
CES 2026 | NVIDIA新风向: Rubin平台面市 ,系统级“AI工厂”成型,物理AI加速落地 原创
“模型更大、数据更多、算力更强”这套线性扩展逻辑,在GPT-3到GPT-4 阶段被反复验证,也直接催生了以GPU 为核心的全球算力竞赛。
但进入2025年后,行业逐渐意识到一个现实问题:算力已不再是通过简单“堆芯片”就能持续放大的变量。万亿参数模型、MoE 架构、Agentic AI、物理 AI 的快速演进,带来的不只是FLOPS 需求的指数级增长,更引发了通信、内存、调度、能耗与系统协同层面的失衡。
一方面,MoE通过稀疏激活显著降低了单次计算量,却将性能瓶颈推向了跨设备通信;另一方面,长上下文、持续对话以及多 Agent 并行协作逐渐成为常态,使KV Cache从推理阶段的优化项,演变为决定推理成本、并发能力与系统可扩展性的关键系统资源。
黄仁勋在CES 2026上近两小时主题演讲中,释放出一个信号:AI的核心瓶颈,正在从计算单元本身,转移到系统层面。

而此次,NVIDIA所展示的一系列技术,也是一整套围绕“下一代AI工厂如何落地”的答案。
01 Rubin平台:“六芯一体”突破算力天花板
Rubin GPU,专门针对MoE(Mixture-of-Experts,混合专家模型)进行了物理层面的升级。
事实上,MoE模型(如GPT-4、Mixtral)的核心逻辑是,模型由成百上千个“专家”网络组成,每处理一个Token,只需要激活其中的几个专家。这大大降低了计算量,但却带来了副作用——通信墙。因为不同的专家分布在不同的GPU甚至不同的机柜上,数据交换极其频繁。

截取自NVIDIA官网
而Rubin GPU的两个核心特性,正是为了解决这一问题:
一方面, Rubin原生支持4位浮点(FP4)计算,搭载第三代Transformer引擎。
或许许多人可能会质疑,FP4是否会降低模型“智商”?但NVIDIA的黑科技就在于——“自适应压缩”。Transformer引擎会在每一层计算前,动态判断权重的敏感度,对不敏感的层使用FP4,对敏感层保留更高精度。
试想,当你向一个拥有10万亿参数的Agent询问复杂的问题时,模型需要在几秒钟内生成数千个Token的思维链(CoT)。FP4让显存能装下更大的模型上下文,同时也能让计算单元快速吐字。
另一方面是MoE的并发优化。Rubin GPU内部的调度器针对稀疏计算进行了重写。其能够更智能地预测下一个Token需要哪个专家,并提前预取数据,掩盖通信延迟。
Rubin平台采用软硬件极致协同设计,将推理token成本最多降低至 NVIDIA Blackwell 平台的十分之一,在MoE模型训练中使用的GPU数量仅为Blackwell平台的四分之一。
这是一个恐怖的数字。对于OpenAI、Anthropic等客户企业来说,这意味着同样的资本支出下,他们的服务能力可以大幅提升;或者说,也许他们能把以前亏本的生意(如免费开放GPT-5级别的推理)变成盈利的生意。
此外,黄仁勋在CES 2026上更强调了一个重点“Rubin is fully compatible with Blackwell”(Rubin完全兼容Blackwell)。
02 Vera CPU:为Agentic AI构建系统协同
当Rubin GPU将MoE模型的推理速度推向更极致时,传统计算机架构中的“短板效应”便暴露无遗——如果数据喂给GPU的速度跟不上GPU处理的速度,那么再强大的张量核心也只能在等待中空转。为了彻底释放Rubin的潜能,NVIDIA引出另一块关键“拼图”——Vera CPU。

截取自NVIDIA官网
在半导体行业,摩尔定律的边际效应逐年递减。晶体管密度的提升越来越昂贵,单纯靠制程红利已经无法支撑AI模型每年大规模的参数增长。
面对这一物理铁律,NVIDIA在Rubin平台上给出的答案是:高效的协同设计。
回看过去,在传统的x86架构时代,CPU是英特尔的,GPU是NVIDIA的,网卡是博通的,大家在PCIe总线上排队交“过路费”。但在Rubin架构里,这种方式被彻底废除,取而代之的是NVIDIA高度集中的“单一系统”。
很多人会问,NVIDIA为什么要做CPU?Grace还不够吗?答案在于Agentic AI(代理AI)的计算特征上。与传统的训练任务不同,Agentic AI在推理过程中涉及大量的逻辑判断、工具调用和非矩阵运算。传统的x86 CPU虽然通用性强,但在面对Rubin GPU的大规模吞吐量下,由于内存带宽和互连延迟的限制,往往会成为“喂不饱GPU”的瓶颈。
所以也不难发现,Vera CPU并非为了运行Windows或通用Linux应用而生,其是为了极致的GPU亲和性而设计的。
参数上,Vera CPU采用了88个定制的Olympus核心(基于Arm v9.2架构)。但是要注意,Vera CPU并没有追求极致的单核主频,而是专注于多线程吞吐和I/O带宽。通过NVLink-C2C技术,让CPU内存和GPU显存处于同一个内存寻址空间内,将带宽推到了超高速低延迟水平。
场景上看,例如在金融高频交易的AI Agent应用中。模型需要从实时的市场数据流中提取特征(CPU任务),进行复杂的宏观经济推理(GPU任务),然后瞬间执行交易(CPU/网卡任务)。而在传统架构中,数据在CPU内存和GPU显存之间来回拷贝(Copy overhead)会带来一定的延迟。而在Vera-Rubin架构中,数据一旦进入Vera的内存,Rubin GPU就可以直接读取,零拷贝,零延迟。
03 NVLink 6与NVLink Spine:用铜缆打造“巨型GPU”
在万亿参数模型时代,单个芯片的性能已逼近物理极限,真正的决胜点转移到了芯片与芯片之间的通信效率上。对于Vera Rubin NVL72而言,通信即计算。
正如黄仁勋反复强调的:“不要把它看作是72个独立的Vera Rubin,请把它看作是一个拥有144个Rubin GPU(注:单颗Rubin含双GPU Die)的巨型芯片。”
要实现这一理念,必须消除GPU之间的物理距离感。传统的以太网或InfiniBand虽然强大,但在处理机柜内部纳秒级的超高频海量数据交换时,光电转换(Optical Transceiver)带来的延迟和功耗成为了不可忽视的物理瓶颈。
NVIDIA给出的答案是NVLink Spine——一个完全基于铜缆的机架背板互连系统。在Rubin架构中,NVIDIA利用高度定制的400 Gbps SerDes技术,让电信号能够直接驱动铜缆从机架顶部贯穿到底部。
这带来了两个决定性的优势:
一个是零光电损耗:在机柜内部彻底终结了光电转换,节省了成千上万个昂贵的光模块,直接省去了数千瓦的转换功耗。
另一个是全互联带宽:配合第六代NVLink Switch,这一铜缆脊柱支撑起了惊人的240 TB/s背板总带宽。这相当于全球互联网总流量(约100TB/s)的两倍以上。
在如此大的带宽下,NVLink 6交换机实现了真正的无阻塞通信(Non-blocking Communication)。机柜内的每一个GPU都可以在同一时刻与任何一个其他GPU进行全速通信。
当模型被切分到144个GPU上时,GPU 0访问GPU143的显存,其速度和延迟几乎等同于访问本地显存。模型并行(Model Parallelism)不再是不得不做的妥协,而变成了系统的原生能力。
Vera Rubin NVL72的另一大突破在于物理形态的重构。为了容纳如此高密度的算力和铜缆,NVIDIA重新设计了计算托盘(Compute Tray)。
在该新架构中,计算节点内部没有任何电缆、软管或风扇。所有连接——包括供电、数据传输和冷却液——都通过盲插(Blind Mate)接口直接与背板对接。
这是维护体验的变革,组装或更换一个节点的时间从过去的2小时缩短到了5分钟。配合45摄氏度进水的温水水冷技术,为现代AI工厂量身定制的高可用性基础设施。
04 BlueField 4构建可共享、可动态分配的超大规模上下文内存池
在Agentic AI时代,KV Cache(键值缓存)是大模型推理中最棘手的问题之一。
当用户与AI进行长达数小时的对话,或者AI需要阅读几百页的PDF时,产生的KV Cache数据量会迅速膨胀到几十GB甚至几百GB。显存(HBM)太贵且太小,存不下;内存(DRAM)太慢,导致首字生成延迟(TTFT)过高。
所以,NVIDIA的解决方案是——Inference Context Memory Storage Platform(推理上下文记忆存储平台)
在Rubin架构下,Inference Context Memory Storage Platform通过 BlueField-4,在机架层面构建了一个可共享、可动态分配的超大规模上下文内存池。
借助 Spectrum-X以太网提供的低延迟东-西向互联,KV Cache 可以以接近内存级别的速度被GPU访问。这在逻辑上,相当于为每张GPU 扩展了数量级远超HBM 的上下文容量(TB 级)。
这意味着,GPU不再被有限的显存容量“卡死”在并发数和上下文长度之间做取舍,而是可以长期保存、复用数百万Token 的历史上下文,为长时对话、复杂文档理解和多步 Agent推理提供现实可行的基础。
在此前,面对500GB级KV Cache时,GPU要么被有限的HBM卡住,只能支持极少量并发用户,要么每次推理都需重新计算,延迟高且成本大。但如今,AI模型可以轻松记住数百万Token的对话历史,处理海量文档,且访问速度极快。这不仅解决了“存不下”的物理瓶颈,更让长上下文推理的成本大幅下降,使“终身”式的AI代理成为可能。
05 Alpamayo:自动驾驶从“黑箱决策”迈向“因果推理
在自动驾驶领域,架构路线之争由来已久。一端是规则清晰、可验证但扩展性受限的模块化系统,另一端则是表达能力强、却难以解释的端到端大模型。
NVIDIA通过Alpamayo给出了第三种选择——具备可解释推理能力的端到端模型。
Alpamayo作为VLA(视觉-语言-动作)模型,其核心突破在于结合因果链(CoC)推理与轨迹规划,主要增强复杂驾驶场景中的决策能力。与传统“感知到控制”的直接映射不同,Alpamayo的决策过程更接近人类驾驶员的推理方式。
搭载传统系统的车辆,在红灯前停车,一般是像素特征触发规则或网络响应的结果。而在Alpamayo架构下,模型会完成一系列中间判断,再得出最终行动决策。

截取自NVIDIA官网
Alpamayo参数规模约为100亿参数(10B),这一参数规模能在保证推理表达能力的同时,也能在车载边缘计算平台(如 DRIVE Thor)上高效运行。模型以视频流作为输入,输出不仅包含车辆的行驶轨迹(Trajectory),还同步生成可供审计的推理踪迹(Reasoning Traces)。
在复杂的城市路口场景中,道路施工,车道线模糊的情况,传统模型往往会因规则优先级冲突而出现犹豫甚至停滞。在现场演示中,Alpamayo的推理过程则呈现为:检测到施工区域 → 识别到信号灯为红灯 → 根据交通法规 → 观察周围车辆正在缓慢通行 → 决定跟随车流,低速通过路口。

截取自youtube
这一能力带来的价值更重要的是建立了人机之间的信任基础。当车辆做出非常规决策时,系统能够解释“为什么这么做”,这对于 L3/L4 级自动驾驶的商业化落地尤为关键。
在引入推理型大模型的同时,NVIDIA也没有未放弃对安全确定性的坚持。为此,其引入了NVIDIA DRIVE AV双栈架构。
主栈(AI Stack)由Alpamayo驱动,负责覆盖绝大多数驾驶场景,尤其是涉及复杂交互的情况,其行为风格更接近经验丰富的人类驾驶员。
副栈(Safety Stack)则基于NVIDIA Halos安全系统构建,采用确定性的规则与物理约束,不依赖概率推断,作为系统的最后安全兜底。
这种设计使车辆在获得持续进化能力的同时,依然保留传统汽车工程所要求的可验证安全边界。对于奔驰、Lucid、Uber 等合作伙伴而言,双栈架构意味着在满足法规与安全要求的前提下,通过OTA持续释放AI带来的体验升级。
为加速模型迭代,NVIDIA开放了Physical AI Open Datasets,提供超过1700小时覆盖极端和稀缺场景的高质量驾驶数据。这些数据为推理型模型训练和验证提供了关键资源。同时,结合AlpaSim仿真框架和Cosmos大规模合成场景生成能力,开发者可以形成“训练—部署—回传—再训练”的闭环。随着这一“虚实”飞轮持续运转,自动驾驶系统的进化速度将不再主要受限于真实道路里程,而更多取决于算力与工程投入规模。
06 Cosmos:不只“看见” 更要让 AI真正理解物理世界
如果说 Alpamayo是为自动驾驶量身定制的“专项训练模型”,那么 NVIDIA Cosmos 的定位更接近于——物理AI的通用认知底座。
Cosmos 的核心目标,并非生成“看起来真实”的内容,而是让 AI 内化物理世界的基本规律:重力如何作用于物体、材质如何决定破坏方式、摩擦力如何影响运动轨迹、遮挡与光照如何改变感知结果。
这也是 Cosmos 与传统文生视频模型的本质差异所在——前者追求物理一致性,后者强调视觉合理性。

截取自NVIDIA官网
很多人容易将Cosmos混同于文生视频模型,但其技术内核有着本质区别。Cosmos包含三个核心模块,构成出完整的认知闭环。
Cosmos Reason 2(理解)赋予机器“看懂”物理属性的能力。当机器人看到一个玻璃杯时,Cosmos Reason能告诉它:“这是玻璃材质,硬度高但易碎,表面摩擦系数低,抓取时需要控制力度。”这比单纯的物体识别进了一大步。
Cosmos Predict 2.5(预测): 是物理AI的精髓。其能预测“未来”。在仿真环境中,如果机器人松手,Cosmos Predict能精确生成杯子掉落、触地破碎、碎片飞溅的物理级视频。
Cosmos Transfer 2.5(迁移): 致力于解决Sim-to-Real(仿真到现实)的鸿沟。其让在虚拟世界中训练的策略,能够无缝迁移到真实的物理机器人上。
另一面,Cosmos最直接的价值在于合成数据(Synthetic Data)的规模化生产。
在物理 AI 场景中,真实数据往往昂贵、稀缺,甚至不可获得。不能为了训练消防机器人而纵火,也不能为了训练自动驾驶而制造真实事故。
Cosmos的价值,正在于此,其允许开发者在Omniverse中批量生成具备物理真实性的合成数据,包括图像、视频,甚至力反馈信号。这使得物理AI的训练成本,从“美元级/样本”降至“美分级/样本”。
目前,Salesforce、Hitachi、Uber等企业,已经在借助 Cosmos 生成的合成数据,加速其 AI Agent 在复杂物理环境中的泛化能力。
07 Isaac GR00T N1.6从“专用工具”到“通用伙伴”
在Cosmos的底层支撑下,Isaac Project GR00T本次也迎来了重要升级——Isaac GR00T N1.6。
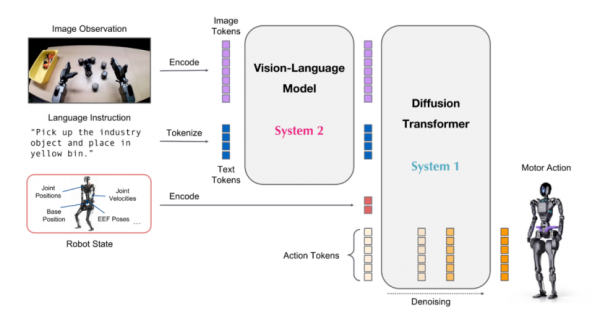
这是NVIDIA面向人形机器人推出的通用基础模型。与Alpamayo类似,Isaac GR00T N1.6也是典型的VLA模型,模型能够理解自然语言指令,结合视觉与传感器感知,直接输出面向关节层级的控制信号,从而缩短从“理解意图”到“执行动作”之间的路径。
在能力设计上,Isaac GR00T N1.6更强调对人形机器人完整身体结构的适配。
一方面,Isaac GR00T N1.6 不仅能处理视觉信息,还能够融合触觉等传感器输入,用于完成精细的操作任务。同时,GR00T N1.6 的神经网络架构结合了视觉语言基础模型和扩散变换器头部,用于对连续动作进行去噪;另一方面,其控制策略针对人形机器人的动力学特性进行了专门优化,在执行上肢操作的同时,下肢能够持续维持动态平衡,避免传统分模块控制中常见的姿态失稳问题。
截取自:Github
为了在本地运行Isaac GR00T N1.6模型,NVIDIA 同步更新了Jetson Thor平台。
Jetson Thor将机器人的“感知中枢”与“运动控制中枢”整合于一体。在严格功耗约束下提供接近服务器级别的推理能力。这意味着机器人不再依赖持续云连接,即便在工厂、地下空间或户外弱网环境中,也能保持完整的感知、推理与行动闭环。
在模型能力与端侧算力之外,机器人真正走向规模化应用,还需要依高效的工程编排方式。为此,NVIDIA推出了OSMO编排服务。
由于现实中的机器人开发流程高度碎片化,模型往往在数据中心平台上训练,在OVX环境中进行仿真验证,最终部署到边缘设备上。不同阶段使用的算力形态、工具链和运行环境差异巨大,协同成本极高。
OSMO的作用,就是将这些离散环节抽象为可编排的云原生流程。开发者只需定义任务目标,OSMO即可自动调度云端与本地的异构算力资源。在云端生成合成数据、完成模型训练与验证,再将模型打包并推送至分布在各地的机器人终端。
而这种模式,其实显著降低了物理AI的工程门槛,即便是规模有限的初创团队,也能够以接近大型科技公司的效率,完成机器人系统的持续迭代。
08 Nemotron:为企业AI补齐“后一公里能力”
在面向物理计算平台持续发力的同时,NVIDIA Nemotron更新了包括Speech(语音)、RAG(检索增强生成)和Safety(安全)模型。
Nemotron Speech聚焦实时语音交互。在博世车载助手的落地中,驾驶员的语音指令几乎在落音的瞬间就得到响应,支撑这一体验的是端侧全流程的低延迟推理。通过量化与模型剪枝,Speech能够在Jetson Orin或RTX AI PC端本地运行,不仅能保证在无网络环境下的可用性,也避免了数据传输带来的能耗和隐私风险。
这种部署方式,使AI交互真正达到了工业级的可靠性与实时性。
Nemotron RAG模型,则解决了企业知识资产的“最后一公里”。通过Embedding与Rerank机制,其能够从海量文档中精准提取关键信息,显著提升知识检索的效率。
ServiceNow、Cadence、IBM等企业已借助Nemotron RAG构建其内部助手,实现专业化场景下的高效信息处理。更重要的是,NVIDIA提供的标准化RAG模块Blueprint,使企业可以在现有架构上快速部署,而无需从零开发底层算法,这在企业级AI落地中尤为关键。
与此同时,Nemotron Safety也能为AI应用提供独立的安全护栏。该模型能够过滤幻觉、偏见和潜在有害信息,为企业提供可定制的内容审核机制。在CrowdStrike、Fortinet等安全应用中,Nemotron Safety不仅实现了自动化审核,也逐步形成了行业安全标准。
在CES 2026上,黄仁勋也指出,AI扩展不仅是算力之争,更涉及数据搬运能耗和推理上下文存储成本。Nemotron的端侧部署、模型优化与流水线设计,正是对这两大隐形成本的回应——既保证了性能,也提升了企业部署的经济可行性。
09 生态扩展:微软、CoreWeave与Red Hat
NVIDIA通过OpenShift的深度适配,金融、医疗等高敏感行业也获得了可落地的 AI 基础设施标准。
微软宣布了下一代AI超级工厂“Fairwater”基于Vera Rubin NVL72构建的系统,将扩展至数十万颗GPU的规模。
这也传递了一个信号,云巨头(Hyperscalers)虽然都在自研芯片,但在追求极致性能和上线速度(Time-to-Market)的顶级战场上,NVIDIA依然是更优的选择。Rubin平台的全栈优化,让微软能够以最快的速度部署高级别的模型服务。
CoreWeave作为NVIDIA云合作伙伴之一,展示了另一种生态位。通过集成NVIDIA Mission Control软件,CoreWeave能够像管理电力一样管理算力,为客户提供灵活的Rubin实例。这种专注于AI算力的“特种云”,正在成为初创公司和科研机构的首选。
如果说微软和CoreWeave解决的是公有云问题,那么与Red Hat的合作则打通了私有部署。通过将Rubin平台与Red Hat OpenShift全栈优化,NVIDIA为那些对数据隐私极其敏感的金融、医疗企业,提供了一套开箱即用的AI基础设施标准。
来源:至顶网计算频道
好文章,需要你的鼓励


超越能源使用:数据中心可持续运营策略
随着AI广泛应用推动数据中心建设热潮,运营商面临可持续发展挑战。2024年底美国已建成或批准1240个数据中心,能耗激增引发争议。除能源问题外,服务器和GPU更新换代产生的电子废物同样严重。通过采用模块化可修复系统、AI驱动资产跟踪、标准化数据清理技术以及与认证ITAD合作伙伴合作,数据中心可实现循环经济模式,在确保数据安全的同时减少环境影响。

剑桥大学突破性研究:如何让AI在对话中学会真正的自信判断
剑桥大学研究团队首次系统探索AI在多轮对话中的信心判断问题。研究发现当前AI系统在评估自己答案可靠性方面存在严重缺陷,容易被对话长度而非信息质量误导。团队提出P(SUFFICIENT)等新方法,但整体问题仍待解决。该研究为AI在医疗、法律等关键领域的安全应用提供重要指导,强调了开发更可信AI系统的紧迫性。

2026年超大规模数据中心运营商发展前瞻:全球最大数据中心运营商的未来走向
超大规模云数据中心是数字经济的支柱,2026年将继续保持核心地位。AWS、微软、谷歌、Meta、甲骨文和阿里巴巴等主要运营商正积极扩张以满足AI和云服务需求激增,预计2026年资本支出将超过6000亿美元。然而增长受到电力供应、设备交付和当地阻力制约。截至2025年末,全球运营中的超大规模数据中心达1297个,总容量预计在12个季度内翻倍。

威斯康星大学研究团队破解洪水监测难题:AI模型终于学会了“眼观六路“
威斯康星大学研究团队开发出Prithvi-CAFE洪水监测系统,通过"双视觉协作"机制解决了AI地理基础模型在洪水识别上的局限性。该系统巧妙融合全局理解和局部细节能力,在国际标准数据集上创造最佳成绩,参数效率提升93%,为全球洪水预警和防灾减灾提供了更准确可靠的技术方案。
2026
01/06
16:49
分享
点赞

Littelfuse推出适用于电动汽车电池、电机和安全系统的汽车级电流传感器
CES 2026 | 机器人开发的“ChatGPT时刻”已到 老黄定调“物理AI”的路线图
超越能源使用:数据中心可持续运营策略
2026年超大规模数据中心运营商发展前瞻:全球最大数据中心运营商的未来走向
TOTOLINK EX200存在未修复固件漏洞可被完全远程接管
Ring推出Fire Watch功能,利用家庭摄像头追踪野火威胁
Snowflake与Google Gemini深度整合,全云环境支持数据分析
联想和摩托罗拉推出自有设备端AI助手
机器海龟游向环保使命:仿生技术守护珊瑚礁
CES 2026最酷笔记本电脑:可拆卸设计成为新趋势
AMD 在 CES 2026 发布新款锐龙处理器、Ryzen AI 及 AMD ROCm,全面扩展其在客户端、图形和软件领域的 AI 领先地位
AMD发布Instinct GPU新品挑战英伟达数据中心霸主地位
