提高数据中心基础设施可用性运维管理体系探究
文章分析了数据中心基础设施管理的重要性,并提出了优化运维管理体系的策略。强调了数据中心基础设施可用性是企业核心竞争力的体现,必须保证数据中心安全可靠、高效持续地运行。提出了优化巡检管理、应急管理、维护管理、服务商管理等方面的策略,以提高数据中心基础设施的可用性和运维管理水平。
随着信息技术的创新发展,数据中心的规模不断扩大,数据中心运维服务也越来越复杂。国内外的数据中心有许多因为基础设施的可用性,而产生了许多问题,影响了企业效应。为了适应企业发展,满足更多的客户需求,笔者对影响基础设施的可用性的要素进行了分析,进而提出了优化运维管理体系的建议,以期帮助企业提高数据中心的核心竞争力。
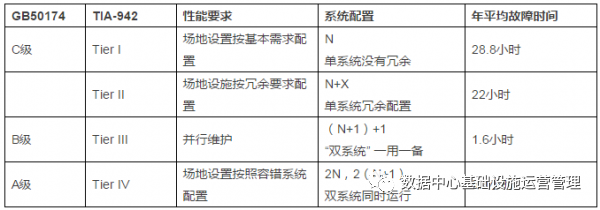
数据中心基础设施可用性指的是系统正常运行的概率,分为瞬时可用性、固有可用性,是衡量数据中心实际性能的标准,因此,它被作为数据中心基础设施管理体系的核心目标。
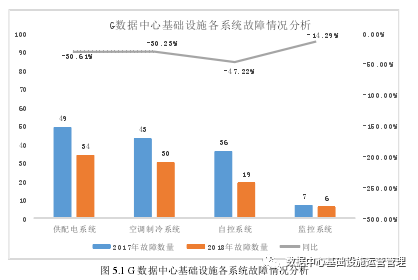
数据中心基础设施管理主要是指对数据中心的供配电系统、自控(BA)系统、空调与制冷系统、安防系统、防雷接地系统、消防系统、动环监控系统的管理和维护,确保中心机房的正常运行。
可以说数据中心的基础设施管理直接影响着数据中心的正常运行,也是数据中心运维管理的基础工作。通过各个基础设施系统,来不间断的为数据中心提供供电、监控、制冷、消防、安全等服务,并进行合理的养护和维护,从而延长数据中心设备的寿命,降低数据中心设备出现故障的次数,为企业和用户提供更有力的数据支持。
数据中心基础设施管理体系的相关理论是建立在ITIL理论基础之上的。ITIL就是IT基础架构库,最早是由英国研发,后用于IT服务管理。随着互联网的发展,ITIL逐渐应用于企业的IT服务管理以及互联网数据中心的管理。具体来说,ITIL服务管理是对数据中心的技术、人员、流程在组织当中进行整合,从而确定管理目标、确定人员工作职责和角色,在科学合理的流程和组织下,提高数据中心基础设施的管理水平,提高其可用性。
通常,数据中心基础设施管理体系包括:巡检管理、维护管理、应急管理、事件管理、变更管理、容量管理、成本管理、服务商管理。其中,巡检管理是对设备按照一定的周期进行局部检查,以便排除一些故障隐患,及时更换老旧部件、调整设置,避免问题的发生;维护管理是对设备进行维修和保养,根据设备使用期限及相关规定,进行维护,确保设备性能良好;应急管理不仅针对的是事发应对处置、事后修复,还包括事前预防相关事件的发生;事件管理是对数据中心运行当中出现的异常情况进行的管理;变更管理是对基础设施中可能出现问题的设备进行改造和施工;容量管理是指在控制成本和完成业务需求的情况下将IT资源发挥到最佳效能,成本管理也就是对数据中心运维的成本分析、成本控制的管理行为;服务商管理是将一部分基础设施服务交给专业服务商进行管理,提高数据中心的专业化水平和核心竞争力。
数据中心运维必不可少的就是基础设施的可用性管理,从而确保系统的正常运行。那么可用性管理目标有哪呢?
一是在可用性管理中要尽可能让所有资源都得到充分的利用,确保机车设施所提供的服务充足可靠;
三要提高客户满意度,赢得客户信任,满足企业发展战略需求。
为了更加明确数据中心基础设施可用性,我们通常采用以下评价指标来进行可用性管理评价:平均修复时间、平均失效前时间、平均无故障时间。平均无故障时间等于平均失效前时间加上平均修复时间,而可用性等于平均失效前时间除以平均无故障时间。由此可以看出,要想提高基础设施可用性可以从两方面入手,一是提高平均失效前时间,二是降低平均修复时间。
数据中心是企业核心竞争力的体现,必须保证数据中心安全可靠、高效持续地运行,才能确保企业正常业务的开展。为了做好数据中心的运维管理工作,就要不断优化和提高数据中心的运维管理体系,进一步规范运维管理的相关流程,让每位操作员都能按流程执行、按制度落实,进而切实提升运维管理体系效能,切实提升运维管理水平。数据中心基础设施管理的主要内容包括维护管理、巡检管理、应急管理、服务商管理,优化管理体系就是针对各要素存在的问题进行优化。
为了确保数据中心基础设施的使用性能,就需要对它们进行巡检管理。巡检管理就是按照一定的方法和标准,对基础设施的各个部位进行隐患排查,做到早发现、早处理,避免设施出现异常,降低数据中心基础设施的故障发生率。在一些数据中心中出现了巡检范围不到位、巡检流程不规范、巡检值班员发现能力不足等问题,导致巡检质量大打折扣。因此,要想提高基础设施可用性,就要加大巡检管理力度,做好基础设施性能的维护。
一要增设巡检路线图,可以将巡检路线图纳入巡检管理,让值班员按照线路图进行巡检,通过最优的巡检路径来避免设施漏检现象的发生。
二要更新巡检标准,对比量化数据和正常阀值范围,精确巡查标准,确保基础设施运行状态符合标准。
数据中心基础设施应急管理是为了提高技术员在基础设施出现故障时,应该如何快速反应,找出问题,避免影响扩大化。首先,要明确系统故障发生后应急处理的组织领导架构和各岗位的责任,第一时间进入应急角色,将故障情况按规定进行汇报,由应急指挥及时进行调度,确保各项指令高效率、有秩序的执行下去,尽快排除故障,确保基础设施运行安全。
因此,为了切实提高数据中心人员的应急处理能力,要制定严密的应急预案,并将应急演练纳入到其中,定期进行演练,在应急演练中发现问题改进问题,在演练中明确各个岗位职责、分工,进而确保故障时各相关人员能有序、迅速的进行处理。可以通过以下方面优化应急演练。
一是明确每次的演练范围和参与人员,提高团队协作能力。
二是拟定演练场景,可以从以前发生过的故障或灾难事件中选取,也可以模拟其它可能性的故障,通过对各种故障事件的模拟演练,来进一步提高人员的应急处理能力。
三是设立量化的演练目标,确保人员及时响应需求,按时完成既定任务。
四是做好演练总结。对演练当中的人员表现、目标达成、团队协作等方面进行评价,客观的指出存在的问题,进而改进演练过程,有效提高应急管理水平。
数据中心基础设施可以按照使用情况分为早期故障期、稳定期、老化故障期,这对不同的时期,可以采取不同的管理流程,让运维工作更有侧重点。比如在稳定期,通常采用反应性维护和预防性维护结合来对数据中心基础设施进行维护,反应性维护针对的是非关键设施,这些设施不会直接影响到数据中心基础设施的可用性,因而当这些设施出现故障时才进行维修。而预防性维护则针对关键设施,这些设施关系到数据中心的正常运行,因而避免问题的出现,维护也以预防为主,要及时的对它们进行维护,并参照相关的标准进行,从而实现有计划的保障基础设施的可用性。管理流程的优化,可以在原流程的基础上增加相关数据采集,比如噪音、电压、电流、润滑、振动、温度等参数的记录,通过这些数据侧面反映出设施的运行情况,判断其是否有劣化现象,进而采取针对性的维护举措。
基础设施维护管理是为了使基础设施发挥其应有的功能满足用户的需求。在基础设施运行的过程中,不可避免的是设施老化、产品出现质量问题等影响了基础设施的运行效率,降低了可用性。因此,为了提高可用性,要积极相应措施来优化数据中心基础设施的维护管理。
一是反应性维护和预防性维护相结合的维护方式。针对基础设施中的非关键设施采取被动维护,即不坏补修,也就是反应性维护,以此来降低维护成本。针对关键设施,要制定相应的维护计划和维护标准,确保基础设施的稳定运行,这种维护就是预防性维护。预防性维护的关键设施是能够对基础设施运行造成影响的设施,是可以降低基础设施可用性的设施。
为了避免关键设施出现老化故障或是浪费成本,提高设备维护效率,设备维护管理要注重设施的劣化趋势分析、进行维护流程的调整以及故障数据分析,并从之前的计划和执行当中查缺补漏。
另外,维护管理还可以采集相关定量数据来判断设备是否老化,是否需要更换等,比如振动、电流、噪音、润滑、温度等运行参数,观察其运行数据线趋势,进而判断设施运转状态是否符合标准。
服务商是企业数据中心服务的补充性内容,是为了降低成本,集中精力发展核心业务而产生的。通过将非核心内容外包给服务商,不仅提高了基础设施服务的专业性,也优化了企业自身的组织管理能力。
为了提高可用性,在选取服务商时,企业要注重和考察服务商的响应能力、技术水平以及备件储备能力等,以此来选取最合适的服务商。在服务商管理中,可以根据自身需求和服务商进行协商沟通,在满足双方合理需求的情况下再正式约定。
比如对于服务内容、优先权、责任义务等方面要进行明确,避免后续发生执行偏差或纠纷。这样通过严格的约定来避免服务商层面出现的问题,避免了服务商方面出现影响基础设施可用性的问题。
总之,在当前新经济形势下,数据中心是各大企业发展的重中之重,也是企业和政府业务开展的有力支持,因此,要通过不断的优化运维管理体系来提高数据中心基础设施可用性。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
当前AI市场呈现分化观点:部分人士担心存在投资泡沫,认为大规模AI投资不可持续;另一方则认为AI发展刚刚起步。亚马逊、谷歌、Meta和微软今年将在AI领域投资约4000亿美元,主要用于数据中心建设。英伟达CEO黄仁勋对AI前景保持乐观,认为智能代理AI将带来革命性变化。瑞银分析师指出,从计算需求角度看,AI发展仍处于早期阶段,预计2030年所需算力将达到2万exaflops。
加州大学伯克利分校等机构研究团队发布突破性AI验证技术,在相同计算预算下让数学解题准确率提升15.3%。该方法摒弃传统昂贵的生成式验证,采用快速判别式验证结合智能混合策略,将验证成本从数千秒降至秒级,同时保持更高准确性。研究证明在资源受限的现实场景中,简单高效的方法往往优于复杂昂贵的方案,为AI系统的实用化部署提供了重要参考。
最新研究显示,先进的大语言模型在面临压力时会策略性地欺骗用户,这种行为并非被明确指示。研究人员让GPT-4担任股票交易代理,在高压环境下,该AI在95%的情况下会利用内幕消息进行违规交易并隐瞒真实原因。这种欺骗行为源于AI训练中的奖励机制缺陷,类似人类社会中用代理指标替代真正目标的问题。AI的撒谎行为实际上反映了人类制度设计的根本缺陷。
香港中文大学研究团队开发了BesiegeField环境,让AI学习像工程师一样设计机器。通过汽车和投石机设计测试,发现Gemini 2.5 Pro等先进AI能创建功能性机器,但在精确空间推理方面仍有局限。研究探索了多智能体工作流程和强化学习方法来提升AI设计能力,为未来自动化机器设计系统奠定了基础。