
AMD发布“TURIN”EPYC CPU预览,并扩展INSTINCT GPU技术路线图

于中国台北召开的Computex国际电脑展是一年一度的国际技术盛会,旨在展示中国台湾庞大的计算业务体系。而如今的Computex更是成为数据中心IT领域的中场大秀。而作为从台湾走出的影响力领袖,英伟达和AMD的CEO近年来也开始在Computex上发表主题演讲,借此机会发布新产品以及技术发展路线图。
有趣的是,AMD公司CEO苏姿丰其实是英伟达联合创始人兼CEO黄仁勋的远房表亲。黄仁勋在Computex 2024开幕之夜上发表了主题演讲,公布了英伟达从当下到2027年的计算与网络技术路线图。苏姿丰则作为会议首日开场嘉宾,与黄仁勋一样带来了AMD的芯片产品与路线图规划。
苏姿丰在演讲中直奔主题,拿出一半多的时间来讨论基于Zen 5核心的新款Ryzen CPU。这些CPU经过调优,可通过神经网络处理器(NNP)实现AI工作负载加速。虽然此类矩阵数学单元最终应该也会出现在数据中心级的Epyc x86 CPU当中,但我们发现此番Ryzen演讲公布的Zen 5核心规格相当有趣。Zen 5既是当前Ryzen 9000系列处理器的核心,同时也将为今年下半年推出的Turin Epyc服务器CPU提供动力。

苏姿丰表示,Zen 5核心是AMD公司有史以来设计出的性能最强、能效最高的核心,而且完全是从零开始打造而成。
苏姿丰解释道,“我们拥有一个并行的双管线前端,其作用就是提高分支预测准确性并减少延迟。它还让我们能够在每个时钟周期之内提供更高的性能。在Zen 5的设计当中,我们也引入了更宽的CPU引擎指令窗口,以便并行运行更多指令,从而实现领先的计算吞吐量与效率。这一切让Zen 5与Zen 4相比,指令带宽增加了一倍,缓存和浮点单元间的数据带宽同样增加一倍,AI性能随之增长一倍,同时可以实现完整的AVX 512吞吐量。”
旗舰级Ryzen 9000拥有16个核心和32个线程,加速后的运行速率为5.67 GHz。Zen 5核心的平均每核指令数年也比以往Ryzen芯片以及“Genoa”Epyc 9000系列处理器中使用的Zen 4核心多出16%。(顺带一提,「Bergamo」Epyc处理器的每个插槽可容纳更多核心,但每核心的L3缓存被减半,而且采用所谓Zen 4c的不同核心布局,因此实现了更高的核心密度。)Zen 4代Epyc已经成功提升了AMD在x86服务器CPU领域的市场份额,苏姿丰在演讲中还专门引用了Mercury Research发布的信息,结果显示AMD的出货量份额已经从2018年Zen 1初代核心“Naples”Epyc 7001系列时的2%,来到Genoa Zen 4核心、Bergamo超大规模及云CPU乃至基于Zen 4c核心“Siena”边缘与通信处理器时期的33%。
下图所示,为苏姿丰手持Turin封装的照片,其中共包含13个小芯片组件:

以下为Turin芯片(也称第五代AMD Epyc)的基本馈送与速度参数:

我们对这款最新服务器CPU了解不多,只知道顶部bin部分将拥有192个Zen 5核心及384条线程,将被装入与Genoa Epyc 9004相同的SP5插槽。Turin芯片可能会被命名为Epyc 9005,并且推出带有Zen 5c核心的变体,可对接与Bergamo及Siena芯片相同的设备插槽。我们预计其每周期指令数(IPC)将与Ryzen Zen 5芯片大致相同,较Zen 4核心提升15%到20%之间。
而向来活跃主动的苏姿丰,也在会上带来了Turin芯片的一些早期基准测试结果。
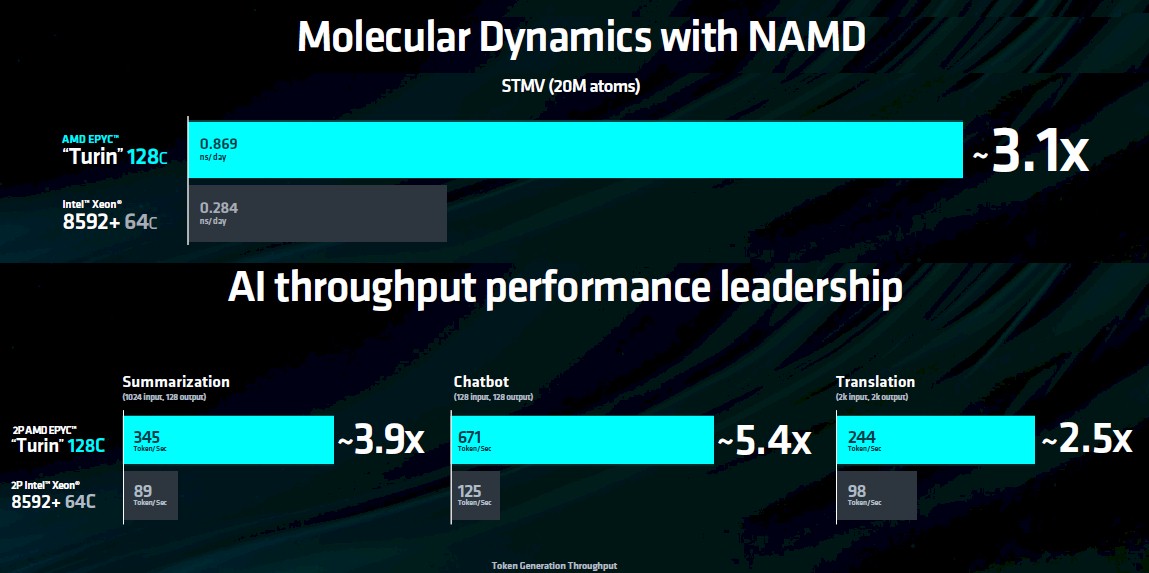
我们将苏姿丰提供的两张图表整合了起来,可以看到单个Turin处理器在NAMD分子动力学应用中运行STMV基准测试时获得了最佳性能,这里使用的处理器为128核配置。在该测试中,Turin处理器模拟了2000万个原子,并统计出其在24个小时之内可以处理多少次分子间相互作用。(令人好奇的 是,AMD为什么没有使用192核芯片配置,理论上这能使其在NAMD上的性能结果再提高33%。)总而言之,128核Turin芯片的处理能力,大约是64核“Emerald Rapids”至强SP-8592+处理器的3.1倍。
AI吞吐量基准测试则基于Meta Platform的Llama 2模型。该模型拥有70亿个参数,以INT4数据格式进行处理,推理令牌生成则设置为50毫秒。根据工作负载,Turin处理器的性能范围在2.5倍到5.4倍之间。
会上一同公布的还有Instinct GPU技术路线图,以及当前/未来AMD GPU同当前/未来英伟达GPU之间的性能比较。
苏姿丰首先介绍了相关基准测试,并重申“Antares”MI300系列已经成为AMD公司有史以来增长速度更快的产品。她最近在华尔街财报电话会议和其他活动中都曾反复强调过这一结论。之所以增长迅猛,一方面当然是因为其针对HPC和AI工作负载的优化设计让MI300 GPU在诸多方面都相当类似于英伟达GPU;与此同时,AMD提供的性能优势以及HBM内存容量/带宽还往往高于英伟达。
苏姿丰表示,对于面向700亿参数Llama 3大语言模型的推理类工作负载,配备8张MI300X GPU的服务器在性能上约为配备8张H100 GPU加速器的英伟达HGX设备的1.3倍。而在Mistral 7B模型上,单张Mi300X GPU的性能则可达英伟达H100 GPU的1.2倍。
展望未来,苏姿丰又展示了另一组幻灯片,其中提到MI300系列中CDNA 3架构的推理速度要比“Aldebaran”Instinct MI200系列GPU中应用的CDNA 2架构快约8倍。而对于即将推出的MI350系列GPU,我们猜测其将率先采用CDNA 4架构(甚至抢先于计划在明年推出的MI400系列GPU),因此推理性能可能相当于MI300中CDNA 3架构的35倍左右。
苏姿丰随后发出挑战,表示与英伟达的B200 GPU(预计将在2025年以Blackwell Ultra的名号推出)相比,MI350的内存容量将是后者的1.5倍,AI计算能力将是后者的1.2倍(通过FP8、FP6以及FP4精度混合基准测试量化得出)。
下面我们来看更新之后的AMD Instinct GPU技术路线图:

今年新增的MI325X将拥有更强大的计算能力,同时转而采用HBM3E内存。以下是我们目前知晓的关于这款GPU的所有规格:

它能在多大程度上提升计算能力仍然有待观察,但设备的有效吞吐量可能会翻倍,设备内存将实现倍增,带宽也将提升30%,在HBM内存上达到6 TB/秒。
以下是AMD将MI325X的馈送与速率同英伟达H200进行的比较结果,后者拥有141 GB内存复合体,与上代内存容量为80 GB的H100相比性能几乎翻了一番:

更重要的是,如今只要采用8块搭载MI325X GPU的系统板、每GPU配备288 GB HBM3E内存容量,即可运行起拥有1万亿参数的大模型。
MI325X将于今年第四季度上市,届时英伟达也将大量出货H200并少量供应B100 GPU。
也正因为如此,AMD方面才决定升级至CDNA 4架构并推出MI350X,其基于台积电公司的3纳米制程工艺,拥有288 GB的HBM3E内存并支持FP6/FP4数据类型。

届时还可能有MI350A乃至基于MI350的其他变体版本,毕竟AMD公司明确将MI350X称为“AMD Instinct Mi350系列的首款产品”。MI325X与MI350X采用的内存类型和容量相同,区别之处可能在于MI350X中运行的HBM3E可能吞吐速度更快,因此提供的带宽更大一些——实际数字可能会在7.2 TB/秒左右。
大家可能会好奇,为什么MI350X在2025年出货之时不采用HBM4内存。但根据现有相关报道,英伟达预计在2026年推出“Rubin”GPU之前也不会使用HBM4内存。从这个角度看,我们有理由相信2026年采用“下一代CDNA”架构的首批MI400系列才是HBM4内存的理想平台。
目前唯一可以确定的就是,为了能在明年之内进一步提高推理性能,CDNA 4架构已经被引入MI350,这也打破了Instinct GPU代际与CDNA架构级别之间的对应关系。如今2024年已经过去快一半了,这意味着无论MI400系列是要采用CDNA 4.5还是CDNA 5架构,具体技术方案现在都必须非常明确而且接近最终完成。
AMD在服务器CPU上击败英特尔似乎已经成为必然的结果,原因就是后者的代工规划失误已经彻底搞砸了其产品路线图。但要想在服务器GPU领域迎头赶上并超越英伟达则没那么简单,但AMD肯定取得了不错的势头,并且将在未来几年内继续保持高速前进。如果AMD能够逐一重现英伟达GPU的性能水平,并在无需修改的前提下承载起英伟达产品所能支持的各HPC和AI软件堆栈,就如同AMD能够接管英特尔CPU上运行的Windows和Linux工作负载一样,那么AMD从英伟达手中夺取半数市场份额将只是时间问题。当然,这里还有另一个前提,就是AMD能够拿到充足的封装配额和HBM内存供应。
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2024
06/04
16:28
分享
点赞

边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
Moonshot即将发布的Kimi K3有望赶超Anthropic Opus 4.8
OpenAI 为何开始卖 ChatGPT 品牌篮球?
DoorDash推出命令行工具,开发者可借助AI智能体直接下单
