
独辟蹊径 浪潮信息 “源2.0-M32”多维度提升模型算力效率 原创
对于大模型而言,无论是提高模型参数量还是提升数据规模,算力依旧是必不可少的核心驱动力。但是由此带来的成本投入是巨大的,我们以训练一个5000亿参数规模的Dense模型为例,其基础算力设施投入约10亿美元,无故障运行21个月,电费约5.3亿元。
当算力以及训练数据发展变缓,或者成本变高的时候,我们需要另外一种可以让模型能力继续进行扩展(scale)的创新方式。MoE(Mixture of Experts,混合专家模型)从本质上来说就是一种高效的scaling技术,用较少的计算实现更大的模型规模,从而获得更好的性能。

近日,浪潮信息发布“源2.0-M32”开源大模型。“源2.0-M32”在基于“源2.0”系列大模型已有工作基础上,创新性地提出和采用了“基于注意力机制的门控网络”技术,构建包含32个专家(Expert)的混合专家模型(MoE),并大幅提升了模型算力效率。
浪潮信息人工智能首席科学家吴韶华表示,源2.0-M32大模型通过算法创新和模型结构调整,实现了与LLaMA3-700亿参数模型相当的精度,但算力消耗只有1/19。在保证模型智能高水平的基础上,有效降低模型落地的算力门槛,从而为各行各业带来更高效、更经济的AI解决方案。
模型算力效率是关键
当前业界大模型在性能不断提升的同时,也面临着消耗算力大幅攀升的问题,对企业落地应用大模型带来了极大的困难和挑战。而大幅提升的模算效率将为企业开发应用生成式AI提供模型高性能、算力低门槛的高效路径。
吴韶华表示,模算效率是大模型的精度、能力和算力开销的衡量指标,效率越高意味着在单位算力投入的情况下获得精度回报越高。如果能够获得一个很高的模算效率,我们在更多的Token上面训练更大参数量的模型就变得可能。
浪潮信息关注大模型应用中的算力成本问题,通过模型结构创新来降低算力消耗,并推出支持多元芯片的工具,以满足企业对多元算力芯片的使用需求。为了大幅提升基础模型的模算效率,浪潮信息做了两个维度的工作——提升精度和降低同等精度水平下的算力开销。
源2.0-M32凭借特别优化设计的模型架构,在仅激活37亿参数的情况下,取得了与700亿参数LLaMA3相当的性能水平,而所消耗算力仅相当于LLaMA3的1/19,从而实现了更高的模算效率。此外,微调和推理的IT基础设施门槛和成本也得到了大幅度的降低,使得高智能水平的模型更加易于企业进行应用开发。
在算法层面,源2.0-M32采用源2.0-2B为基础模型设计,沿用并融合局部过滤增强的注意力机制(LFA,Localized Filtering-based Attention),并采用了一种新型的算法结构:基于注意力机制的门控网络(Attention Router)。
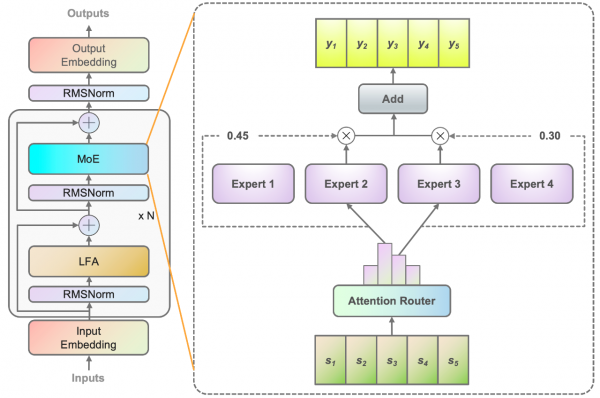
Attention Router门控网络通过创造一种专家间协同性的度量方法,能够使得专家之间协同处理数据的水平和效能大为提升,从而实现以更少的激活参数,达到更高的智能水平。
吴韶华说,选择20亿参数量的模型是控制单个专家的模型参数量,同样在企业场景应用中会有更好的模算效率。
在数据层面,源2.0-M32基于2万亿的Token进行训练、覆盖万亿量级的代码、中英文书籍、百科、论文及合成数据。高质量数据集是大模型预训练的核心,基于这些数据的整合和扩展,源2.0-M32在代码生成、代码理解、数学推理、计算求解等方面有着出色的表现。
在算力层面,源2.0-M32采用了流水并行的方法,综合运用流水线并行与数据并行的策略,显著降低了大模型对芯片间P2P带宽的需求,为硬件差异较大的训练环境提供了一种高性能的训练方法。“现实中的算力是有限的,我们要在这样的条件下让模型能力更快、更强。”吴韶华说。
加速大模型在行业应用中的落地
浪潮信息此次发布源2.0-M32大模型,不仅展示了其在算法和模型结构上的创新能力,也表明了其致力于推动大模型在行业应用中的落地。浪潮信息希望通过技术创新,让大模型成为企业发展的新动力。
吴韶华表示,浪潮信息的大模型客户分为两类:一类是外部客户,借助元脑生态,浪潮信息与合作伙伴在大模型的软件、工具、算法上面开展非常紧密的合作,一起赋能更多的行业客户。另外一类是开发者,让他们能够在笔记本上直接体验大模型的能力。
浪潮信息高度重视大模型在行业应用中的落地,为此推出了端到端的大模型开发平台“元脑企智”EPAI(Enterprise Platform of AI),旨在降低企业应用大模型的技术门槛。其中,EPAI支持主流开源与闭源大模型的应用快速开发,提供面向多模和多元算力的计算框架,能够实现大模型应用在跨算力平台上的无感迁移,降低多模、多元的适配与试错成本。
大模型可以赋能更多企业场景,浪潮信息持续探索如何让大模型与企业应用更好地融合,在内部大量业务场景中应用大模型。比如,在“智能客服大脑”加持下,浪潮信息突打造了专家级数据中心智能客服机器人。“这些经验会沉淀在EPAI平台上面,通过EPAI软件工具的提升,更好地服务外部客户。”吴韶华说。
好文章,需要你的鼓励


开创电气越南基地形成80万台手持式电动工具年产能力
今天讲的出海案例是开创电气,一家金华手持式电动工具制造商,在越南基地完成首款产品验收并形成80万台年产能力。

清华、浙大等高校联手破解AI智能体“只知结果不懂过程“的训练难题
清华、浙大等高校提出OPID框架,从AI自身完成的任务轨迹中提炼层级化经验技能,转化为密集训练信号,解决强化学习中稀疏奖励难以精细指导决策的问题。

一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

数AI也能画画?Surrey大学与Simon Fraser大学打造的“算盘“模型,让机器真正学会了“数数“
萨里大学与西蒙菲莎大学联合提出ABACUS模型,首次将物体计数、人群计数、指代计数与精准图像生成统一在单个30亿参数模型中,七项基准全面超越现有专业模型。

