在同一套芯片级异构设计下,AMD同步规划了面向更高自主性需求的锐龙AI嵌入式X100系列处理器(简称“X100系列”)。

X100系列的目标场景更加偏向“自主系统”,在该类系统中,AI可深度介入从环境感知、模型推理到行为决策的完整闭环。这意味着更复杂的模型组合、更长时间的持续推理,以及对系统级算力调度与能效控制提出更高要求。
AMD将X100系列定位为从个人级智能节点向完整机器学习系统演进的关键承载平台,其价值在于在功耗与体积约束依旧存在的前提下,为机器人、协作系统和高自主边缘设备提供可扩展、可复用的软件与硬件演进路径。
从P100系列到X100系列,AMD实际上是在边缘场景下逐渐构建出连续的算力谱系,也为后续系统确定性与混合关键性负载的工程价值奠定了前提。
03一芯多用,软硬解耦:加快座舱交互进阶 工业智造升级
如果说算力决定了边缘智能系统“能跑多快”,那么确定性则是系统“能否长期可靠运行”的关键。
在工业与汽车等高可靠需求场景中,偶尔的性能波动尚可接受,但不可预测的延迟则会导致系统级失效。正因如此,P100系列在架构设计之初,便将“确定性”提升至与“性能”同等重要的位置。这一取向,集中体现在其对混合关键性(Mixed-Criticality)负载的系统级支持能力上。
P100系列在硬件层面的确定性体现在TSN(Time-Sensitive Networking,时间敏感网络)与片上互联方面。
在连接性设计上,P100系列原生集成了支持 TSN的10GbE 以太网控制器。对于工业自动化场景而言,TSN 是打通OT(操作技术)与IT(信息技术)之间鸿沟的关键基础设施。
在具体典型场景下,工业机器人可以利用P100系列完成两类任务:一方面向上位系统或云端回传高分辨率质检视频(高带宽、低实时性要求),另一方面接受来自PLC的运动控制指令(低带宽、微秒级实时性要求)。
其实,在传统以太网环境下,视频流极易挤占带宽,进而影响控制指令的时序稳定性,造成运动抖动甚至失控。而P100集成的TSN 控制器,可以在硬件层面对不同数据流进行精确定义与调度,确保控制指令始终拥有最高优先级。无论网络负载如何变化,关键控制数据的传输延迟都被约束在确定的时间窗口内,从根本上消除了“偶发抖动”的工程隐患。
在芯片内部,Infinity Fabric承担高速互联的角色,更是各类工作负载的时序协调者。其设计可确保当GPU全速渲染3D 界面或处理多路视频流时,不会因总线争抢而“饿死”CPU 上的实时控制任务,从片上层面维持系统的时间确定性。
硬件奠定了基础,但混合关键性系统真正的复杂性,往往出现在软件层面。P100系列软件层面的隔离体现在虚拟化与分区式的系统架构。
事实上,随着AI能力不断向边缘侧迁移,系统同时承载AI推理、复杂UI与实时控制已成为常态,而这些工作负载在实时性与安全性上的要求截然不同。AMD 给出的工程解法,是基于硬件辅助虚拟化的系统分区设计。P100系列支持行业主流的Hypervisor,使开发者能够在同一颗SoC上并行运行多个操作系统实例。

在实际工程中,这类系统通常采用明确的分区式软件架构:RTOS 或实时Linux 分区,专职运行电机控制、运动控制以及功能安全相关逻辑,对中断响应时间、任务调度抖动和最坏时延(Worst-Case Latency)有明确上限要求.
通用操作系统分区(如Android 或Ubuntu)则承担 UI、人机交互与AI推理等非实时负载,更侧重算力规模与软件生态的完整性。
这一分工通过SoC的硬件资源划分机制(CPU核心绑定、内存区域划分、设备直通或受控访问)实现资源隔离。由此,通用OS 分区中的应用异常、进程崩溃,便不会破坏实时分区中控制回路的时序确定性。
对于汽车和工业系统而言,这种可验证的隔离与确定性是开展功能安全分析的基础条件,也成为助力应用企业通过ISO 26262、IEC 61508等安全标准的工程前提之一。
技术参数之下,最终也须转化为可感知的场景价值。围绕 P100系列的架构特性,AMD将其重点应用方向聚焦于两个正在经历结构性变革的领域——下一代数字座舱与工业自动化场景。
随着汽车电子架构正从分布式ECU向中央计算平台演进。当前不少智能座舱仍停留在“屏幕数量竞赛”的阶段,而AMD给出的判断是:未来竞争的核心,将是沉浸式交互体验与AI驱动的主动服务能力。
在 P100系列(车规级型号P132a)的支撑下,数字座舱的功能边界被显著拓展。
视觉层面上,P132a的RDNA3.5GPU可实时渲染3D 仪表盘与复杂AR 航界面,支持4K~8K分辨率输出,保证多屏环境下的一致性与流畅度。
交互层面,其XDNA 2 NPU使座舱具备运行本地语言模型的能力,在无网络环境下依然能够实现低延迟的自然语言理解与语义控制。
安全层面,P132a利用Zen 5 CPU与NPU的视觉分析能力,让系统可实时运行驾驶员监控(DMS)算法,对疲劳与分心状态进行本地识别,避免隐私数据外传。

P100系列不仅支持 Android Automotive,也兼容多种私有化车载操作系统,为Tier1供应商根据OEM 差异化需求进行定制预留了充足空间。
在工业现场中,P100系列(工业级型号P132i)承担者“超级控制器”的角色。传统工业机柜中,IPC、PLC与视觉控制器往往各司其职、相互分离,而P132i的目标,是将这些功能收敛至单一平台。
在控制层,P132i的多核Zen 5配合实时Linux、RTOS,能够胜任高频PLC 控制逻辑;
感知层上,P132i以50 TOPS的 NPU,实时运行复杂缺陷检测或异常识别模型,实现毫秒级质量判定;
在可视化层:P132i的GPU支持工控屏实时渲染设备的3D 数字孪生模型,提升运维直观性。

04 从ROCm开源工具链到十年供应承诺,AMD构建边缘生态闭环
在边缘场景下,硬件决定系统能力的下限,而软件生态决定平台的上限。对于工程技术团队而言,更换计算平台的最大阻力,往往并非硬件性能,而是软件迁移与维护成本。
这也是AMD在P100系列在软件策略中,反复强调“开源”的原因。与封闭式的AI加速方案不同,P100系列全面支持 Yocto Project、Ubuntu等主流嵌入式Linux发行版,同时兼容ROS 2等机器人生态。在AI工具链层面,ROCm(GPU)与 Ryzen AI Software(NPU)均对/ PyTorch、TensorFlow、ONNX等主流框架提供支持。
这意味着,模型可以在云端或数据中心完成训练,再通过AMD 提供的量化与编译工具部署至边缘侧,最大限度降低重复开发成本。
此外,由于边缘设备对生命周期的要求,远高于消费电子。
所以,AMD承诺为P100系列提供长达10年的产品生命周期支持,并确保 24×7连续运行的可靠性。配合BGA封装与工业级规格,这一策略构成了P100 能够进入严苛工业与车规场景的关键保障。

据了解,目前P100系列的文档、工具及芯片、参考板的样片AMD均已提供,芯片预计2026 年第二季度量产,参考板计划2026 年下半年量产。
来源:至顶网计算频道
好文章,需要你的鼓励


超越能源使用:数据中心可持续运营策略
随着AI广泛应用推动数据中心建设热潮,运营商面临可持续发展挑战。2024年底美国已建成或批准1240个数据中心,能耗激增引发争议。除能源问题外,服务器和GPU更新换代产生的电子废物同样严重。通过采用模块化可修复系统、AI驱动资产跟踪、标准化数据清理技术以及与认证ITAD合作伙伴合作,数据中心可实现循环经济模式,在确保数据安全的同时减少环境影响。

剑桥大学突破性研究:如何让AI在对话中学会真正的自信判断
剑桥大学研究团队首次系统探索AI在多轮对话中的信心判断问题。研究发现当前AI系统在评估自己答案可靠性方面存在严重缺陷,容易被对话长度而非信息质量误导。团队提出P(SUFFICIENT)等新方法,但整体问题仍待解决。该研究为AI在医疗、法律等关键领域的安全应用提供重要指导,强调了开发更可信AI系统的紧迫性。

2026年超大规模数据中心运营商发展前瞻:全球最大数据中心运营商的未来走向
超大规模云数据中心是数字经济的支柱,2026年将继续保持核心地位。AWS、微软、谷歌、Meta、甲骨文和阿里巴巴等主要运营商正积极扩张以满足AI和云服务需求激增,预计2026年资本支出将超过6000亿美元。然而增长受到电力供应、设备交付和当地阻力制约。截至2025年末,全球运营中的超大规模数据中心达1297个,总容量预计在12个季度内翻倍。

威斯康星大学研究团队破解洪水监测难题:AI模型终于学会了“眼观六路“
威斯康星大学研究团队开发出Prithvi-CAFE洪水监测系统,通过"双视觉协作"机制解决了AI地理基础模型在洪水识别上的局限性。该系统巧妙融合全局理解和局部细节能力,在国际标准数据集上创造最佳成绩,参数效率提升93%,为全球洪水预警和防灾减灾提供了更准确可靠的技术方案。
2026
01/06
17:15
分享
点赞

Littelfuse推出适用于电动汽车电池、电机和安全系统的汽车级电流传感器
CES 2026 | 机器人开发的“ChatGPT时刻”已到 老黄定调“物理AI”的路线图
超越能源使用:数据中心可持续运营策略
2026年超大规模数据中心运营商发展前瞻:全球最大数据中心运营商的未来走向
TOTOLINK EX200存在未修复固件漏洞可被完全远程接管
Ring推出Fire Watch功能,利用家庭摄像头追踪野火威胁
Snowflake与Google Gemini深度整合,全云环境支持数据分析
联想和摩托罗拉推出自有设备端AI助手
机器海龟游向环保使命:仿生技术守护珊瑚礁
CES 2026最酷笔记本电脑:可拆卸设计成为新趋势
AMD 在 CES 2026 发布新款锐龙处理器、Ryzen AI 及 AMD ROCm,全面扩展其在客户端、图形和软件领域的 AI 领先地位
AMD发布Instinct GPU新品挑战英伟达数据中心霸主地位
