
CES 2026 | 撕碎“显存墙”,重塑“光追梦”,打通“生态路” AMD开启全新“统治力” 原创
从2024年对“AI PC”概念的初步界定,到2025年NPU算力规模与软件生态加速形成闭环。站在2026年,AMD正通过架构层面的重构,重新定义 AI PC 的进化路径。
站在2026年,AI的用户规模与应用渗透正在把端侧算力推向“基础设施级”的需求拐点。AMD CEO苏姿丰在CES 2026的主题演讲中表示,自ChatGPT推出以来,使用AI的活跃用户已经从100万人增加至10亿人,这是互联网花了几十年才达到的里程碑,预计2030年使用AI的活跃用户将达到50亿人。为了让AI无处不在,在未来几年内,需要将全世界的计算能力增加100倍。也正是在这种需求指数级增长下,AMD正重新定义AI PC的进化路径。

AMD展示的技术产品版图,不同于常规的频率提升或核心堆叠,这一次,AMD致力于解决后摩尔时代棘手的两个矛盾——端侧大模型对显存带宽的渴求与物理空间限制,以及光追游戏画质与性能的“零和博弈”。
从“Strix Halo”完全体AMD 锐龙AI Max+系列的落地,到锐龙AI 400系列的能效重塑,再到 FSR Redstone对图形算法的AI化改造,AMD的角色正逐渐转变为异构计算生态的“布局者”,从硅片逻辑、技术参数、场景落地与产业博弈,加速推进2026年PC产业的剧变。
01 AMD 锐龙AI Max+“核显怪兽”撕裂“显存墙”
在很长一段时间里,移动端高性能计算设备运行AI应用时,常常存在难以逾越的鸿沟:“Windows阵营”拥有强大的独立显卡,但受限于显存容量(VRAM)和 PCIe 总线带宽,无法高效运行大规模AI模型;而苹果阵营拥有统一内存架构(UMA),但封闭的生态让游戏与工业软件的兼容性始终是痛点。
然而,AMD 锐龙AI Max+系列的推出,本质上则是x86 阵营对UMA 架构的暴力改革,也是对“移动工作站”形态的重新定义。
AMD 锐龙AI Max+系列或许可以定义为“反传统”的产品。从规格上看,其集成了16 核Zen 5 CPU、40 个计算单元(CU)的RDNA 3.5 GPU,以及最高128GB的统一内存。这种组合建立在AMD对Chiplet(芯粒)封装技术的深度运用之上。

要理解这颗APU的定位,首先需要对“40 个 CU”建立直观认知。对比来看,桌面级的 AMD Radeon RX 7600 XT仅有32个CU,而索尼PS5的GPU规模为36个CU。也就是说,AMD 锐龙AI Max+系列实际上是在移动端APU中,塞入了规模超越主流“甜点级”独立显卡的GPU核心。
与此同时,其AMD 锐龙AI Max+系列的RDNA 3.5架构针对低功耗场景下的电压/频率曲线(V/F Curve)进行了重新调校。其60TFLOPS(FP16)算力,正是这一性能密度设计的集中体现。这一指标直接指向了AI推理等高并行计算场景。
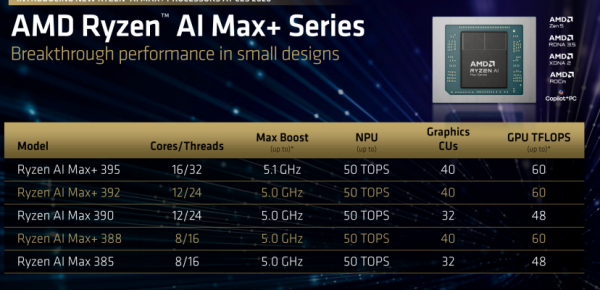
其实,AMD 锐龙AI Max+系列设计的关键优势,在于能否解决GPU 的“带宽饥渴”问题。对于40个CU的GPU而言,传统移动平台常见的128-bit双通道DDR5 / LPDDR5X,约100GB/s的带宽显然无法支撑其持续满载运行。但从AMD 锐龙AI Max+系列“工作站级”的定位,以及支持128GB的统一内存容量推断,AMD 锐龙AI Max+系列的内存带宽量级,完全可以避免GPU因等待数据而空转。
从工程角度看,这意味着将原本更多用于服务器或高端平台的内存控制器复杂度,下放到移动端。
而真正将这一架构“串联”起来的,是AMD的零拷贝(Zero-Copy)机制。在传统独显移动PC中,CPU计算完成后需要通过PCIe总线将数据传输至GPU显存,这一过程存在显著的延迟与功耗损耗。相比之下,在AMD 锐龙AI Max+系列的统一内存架构下,CPU、GPU 与 NPU直接访问同一物理地址空间。这对于大模型推理而言,意味着数据搬运环节被彻底省去,模型加载与执行效率不再受制于总线瓶颈。
技术突破的价值,最终也要体现在具体的应用场景之上。基于AMD 锐龙AI Max+系列的统一内存架构与算力配置,可以明确诸多具有代表性的移动办公应用范式。
其中的典型,一方面是AI Coding“本地闭环”式的开发环境。在以往的移动办公PC上,大模型调试受制于显存容量。以70B级的开源模型为例,即便经过量化处理,依然需要40GB以上的可用显存,这使得本地开发只能依赖远程云服务器完成推理与微调任务,随之而来的则是高昂成本、网络依赖,以及数据外流风险。
AMD 锐龙AI Max+系列支持最高128GB统一内存,从根本上改变了这一约束条件。在该架构下,大模型不再被“显存墙”所限制,而是直接由系统内存承载。结合AMD RDNA 3.5 GPU提供的FP16算力,百亿乃至更大规模参数模型的本地推理成为可行选项。
同时,统一内存与零拷贝机制消除了CPU、GPU之间的数据搬运开销,使得模型加载、推理与轻量级微调可以在本地形成完整闭环。在这一模式下,AI Coding便脱离了对云端资源的刚性依赖。
另一方面,是影视后期制作中“实时工作流”的下沉。在传统移动工作站形态下,高分辨率视频处理高度依赖独立显卡显存与持续供电能力。8K RAW 素材的解码、降噪与调色,往往需要牺牲机动性,以换取性能稳定性;同时,CPU与GPU之间频繁的帧缓冲交换,也迫使设计师要采用代理剪辑等折中方案。
反观AMD 锐龙AI Max+系列的40 CU集成的GPU与128GB大容量统一内存,共同构成了高带宽共享缓存池。视频解码、特效计算与渲染结果可在同一物理内存空间内完成流转,避免了跨设备拷贝带来的延迟。这使得高分辨率素材的实时预览与调整,从“固定工作流”延伸至移动设备,复杂度显著降低。
从典型的场景中可以看出,AMD 锐龙AI Max+系列的意义在于通过其独特的UMA架构与算力密度的组合,重塑了移动端设备的能力边界——原本只能在云端或桌面级工作站完成的任务,开始具备在本地、在移动环境中完成的现实条件。
02 “集团军”压境 AMD 锐龙AI 400 横扫主流战场
如果说,AMD 锐龙AI Max+系列是AMD的“核武器”,那么AMD 锐龙AI 400系列则是其在主流市场的“集团军”。事实上,AMD在这一代产品中展现出了极强的战术素养,其核心在于异构核心的精细调度与NPU的算力冗余。

以AMD 锐龙AI 400系列的AMD 锐龙AI 9 HX 475为例,其12核心配置了4个Zen 5 超大核+8个Zen 5c“大核”。
当然,这里需要纠正一个误区:Zen 5c并不是E-core(能效核)。其拥有相同的基础架构、完整的指令集(包括 AVX-512)和相同的IPC(每时钟周期指令数),仅仅是通过缩减缓存和降低频率上限来换取更小的核心面积。
这一设计的技术逻辑非常清晰。在移动端,大多数瞬时高负载(如打开网页、启动 App)需要2~4个高频核心瞬间响应。而后台的AI代理、视频会议、数据同步等多任务并行,更适合由8个低功耗的Zen 5c 核心来吞吐。这种配置在15W~54W 的黄金TDP区间内,能效比收益则达到更高。

而在NPU方面,AMD 锐龙AI 400系列的算力出现了明显的分级(AI 9 HX 475为60 TOPS,AI 9 HX 470为55TOPS,AI 9 465/AI 7 450等为50 TOPS)。这揭示了AMD的 Binning(芯片分级)策略。其XDNA 2架构引入了对BFP(Block Floating Point 16)数据格式的支持。BFP结合浮点数的动态范围和定点数的计算效率,可在保持精度的前提下大幅提升吞吐量。60 TOPS的算力则意味着NPU有足够的余量在运行微软Windows 11 AI+PC(40 TOPS)的同时,还能分出算力给第三方的本地Agent。 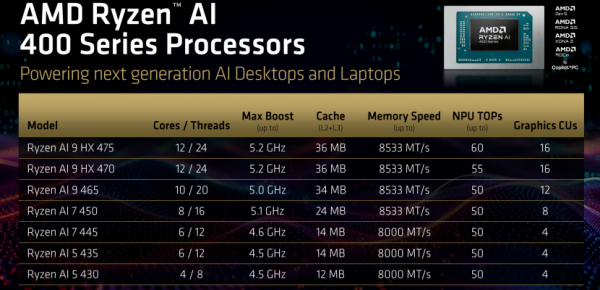
算力的余量在于为软件形态的演进预留空间。AMD此次展示的AI Agent Framework,正是围绕 AMD 锐龙AI 400系列,对商用办公场景的系统级重构。
传统移动PC的架构在使用视频会议时,背景虚化、实时转录、翻译等功能,通常由CPU GPU以“抢占式”的方式完成。这种模式抬高了瞬时负载,也直接推高了整机功耗,导致风扇频繁介入、电池续航缩短,体验上始终存在结构性瓶颈。
而利用AMD 锐龙AI 400系列,上述问题的解决路径,变成了计算任务的重新分配。依托AI Agent Framework,视觉处理、语音识别与实时文本转录等持续性AI任务,由NPU独立承载。这背后,在于NPU以极低功耗完成长时间稳定运行。
与此同时,后台的业务分析类Agent(如本地表格处理、数据清洗等任务),则优先运行在Zen 5c核心之上,仅在必要时才唤醒高性能超大核参与计算。这种分层调度机制,使得整机在多Agent 并行运行的情况下,依然能够维持较低的平均功耗水平。
结果上,则体现出更持续、更稳定的状态。视频会议、实时转录、翻译与后台分析可以同时进行,不会引发系统整体负载飙升。在长时间使用场景下,电量消耗与机身热量均得到有效控制。
这也意味着,AI不再以高功耗形式介入系统,而是以基础能力的方式,融入到日常办公之中。
从这一角度看,AMD 锐龙AI 400系列与AI Agent Framework的组合,则标志着商用办公从“功能叠加”,迈入了“异构协同、长期运行”的新阶段。
03 代号“Redstone”FSR 终结光追焦虑
在游戏图形领域,CES 2026上,AMD展示了其代号“Redstone”的全新FSR技术套件(下称“FSR Redstone”)。
FSR Redstone的优势,在于其底层算法全面转向机器学习驱动。这是明确的战略转折,意味着AMD 正式将AI视为实时图形渲染体系中的核心组成部分,而非辅助工具。
其中最关键的技术突破,是光线重建(Ray Regeneration)。在实时光线追踪中,由于算力预算有限,每像素可投射的光线数量(SPP)极低,直接导致原始渲染结果噪点密集。传统方案依赖人工设计的降噪器(Denoiser)对结果进行平滑处理,但这种方式往往以牺牲高频细节为代价,产生明显的“涂抹感”与画面不稳定问题。
FSR Redstone通过引入训练完成的深度神经网络(DNN),用学习式重建替代了规则驱动的降噪流程。该网络基于低SPP的噪点图像、运动矢量,以及几何缓冲数据,对光照与反射信息进行预测与重建,从而恢复更完整的光影细节。在提升画质的同时,这一方案还取代了计算负担较重的传统降噪流程,反而在整体上降低了GPU的实时计算压力。
此外,FSR Redstone 还结合了辐射缓存(Radiance Caching)技术,通过对光照结果进行预测与缓存,减少重复的BVH(包围体层次结构)遍历和光线求交计算,进一步提升了光追场景下的效率。
在3A游戏场景中,FSR Redstone 的改进集中体现在“稳定性”与“细节完整度”维度。以高复杂度光追场景为例,传统方案下常见的反射噪点、细小几何体闪烁(Shimmering),以及帧率波动,在光线重建介入后得到显著缓解。积水路面的倒影更加清晰,间接光照的过渡更为自然,高频闪烁现象明显减少。
在此基础上,配合基于机器学习的帧生成技术,4K分辨率下的高帧率光追体验不再局限于旗舰级显卡。从结果来看,FSR Redstone解决了长期存在的核心矛盾。光追不再意味着“性能不可接受”,而关闭光追也不再是画质妥协。这使得光线追踪转变为真正具备普遍可用性的渲染选项。

04 “狂飙”5.6GHz AMD 锐龙7 9850X3D让“1% Low”帧数稳如磐石
在AI的喧嚣之外,AMD也没有忘记它的基本盘。AMD 锐龙7 9850X3D,既是对“更强游戏 CPU”名号的卫冕,也是对物理极限的一次挑战。
回顾从前,AMD 锐龙7 7800 X3D的最大加速频率在5.0 GHz,原因是堆叠在计算核心上方的3D V-Cache对电压和温度极度敏感。
而AMD 锐龙7 9850 X3D能跑到 5.6 GHz,这说明AMD在利用TSMC SoIC(System on Integrated Chips)封装技术上的新突破。
在高帧率电竞与高质量直播并行的场景下,前台游戏对低延迟与稳定帧时间高度敏感,而后台推流、虚拟形象与音频处理则持续消耗CPU 计算资源。为避免相互干扰,职业级主播普遍采用双机推流方案,以物理隔离换取稳定性。
而搭载AMD 锐龙7 9850X3D的平台,可以提供单机层面的解决路径。
在游戏侧,大容量的“L2+L3 ”缓存(104MB)显著降低了内存访问延迟,使得《CS2》《无畏契约》等对帧时间极其敏感的电竞游戏,能够维持1% Low的表现,从而有效抑制微卡顿现象,为超高刷新率显示器提供稳定输入。
在后台任务侧,AMD 锐龙7 9850X3D可依托5.6 GHz 的运行频率与Zen 5架构的IPC 优势,同时承载高码率OBS推流、虚拟形象捕捉,以及AI语音降噪等持续性负载,且不对前台游戏线程形成明显挤占。

05 软硬合璧 ROCm 7.2 为亿万 Windows用户铺平AI道路
再强的硬件,如果无法进入主流开发环境,其价值终究难以释放。
本次CES 2026上,AMD推出ROCm 7.2,这是其软件生态建设中的关键一步,目标直指广泛的开发者使用场景。
ROCm 7.2的核心进展,在于 HIP(Heterogeneous-Compute Interface for Portability)在Windows及Linux平台上的完整落地。这使得基于HIP的PyTorch等代码,可以在Windows等环境中直接运行在AMD Radeon RX 9000系列及锐龙AI系列上,仅需极少量适配,甚至无需配置。
 这一变化显著降低了平台切换与环境维护成本。同一套代码在不同操作系统间复用,开发流程更加连续。与此同时,AMD对底层矩阵乘法库进行了针对性优化,使ROCm 7.2在 Windows环境下的推理性能相较旧版本实现了大幅提升,为实际应用提供了更稳定的性能基础。
这一变化显著降低了平台切换与环境维护成本。同一套代码在不同操作系统间复用,开发流程更加连续。与此同时,AMD对底层矩阵乘法库进行了针对性优化,使ROCm 7.2在 Windows环境下的推理性能相较旧版本实现了大幅提升,为实际应用提供了更稳定的性能基础。
在AI创作与学习场景中,工具链复杂度往往构成隐性门槛。过去,许多框架与工作流依赖特定系统环境,部署与调试成本较高,限制了更广泛人群的参与。
ROCm 7.2对Windows 的支持,使这一状况发生转变。AI工具可以在Windows系统中完成一站式部署,底层环境由系统自动配置,减少了对系统知识与手动排错的依赖。在此基础上,主流模型与插件的运行路径趋于标准化,社区支持与经验复用的效率同步提升。
当AI开发与创作不再被环境复杂度所阻挡,更多学习者与创作者才能进入这一生态,软件能力才具备持续演进的土壤。
06 写在最后
综观AMD在CES 2026展示的技术产品矩阵,不难看出清晰的战略主线——以体验为中心的算力重构。
AMD并没有在单纯的CPU频率或GPU规模单一维度进行“消耗战”,更多是利用Chiplet 和异构架构的灵活性,进行了精准的战略布局。
AMD 锐龙AI Max+系列用“统一大内存”切入AI开发者的刚需,开辟移动AI高性能工作站的新蓝海,加快占据更高的生态位。AMD 锐龙AI 400系列用“NPU 分级设计与能效核心”解决了移动办公用户对续航和隐私的焦虑,重新定义了主流移动PC的标准。FSR Redstone 用“AI 重构图形”补齐了光追画质的短板,让显卡算力花在刀刃上。AMD 锐龙7 9850X3D用“封装技术的突破”巩固了游戏王座,满足极客用户挑剔的需求。
对于消费者、移动办公用户而言,2026年或许也是换机的绝佳时刻。毕竟,当强大的本地算力真正打破从灵感到落地的最后一道屏障,计算设备便成为了延伸人类智慧的“第二大脑”。
这,或许也是AI PC深度进化的下一个形态。
来源:至顶网计算频道
好文章,需要你的鼓励



台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。

脑部植入物助瘫痪男子重获进食与饮水能力
一名因游泳事故导致胸部以下瘫痪的男子,通过脑植入芯片重新获得了自主进食和饮水的能力。研究人员为其安装了脑机接口,不仅帮助他重新活动手臂,还通过信号反馈重建了触觉感知。经过35周训练,其右臂力量提升86%,左臂提升62%。更令人惊喜的是,该技术似乎部分重塑了其神经系统,即使在系统关闭后,部分手部功能和感觉仍得以保留。

AI代码审查如何让软件开发从“一锤子买卖“变成闭环迭代?南洋理工大学、华为等机构给出了答案
南洋理工大学、华为等机构提出SWE-Review框架,让AI审查者主动探索代码仓库,通过"写-审-改"闭环将软件问题解决率大幅提升,并发布8914条训练轨迹供开源研究使用。
2026
01/06
11:49
分享
点赞

WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
Moonshot即将发布的Kimi K3有望赶超Anthropic Opus 4.8
OpenAI 为何开始卖 ChatGPT 品牌篮球?
DoorDash推出命令行工具,开发者可借助AI智能体直接下单
Google AI模式新增应用集成功能,支持Instacart等多款常用应用
Beehiiv推出社区互动功能并上线AI写作助手
经期追踪应用Stardust被曝将用户健康数据共享给第三方分析公司
英国警方:两名黑客被捕重创知名黑客组织"散落蜘蛛"
谷歌将NotebookLM更名为Gemini Notebook,强化生态系统整合
