
IBM AI存储:算力稀缺时代的“破局者”
算力稀缺时代,存力大有可为
 作者:周立旸,IBM 大中华区科技事业部存储软件产品总监
作者:周立旸,IBM 大中华区科技事业部存储软件产品总监

北京2023年11月21日 /美通社/ -- 2023年11月,业界“又双叒叕“发布了数款重磅 AI 基础架构产品。算力方面,英伟达(NVIDIA)发布了号称“史上最强”的新一代AI芯片H200,和上一代产品相比,显存容量几乎翻了一番,性能提升了60% 到90%。存力方面,IBM同样发布了新一代 Storage Scale System 6000(SSS 6000),这是一个旨在满足数据密集型和 AI 工作负载需求的云规模全球数据平台,单个模块可提供超过 256GB/s 的吞吐量和 5M IOPS 的文件访问性能,分别超过市场领先竞争对手 2.5 倍和 2 倍,能够满足多个并行的 AI 工作负载和数据密集型工作负载对极高的数据访问速度要求。

IBM Storage Scale System 6000
IBM 在2022年发布的Storage Scale System 3500(SSS 3500)数据存储,单个模块24块NVMe SSD可以提供超过125GB/s 的数据访问性能,已经大幅领先于大部分 AI 存储产品,IBM为何要推出更高性能的 SSS 6000呢?
算力和算法的发展,需要更快速的数据访问
人工智能是算法、数据、算力的有效结合,近年来大模型训练和推理、多模态 AI等领域的突破更是得益于高质量数据的发展。随着数据集规模不断增加,应用程序载入数据花费的时间越来越长,进而影响了应用程序的性能,因为存力不足导致的低效I/O使得运算速度日益提升的GPU无用武之地。为了满足不断提高的算力和各种基础模型对更大参数规模的需要,也需要提供更高速的数据访问能力。
举例来说,在目前主流的NVIDIA H100/H800 平台上,运行一个大小为30TB的图像数据集用于AI训练,每颗GPU所需的数据存储访问性能就超过了4GBps,运行更大规模的数据集的应用或支持多种负载的智算平台可能需要数百GBps到数TBps的高速数据存储才能满足其对存力的需求。经过充分优化的 IBM Storage Scale System 可以充分发挥并行架构和高速网络的优势,加速各种 AI 工作负载应用。
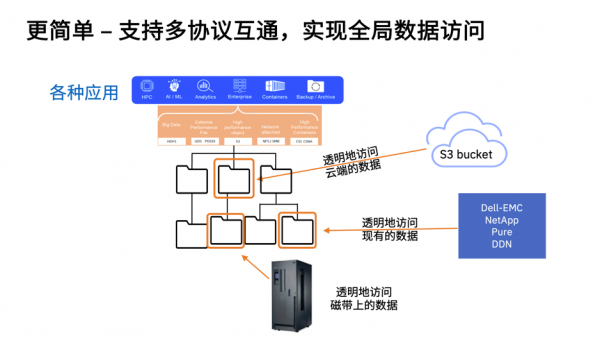
此外,不仅仅是训练环节,对于AI应用来说,从数据摄入到生产推理,每个环节都需要利用不同工具实现海量数据处理,并且这是一个不断重复的流程。用户需要构建的端到端的高速数据管道,简化流程并实现数据安全、高效的流动。基于IBM Storage Scale软件多协议互通的全局数据平台能力,用户可以在不同地点通过不同接口访问同样的数据,减少创建不必要的数据副本并通过智能的缓存技术减少数据传递的网络开销,整合来自核心、边缘和云端的宝贵数据资源。

AI应用全流程
算力短缺时代,需要提高GPU资源的利用率
随着通用型人工智能和大模型的发展,目前包括中国公司在内的全球AI公司都存在算力短缺的情况,英伟达等主要供应商的中高性能 GPU更是“千金难求”。对于拥有一定数量GPU的用户来说,如果能够将GPU的利用率提高一倍,就相当于增加了一倍的额外算力,在更短的时间内完成更多的应用。
由于显存容量受限,多机多卡的GPU集群需要共享的外部存储来为所有节点提供高速的应用数据访问。将数据从存储载入到GPU,过去都是由CPU负责,而这将会成为硬件性能的瓶颈。即使实现了服务器节点到存储的高速访问,数据到GPU的这“最后一公里”往往会造成GPU等待数据的情况,导致GPU利用率低下。
为此,英伟达开发了GPUDirect存储技术,可以通过RDMA高速网络直接将数据从外部存储传输至 GPU 显存上,能有效减轻CPU I/O的瓶颈,提升GPU 访问数据的带宽并大幅缩短时间延迟。IBM Storage Scale软件是首批支持该技术的认证存储产品,经测试,采用GDS 技术的IBM Storage Scale System 可以将GPU 访问数据的带宽提高一倍,时间延迟缩短一半。
在实际应用中,通过采用GDUDirect 存储(GDS)技术可以将GPU的利用率提高90%。例如,德国大陆汽车(Continental Automotive AG)采用 IBM Storage Scale System 作为 NVIDIA DGX 系统的共享数据存储后,AI 训练时间缩短了 70%,每个月完成的试验数量增长了14倍,宝贵GPU资源的利用率得到了极大的提升。
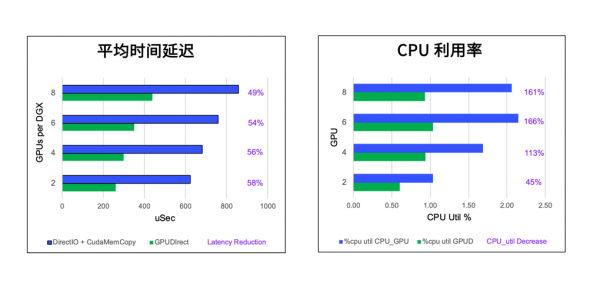
GPUDirect 存储技术带来时间延迟和CPU利用率的显著改善
IBM 存储与英伟达有着多年的合作历史,早在2018年和2019年就推出了DGX-1 POD和DGX-2 POD 的参考架构,并帮助英伟达利用IBM Storage Scale System构建了2018年全球超级计算机排名第61位的Circe和2019年全球排名第22位的DGX-2H SuperPOD;此后更是成为其 GPU Direct to Storage (GDS) 公开测试版本的合作伙伴,针对NVIDIA DGX A100 和 H100 的BasePOD 和 SuperPOD 都提供了NVIDIA认证的参考存储架构。
IBM Storage Scale软件也是首批官方认证支持GDS的产品。今年11月发布的最新Top500超级计算机榜单中,位于西班牙巴塞罗那超级计算中心的MareNostrum 5 ACC(GPU集群分区) 排名第八,该系统采用了4500块NVIDIA H100 GPU,其存储部分采用了容量为248PB的IBM Storage Scale System和400PB的磁带系统。
IBM AI存储的降本增效“黑科技”
除了 IBM Storage Scale 软件的高性能数据访问能力,以及跨系统、跨地域的全局数据访问和调度能力,IBM AI存储还有不少“黑科技”可以更好地帮助 AI 用户降本增效:
- 绿色节能:IBM 享有专利的计算存储驱动器FlashCore Module (FCM) 在存储驱动器内部集成了智能的FPGA芯片,通过硬件加速可实现强大的在线数据压缩和加密功能。基于该技术 Storage Scale System 6000可以在4U空间内 提供高达 3.6PB 全闪存有效容量,将每 TB 的存储成本降低 70%,将每TB的能耗降低 53%。
- 安全弹性:IBM Storage Scale 软件的纠删码功能确保了数据可靠性,与传统 RAID 相比,可以在数分钟(而非数小时或数天) 内重建磁盘,最大程度地减少故障对数据访问性能的影响;IBM Storage Scale 软件提供 Safeguarded Copy(不可篡改的数据快照)和日志审计、加密功能,可以有效应对如网络攻击和勒索病毒等的安全威胁,提供高达 6 个 9 的可用性。
- 支持混搭:IBM Storage Scale 提供多种部署和配置选项,可将不同存储设备、基于 NFS 的其它文件存储和基于S3的其它对象存储、甚至是磁带存储统一纳入到全局命名空间中,消除数据孤岛,简化海量数据的访问和管理。
得益于这些领先优势,在2023年发布的Gartner 分布式存储魔力象限报告中,IBM连续第八年被评为领导者,并在报告中被认为是用于高性能文件、AI 和分析型工作负载的最佳解决方案。
无论是应对当前算力稀缺的挑战,还是发展以数据为中心的新一代AI应用,提升存力、优化数据存储已经成为必选项。我们期待继续携手中国客户和合作伙伴突破算力瓶颈、避开成本陷阱,更加高效地将AI转化为生产力!
来源:业界供稿
好文章,需要你的鼓励


Windows 11市场份额终于超越Windows 10成为第一
最新数据显示,Windows 11市场份额已达50.24%,首次超越Windows 10的46.84%。这一转变主要源于Windows 10即将于2025年10月14日结束支持,企业用户加速迁移。一年前Windows 10份额还高达66.04%,而Windows 11仅为29.75%。企业多采用分批迁移策略,部分选择付费延长支持或转向Windows 365。硬件销售受限,AI PC等高端产品销量平平,市场份额提升更多来自系统升级而非新设备采购。

清华大学团队用AI“魔法师“重建3D世界:仅凭两张照片就能还原完整空间场景
清华大学团队开发出LangScene-X系统,仅需两张照片就能重建完整的3D语言场景。该系统通过TriMap视频扩散模型生成RGB图像、法线图和语义图,配合语言量化压缩器实现高效特征处理,最终构建可进行自然语言查询的三维空间。实验显示其准确率比现有方法提高10-30%,为VR/AR、机器人导航、智能搜索等应用提供了新的技术路径。

后Transformer模型系统能够推动变革
新一代液态基础模型突破传统变换器架构,能耗降低10-20倍,可直接在手机等边缘设备运行。该技术基于线虫大脑结构开发,支持离线运行,无需云服务和数据中心基础设施。在性能基准测试中已超越同等规模的Meta Llama和微软Phi模型,为企业级应用和边缘计算提供低成本、高性能解决方案,在隐私保护、安全性和低延迟方面具有显著优势。

IntFold:IntelliGen AI突破蛋白质结构预测难题,可控制基础模型改写药物发现游戏规则
IntelliGen AI推出IntFold可控蛋白质结构预测模型,不仅达到AlphaFold 3同等精度,更具备独特的"可控性"特征。该系统能根据需求定制预测特定蛋白质状态,在药物结合亲和力预测等关键应用中表现突出。通过模块化适配器设计,IntFold可高效适应不同任务而无需重新训练,为精准医学和药物发现开辟了新路径。
2023
11/21
13:40
分享
点赞

后Transformer模型系统能够推动变革
德国实验室推出DeepSeek R1-0528变体,速度提升200%
Sakana AI 推出 TreeQuest:多模型团队表现超越单一大语言模型30%
蚂蚁国际联合国际掉期与衍生工具协会ISDA在新加坡发布跨境支付通证化行业框架
AI时代的“摆渡人”:从云起到智深,源信网络的七年穿越
OpenAI投资人Vinod Khosla:AI如何五年掌握80%工作技能?
微软启动新一轮裁员计划,9000名员工受影响
Wonder Dynamics联合创始人加入2025年TechCrunch Disrupt AI舞台
全球风投二季度复苏迹象显现,AI交易主导资本流向
什么是Perplexity?这款AI聊天机器人全方位解读
英超联赛推出AI工具提升球迷体验
Lovable计划融资1.5亿美元,估值达20亿美元
