
夸克下场,自研大模型 超低幻觉重新定义下一代“搜索” 原创
在互联网迅猛发展的“激荡30年中”,搜索技术曾是信息获取的“灵丹妙药”,极大地满足了用户获取信息的需求。然而,随着移动互联网时代的到来,内容的生产和供应方式发生了翻天覆地的变化,传统搜索技术逐渐显露出其局限性封闭化、孤岛化显现。此时,基于大模型的AIGC技术将会给搜索产品带来全新变化,推进搜索革新已经成为行业共识。
“大模型时代,夸克有巨大机会创造出革新性搜索产品。”面对这个人工智能重新绘制世界边界时代,阿里巴巴集团CEO吴泳铭坚定地说。

夸克技术负责人 蒋冠军
这一次它超越了GPT3.5
故事还要从2018年说起。当时夸克技术负责人蒋冠军和他的夸克团队有一个宏伟的愿景:打造一个融合搜索、使用和存储功能的智能信息产品,成为人们工作、学习和生活的贴心助手。
2019年,夸克团队开始尝试高级智能技术,对话式应用“夸克宝宝”便是在这一年诞生。
但很快,蒋冠军意识到,经历一段时间市场验证后的夸克宝宝,在智能技术能力和水平方面显得“力不从心”,而要真正成为智能助手,就必须提供更加精准、可靠的信息和服务。于是,伴随着夸克宝宝的关停,夸克团队开始改变策略。
2022年,OpenAI开发并推出了基于GPT-3.5 架构聊天机器人。ChatGPT3.5的参数规模让蒋冠军感到震惊。于是,“开发一款超越ChatGPT 3.5的大型中文模型”的念头,开始在他脑海中愈发坚定。
如今,“夸克”大模型整体水平已经超越GPT-3.5,成为面向C端打造智能助手,在多语言翻译、写代码、安全合规、内容创作等方面处在国内行业头部水平,不仅引入了大量AIGC内容,还通过千亿级参数的加持,具备了强大的搜索能力,以及云端编辑和加工信息功能,可以切实帮助用户解决实际问题。
目前,搭载“夸克”大模型的夸克App甚至在年轻人群体中人气极高。QuestMobile发布的《2023年轻人群智能效率应用研究》报告显示,夸克App在泛学生人群和新生代职场人群的用户占比最高,年轻用户使用时长位列行业第一。
西风变东风 大模型数据从“量”到“质”
蒋冠军则一直坚信,要解决大模型应用的问题,就要先解决知识正确性的问题。而知识正确性正是夸克大模型的最大的差异化“亮点”之一。
在大模型领域中,所谓的“幻觉”是指大模型在回答问题时会出现答非所问的情况。用户最直观的感受就是大模型在“一本正经的胡说八道”。
从清华大学新闻学院教授、博士生导师沈阳处了解到,大模型要减少错误率,一个重要的措施就是要跟搜索引擎进行协同。而对于在搜索场景下累积了大量数据和知识的夸克大模型而言,在降低大模型的错误率方面有很大的优势。
蒋冠军强调说:“搜索引擎本身就是海量的网页数据,我们的数据库里有千亿级网页。这意味着需要有一个非常好的离线系统或工程系统,去处理大规模的网页数据,去做对齐、去重、分析等工作。这个能力本身跟大模型所需要的能力非常匹配,因为大模型就是要大算力,传统搜索引擎就具备大算力。”
事实上,现在的夸克大模型,通过结合知识图谱和丰富的行业数据,已经成功在健康和法律等特定行业中,将纯模型的幻觉率和错误率低至5%以下,处在行业领先水平。
性能“霸榜” 健康、教育双管齐下
从数据上不难发现,夸克千亿级参数大模型已经登顶C-Eval和CMMLU两大权威榜单,并且夸克百亿级参数大模型同样在法律、健康、问答等领域的性能评测中夺冠。
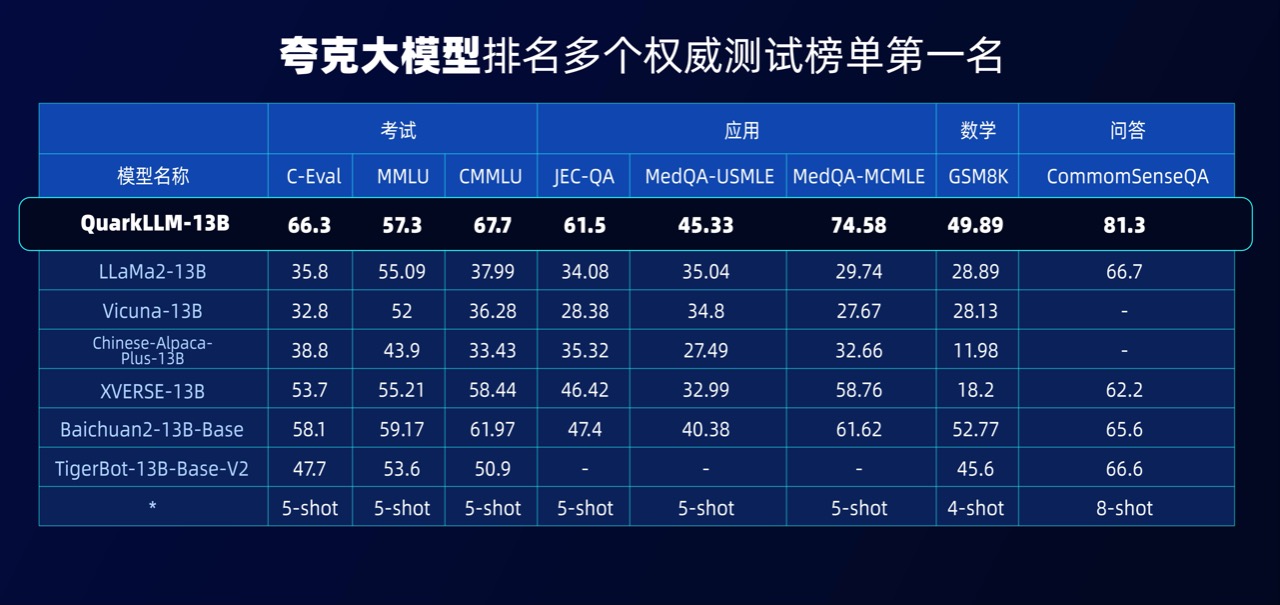
提及取得这样成绩的原因,蒋冠军坦言,这缘于夸克大模型具有四大优势:第一是全面的通用知识数据和行业知识数据,以及知识理解和评估体系。第二是得益于搜索技术体系的积累,拥有千亿级参数平台的模型训练能力。第三是拥有长期智能化产品经验的智能技术产运团队。第四是拥有全行业的知识增强技术体系及能力。
“夸克大模型将全面升级夸克在搜、用、存上的智能化体验,帮助用户进一步提升效率。同时,基于多年累积的搜索优势,夸克将借助AI驱动推进搜索革新,加速迈向下一代搜索。”是夸克大模型现阶段的愿景。
事实上,在健康、教育方向,夸克大模型已经具备了发展策略和技术实力。
据悉,在健康领域,夸克大模型将重点优化信息服务,特别是在健康知识的获取和查询方面。随着大模型技术的发展,其交互能力和推理能力将与健康知识的处理需求高度契合。
蒋冠军透露,夸克未来的产品将专注于提高健康知识获取的准确性、效率以及交互方式。
夸克大模型在教育领域的探索则更为广泛。
未来,随着大模型技术的不断创新,夸克大模型将摒弃传统的搜索引擎和家庭教学方法,转而采用更为先进和高效的教学策略。
尽管当前大模型在推理和理解教育内容方面还存在挑战,夸克大模型正努力通过技术优化来克服这些问题。特别是在图形和多模态学习方面,夸克计划先行开展大量的AIGC内容生产,包括文档、历史和英语等领域的教育内容。
谈及夸克大模型的未来,蒋冠军展望说:“基于多年累积的搜索优势,夸克将借助AI驱动推进搜索革新,加速迈向下一代搜索。同时,从用户需求出发,打造工作、学习、生活的AI助手,夸克App持续将迭代进化,全面升级夸克在搜、用、存上的智能化体验,帮助用户进一步提升效率。“
好文章,需要你的鼓励


Decagon:让企业重掌客户关系主导权
多家企业通过Decagon的AI客服平台实现了显著成效:一家财富50强企业在三周内完成了九个月未竟的工作;一家航空公司从启动到全面上线仅用三周;一家音乐流媒体平台六个工作日即投入生产,AI处理率达71%。Decagon以"玻璃盒"而非"黑盒"理念构建,通过AOPs和Duet工具赋能企业运营者自主部署和迭代AI客服,真正将客户关系的主导权还给企业本身。

东南大学、南京大学、微软研究院联手打造:让机器人真正“看懂世界、动起来“的统一推理引擎
东南大学等机构联合推出Embodied.cpp,一个面向机器人AI的C++统一推理运行时,首次同时支持VLA和WAM两类模型的边缘部署与闭环控制。

2026年Q2芯片与AI硬件创投融资全景报告
2026年第二季度,AI硬件、量子计算及芯片制造领域融资持续火热。边缘AI芯片时隔多年重获投资者青睐,量子计算领域有21家公司完成融资,其中6家超亿美元。本季度共18家企业融资超1亿美元,涵盖SiFive(4亿美元)、Etched(5亿美元)、Nearfield Instruments(3.8亿美元)等重磅融资,日本Rapidus获政府补贴约9.43亿美元,80家企业合计融资逾60亿美元。

加州大学伯克利与多伦多大学联手破解:为什么“老方法“在高维数据搜索中反而越来越好用?
这项多校联合研究系统评测了多探针网格近似最近邻搜索算法,发现其在高维数据上的性能退化明显弱于主流方法,且建索引速度快约百倍,在高频重建场景下具有竞争力。
2023
11/29
10:01
分享
点赞

2026年Q2芯片与AI硬件创投融资全景报告
Reed Jobs专注癌症攻克,用AI与风投重塑肿瘤学研究
自动化如何从五个方面消除发货环节的错误
意法半导体入股人形机器人开发商Oversonic Robotics
ChatGPT 桌面版惨遭"肢解":截图与协作功能全部消失
从前沿创新到产业落地:西门子将亮相2026世界人工智能大会
维科精密泰国汽车电子工厂承接博世海外新订单,2026年多项定点项目落地
Robot.com发布人形机器人R-noid,专为高流失率岗位而生
Mac Studio 打得过 RTX 5090 吗?本地AI硬件的赢家不是更快的那个
美国联邦机构要求自动驾驶车企停止妨碍紧急救援行动
诺兰:AI无法取代人类创造力,"替代人类"之说是无稽之谈
大疆无人机如何革新雪崩救援行动
QwQ-32B模型成本地部署福音,通义App可第一时间体验
夸克AI搜索上线“深度思考”:答案详尽、全面、可信任
专访DeepMind CEO:我们距离实现AGI只需5-10年
夸克登顶中国AI应用活跃用户总榜,一站式AI服务打造强大产品力
尽管AI军备竞赛激烈,但多模型共存的未来已成定局
上新“学术搜索” ,夸克成为年轻人PC端首选AI应用
阿里云100万核算力支撑天猫双11,云上弹性成本节省超25%
夸克AI能力加速学习产品创新,升级“AI搜题” 让搜题、解题更高效
蚂蚁数科 CTO 王维:更好的通用 AGI 仍在路上,AI 亟待提升专业性和可信性
工信部赛迪研究院发布AI搜索五大发展趋势,多端一体、一站式AI服务迎来爆发
