
BLACKWELL GPU亮相:AI从此更便宜、更简单,英伟达竞争优势愈发凸显

如果还有人想在AI处理领域跟英伟达正面抗衡,那最好再多做几手准备。除了最强大的技术储备之外,大家可能还需要雄厚的资金支持和上天的意外眷顾。换句话说,如今压制英伟达的唯一可能性恐怕只有天降神迹。
日前在圣何塞举行的2024年GPU技术大会上公布的英伟达“Blackwell”GPU,是这家计算引擎制造商推出的第七代、也是最令人印象深刻的数据中心级GPU。GPU计算浪潮始于2000年代中期,并随着2012年5月“Kepler”K10与K20加速器的推出而变得愈发清晰具体。
从那时起,英伟达就一直不懈推动摩尔定律在晶体管、先进封装、增强向量与矩阵数学引擎设计、持续降低浮点运算精度以及增加内存容量/带宽等多个方面的进步,最终让自家的计算引擎实现了4367倍的恐怖提速。就原始浮点性能而言,与十几年前带有双GK104 GPU的初版K10相比,Blackwell确实带来了4367倍的性能增长(其中有8倍源自FP32单精度降至FP4八精度浮点运算,在恒定精度条件下的芯片性能增益为546倍)。
随着NVLink网络的进步,超大规模基础设施运营商、云服务商、高性能计算(HPC)中心以及其他机构可以将数百个GPU的内存与计算资源紧密结合在一起。而随着InfiniBand和以太网网络的发展,数以万计的GPU则能够松散地捆绑在一起以建立功能极其强大的AI超级计算机,从而更快地运行HPC与数据分析工作负载。
“Blackwell”B100与B200 GPU加速器分别较2022年和2023年推出的前代“Hopper”H100与H200 GPU快多少,目前仍有待观察。本文撰写于英伟达联合创始人兼CEO黄仁勋发表的主题演讲之前,因此许多架构及性能细节尚未明确披露。我们将针对搭载Blackwell GPU的系统带来后续报道,并对这款全新GPU的架构和经济性开展深入研究,将其与英伟达自家的前代产品,以及AMD、英特尔及其他厂商的计算引擎进行比较。
AI正在架构层面牢牢占据主导地位
如果说HPC领域对于更高浮点性能与更低能耗的需求,推动了英伟达的初始计算设计。那么自2016年“Pascal”一代添加半精度FP16单元以及随后的张量核心矩阵数学单元以来,机器学习开始为GPU巨头定下新的发展基调。短短一年之后的2017年,以深度学习神经网络为代表的机器学习工作负载成为英伟达的架构选择依据,并在“Volta”这代GPU上将这种思路奉为圭臬。
随着Hopper乃至最新这代Blackwell计算引擎的出炉,面向生成式AI的大语言模型则进一步推动架构的发展,强调不断压缩更大规模AI训练与推理工作负载的处理成本。
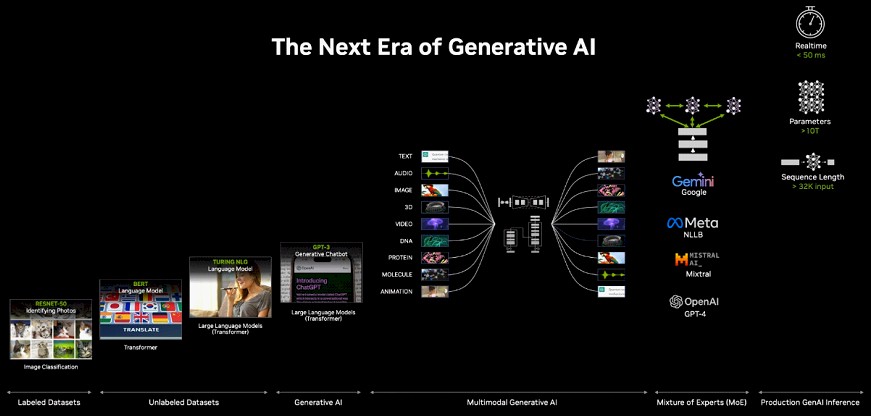
英伟达公司超大规模与HPC副总裁Ian Buck在大会前的简报中解释道,“在过去的2023年,我们经历了多模态生成式AI的诞生,文本到图像、图像到文本、音频到3D模型等——而且不止于人类可读模态,气候、DNA、分子、蛋白质与药物发现等科学领域也有AI的身影。在此过程中,一种新型AI正在出现。这类模型更加智能,它不再是以孤立的模型形式存在,而开始成为AI模型集合,即混合专家模型——其中的代表包括谷歌Gemini、Meta NLLB、Mistarl AI,当然还有如雷贯耳的OpenAI GPT-4。这些新模型实际上包含多个协同运行的AI模型。在transformers的每一层,它们都会共享信息以决定谁能为下一层提供最佳答案,由此构建的模型也在智能度方面更上一层楼。这使得AI得以进一步扩展至万亿参数级别,带来我们前所未见的规模与性能表现。当然,这也给计算带来了新的挑战。随着模型体量变得越来越大,训练过程需要消耗更多算力。此外,推理也开始成为挑战中越来越重要的组成部分。”
而Blackwell正以各种形式站上历史的舞台,希望以全面超越Hopper的方式从容应对这所有挑战。
(第七代GPU计算引擎以David Blackwell命名,他是美国国家科学院院士、加州大学伯克利分校前教授,研究领域包括博弈论、信息论以及概率与统计。)
Blackwell GPU拥有2080亿个晶体管,采用台积电4纳米工艺的改良版本4NP进行制造——即英伟达用于制造Hopper GPU的定制化4N工艺的改进形式。Blackwell GPU实际上由双reticle GPU芯片组成,其各自包含1040亿个晶体管,并使用NVLink 5.0互连沿芯片中央像拉链般将二者连接起来。

由于台积电的3N 3纳米工艺仍存在明显问题,因此英伟达暂时无法使用这种最新制程,所以Blackwell芯片的尺寸和发热量可能仍停留在较高水平。此外,Blackwell GPU的时钟速率也许亦未达到理论最佳值。但每块Blackwell芯片的浮点性能仍将比Hopper芯片高出25%左右,再加上每个封装中包含两块GPU,因此总性能将提升至2.5倍。降至FP4八精度浮点运算还可将性能再次翻倍,使其原始性能提升至Hopper的5倍。实际处理工作负载时的性能可能会更高,具体取决于各个Blackwell版本上的内存容量与带宽配置。
Buck解释称,Blackwell GPU计划于今年晚些时候投放市场,而且这款最新产品的实现依托于六大核心技术:

两块Blackwell芯片通过10 TB/秒NVLink 5.0芯片到芯片链路实现互连,简称为NV-HBI(全称可能是高带宽互连)。更重要的是,Buck确认这两块芯片在软件中将以单一GPU的形式存在,而绝非像英伟达及竞争对手AMD此前发布的GPU那样彼此独立。
这一点非常重要,因为如果一块GPU能够以单一单元形式存在,那么在编程时就可将其视为整体。而如果网络能够将其作为整体直接访问,也就意味着其在集群内可以灵活扩展。相比之下,彼此独立的两块GPU在集群扩展方面则比较麻烦(具体性能损失取决于网络与各芯片间的通信方式,而且在最极端的情况下,可能导致集群算力减少一半)。
我们对B100和B200设备的具体馈送及速度参数了解不多,但目前可以确定的是高端Blackwell芯片的所有功能均已开启(但不确定是否所有B200版本均提供全功能),配备192 GB HBM3E内存,在封装内对应每个Blackwell芯片上四个8-Hi堆栈。如果我们认真观察,就会发现它实际上分八个计算复合体被封装在两块芯片中,每个芯片对应一组HBM3E内存。而根据此前媒体的报道,这192 GB内存将由SK海力士与美光科技提供,其综合内存带宽可达8 TB/秒。

2022年推出的H100在5个堆栈间提供80 GB内存容量与3.35 TB/秒带宽;升级版H100则与同样由英伟达制造的“Grace”CG100 Arm服务器处理器搭配,共包含6个内存堆栈,容量和传输带宽分别为96 GB及3.9 TB/秒。从比较乐观的角度比较,高端Blackwell与普版H100相比实现了内存与传输带宽的双重2.4倍提升。而如果与开启全内存容量模式的中端H100比较,那么英伟达计划于今年推出的高端Blackwell内存容量提升至2倍,传输带宽则略高于2倍。至于跟拥有141 GB HBM3E内存与4.8 TB/秒带宽的H200进行比较,那么高端Blackwell的内存容量只高出36.2%,但传输带宽倒是高出66.7%。
我们猜测,英伟达有可能采用4 GB HBM3E内存并采用8-Hi堆栈,也就是说8个内存堆栈中只实际启用6个即可达到192 GB容量。由此推测,Blackwell封装实际可以提升至256 GB HBM3E内存容量与13.3 TB/秒传输带宽。这种理论上限可能同时适用于B100和B200,也可能单纯适用于B200。英伟达目前尚未给出说明,我们将继续拭目以待。
Blackwell复合体还配备有NVLink 5.0端口,能够提供1.8 TB/秒的传输带宽,相当于Hopper GPU上NVLink 4.0端口的两倍。
与英伟达近期推出的所有GPU计算引擎一样,其性能提升不仅仅靠在芯片中完稿更多的触发器和内存空间来实现。英伟达还对芯片架构进行了优化,旨在适应特定的工作负载。以Hopper为例,我们看到了Transformer Engine的第一次迭代,能够为张量提供自适应精度范围以加快计算速度。Blackwell则带来改进后的第二代Transformer Engine,能够在张量之内进行更细粒度的精度缩放。Buck解释道,正是这项功能实现了FP4性能,其主要用于提高生成式AI推理工作负载的吞吐量,从而降低这类当红负载类型的处理成本。
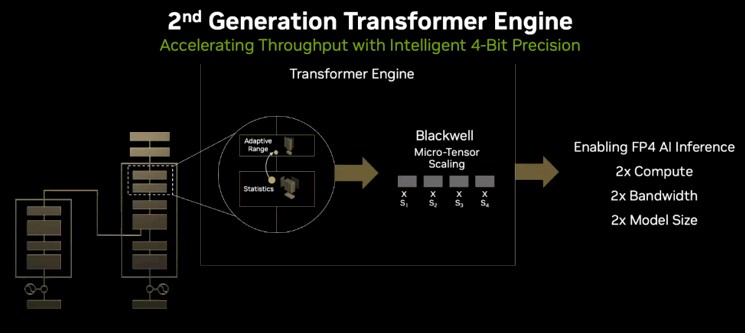
Buck指出,“Transformer引擎最初是由Hopper所发明,作用是在计算过程中跟踪整个神经网络中各张量的每个层上的准确性与动态范围。随着模型训练进度的不断推进,我们会持续监控每个层的范围,并随时调整以保持其数值精度处于合理范围之内,借此获取最佳性能。在Hopper当中,这种跟踪调整最高可扩展至1000路记录,计算更新及缩放因子来保证整个计算令以8位精度执行。而在Blackwell架构中,我们又更进一步在硬件层面调整每个张量的缩放比例。不同于以往的整个张量,Blackwell现可支持微张量缩放,我们不仅可以监控整个张量,更能够查看张量内的各个元素。不止于此,Blackwell的第二代Transformer Engine还允许我们将AI计算带入FP4精度,即仅使用四位浮点表示来执行AI计算。每个神经元、每条连接都只用4个0和1表示——因此可以表示数字1到16。达到这种细粒度水平本身就堪称奇迹。第二代Transformer Engine与Blackwell微张量缩放相结合,意味着我们可以提供两倍于以往的算力,而且8位到4位的成功减半也让我们的有效带宽得以加倍。如此一来,单个GPU也能容纳双倍于以往规模的模型。”
英伟达方面并没有公布Blackwell芯片上32位与64位CUDA核心的具体性能,也没有讨论更高精度数学如何在该芯片的张量核心上享受性能优势。期待这些问题的答案能够在本届大会上一一揭晓。
目前可以明确的是,B100的峰值FP4性能为14千万亿次,且采用与前代H100相同的700瓦热功率设计。B200的FP4性能则为18千万亿次,功率为100瓦。Buck还私下告诉我们,即将推出的GB200 NVL72系统将为GPU提供液冷支持,其运行功率为1200瓦。据推测,液冷应该能够在同等功率下提供更高的性能输出。
英伟达也未公布B100、B200或者其HGX B100系统板的定价。这些系统板能够直接插入现有HGX H100服务器,这是因为二者的发热量和功率相同,因此配备的散热装置也没有区别。我们预计与HGX H100相比,HGX B100的价格至少会高出25%。粗略计算,在同等运算精度之下,HGX B100的价格约在25万美元,性能约为H100的2.5倍。当然,考虑到当初Hopper GPU的情况,市面上的实际售价恐怕会远远高于英伟达的官方指导价。
在后续报道中,我们将具体探讨Blackwell系统以及NVLink Switch 4与NVLink 5端口,敬请期待!
好文章,需要你的鼓励



中科大团队解决动画制作痛点:让AI记住角色原本的颜色,实现超长动画自动上色
中科大团队开发出LongAnimation系统,解决了长动画自动上色中的色彩一致性难题。该系统采用动态全局-局部记忆机制,能够为平均500帧的动画进行稳定上色,性能比现有方法提升35-58%。核心创新包括SketchDiT特征提取器、智能记忆模块和色彩优化机制,可大幅提升动画制作效率。

多智能体系统如何革新数据工作流程
传统数据工程面临数据质量差、治理不善等挑战,成为AI项目的最大障碍。多智能体AI系统通过协作方式正在彻底改变数据准备、治理和应用模式。Google Cloud基于Gemini大语言模型构建协作生态系统,让不同智能体专门负责数据工程、科学、治理和分析等任务。系统通过分层架构理解组织环境,自主学习历史工作流程,能够预防问题并自动处理重复性任务,大幅提升效率。

南开大学团队推出DepthAnything-AC:让AI在恶劣天气中也能精准“看懂“距离
南开大学团队开发出DepthAnything-AC模型,解决了现有AI距离估算系统在恶劣天气和复杂光照条件下性能下降的问题。通过创新的扰动一致性训练框架和空间距离约束机制,该模型仅用54万张图片就实现了在雨雪、雾霾、夜晚等复杂环境下的稳定距离判断,同时保持正常条件下的优秀性能,为自动驾驶和机器人导航等应用提供了重要技术支撑。
2024
03/19
13:43
分享
点赞

微软研究院重磅发现,Data Efficacy:AI学习顺序和学习内容同等重要!
多智能体系统如何革新数据工作流程
微软推出业务级AI微调服务助力企业价值创造
CEO预言白领替代潮:白领零工经济时代来临
AI与E Ink技术也无法让触屏触控板成为好创意
Wonder Dynamics联合创始人将出席2025年TechCrunch Disrupt大会AI舞台
以色列量子初创公司Qedma融资2600万美元,IBM参投
GoTo高风险云迁移如何助力其AI未来发展
Meta的"AI超级智能"愿景听起来就像失败的"元宇宙"
VodafoneThree与Currys签署独家多年合作协议
低功耗芯片供应商Ambiq Micro申请公开上市
AI模型其实并不理解它们在说什么
