
除了通义千问2.0,阿里云还发布了8个行业大模型
10月31日,在2023云栖大会上,阿里云CTO周靖人表示,面向智能时代,阿里云将通过从底层算力到AI平台再到模型服务的全栈技术创新,升级云计算体系,打造一朵AI时代最开放的云。
在现场,周靖人公布了云计算基础能力的最新进展,升级了人工智能平台,并发布千亿级参数规模的大模型通义千问2.0,以及一站式模型应用开发平台阿里云百炼,阿里云已初步建成AI时代全栈的云计算体系。
“目前,中国有一半大模型企业跑在阿里云上,280万AI开发者活跃在阿里云魔搭社区上,未来,阿里云将携手千行百业推动AI创新,共享技术红利。”周靖人说。

全面升级AI基础设施
大模型是本轮AI浪潮的核心技术,基础模型的质量很大程度决定了AI产业化的前景。训练大模型是囊括了算力底座、网络、存储、大数据、AI框架、AI模型等复杂技术的系统性工程,只有强大的云计算体系才能训练出高质量的大模型。
周靖人表示,2009年阿里云就提出“数据中心是一台计算机”的理念,今天,AI时代更加需要这样的技术体系。作为一台超级计算机的云计算,可高效连接异构计算资源,突破单一性能芯片瓶颈,协同完成大规模智能计算任务。
为了保证大模型训练的稳定互联和高效并行计算,阿里云全新升级了人工智能平台PAI。PAI底层采用HPN 7.0新一代AI集群网络架构,支持高达10万卡量级的集群可扩展规模,超大规模分布式训练加速比高达96%,远超业界水平;在大模型训练任务中,可节省超过50%算力资源,性能全球领先。

阿里云通义大模型系列就是基于人工智能平台PAI训练而成。除了通义大模型,中国一半大模型公司跑在阿里云上,百川智能、智谱AI、零一万物、昆仑万维、vivo、复旦大学等大批头部企业及机构均在阿里云上训练大模型。
百川智能创始人兼CEO王小川表示,“百川成立仅半年便发布了7款大模型,快速迭代背后离不开云计算的支持。”百川智能和阿里云进行了深入合作,在双方的共同努力下,百川很好地完成了千卡大模型训练任务,有效降低了模型推理成本,提升了模型部署效率。
阿里云已成为中国大模型的公共AI算力底座。截至目前,中国众多头部主流大模型都已通过阿里云对外提供API服务,包括通义系列、Baichuan系列、智谱AI ChatGLM系列、姜子牙通用大模型等。
随着AI产业化逐步深入,必将迎来大规模智能算力需求爆发。阿里云已在全球30个地域建设了89个云计算数据中心,提供3000余个边缘计算节点,云计算的低延时、高弹性优点将发挥得淋漓尽致。今年,阿里云成功支撑火爆全网的妙鸭相机短时间高强度的流量爆发。
走向自动驾驶的云
周靖人说:“随着大模型技术与云计算本身的融合,我们希望未来的云可以像车一样也能够自动驾驶,大幅提升开发者使用云的体验。”
据悉,阿里云上有超过30款云产品接入了大模型能力,例如阿里云大数据治理平台DataWorks新增了全新的交互形态——Copilot,用户只需用自然语言输入即可生成SQL,并自动执行相应的数据ETL操作,整体开发与分析可提效30%以上,堪比“自动驾驶”。
阿里云容器、数据库等产品上也提供了类似的开发体验,可实现NL2SQL、SQL注释生成/纠错/优化等功能,未来这些能力还将集成到阿里云其他产品上。
更好的大模型,加速应用创新
在2023云栖大会现场,周靖人公布了阿里自研大模型的最新进展,发布千亿级参数规模的通义千问2.0。通义千问2.0在10个权威测评中全面超越GPT-3.5和Llama2,加速追赶GPT-4。
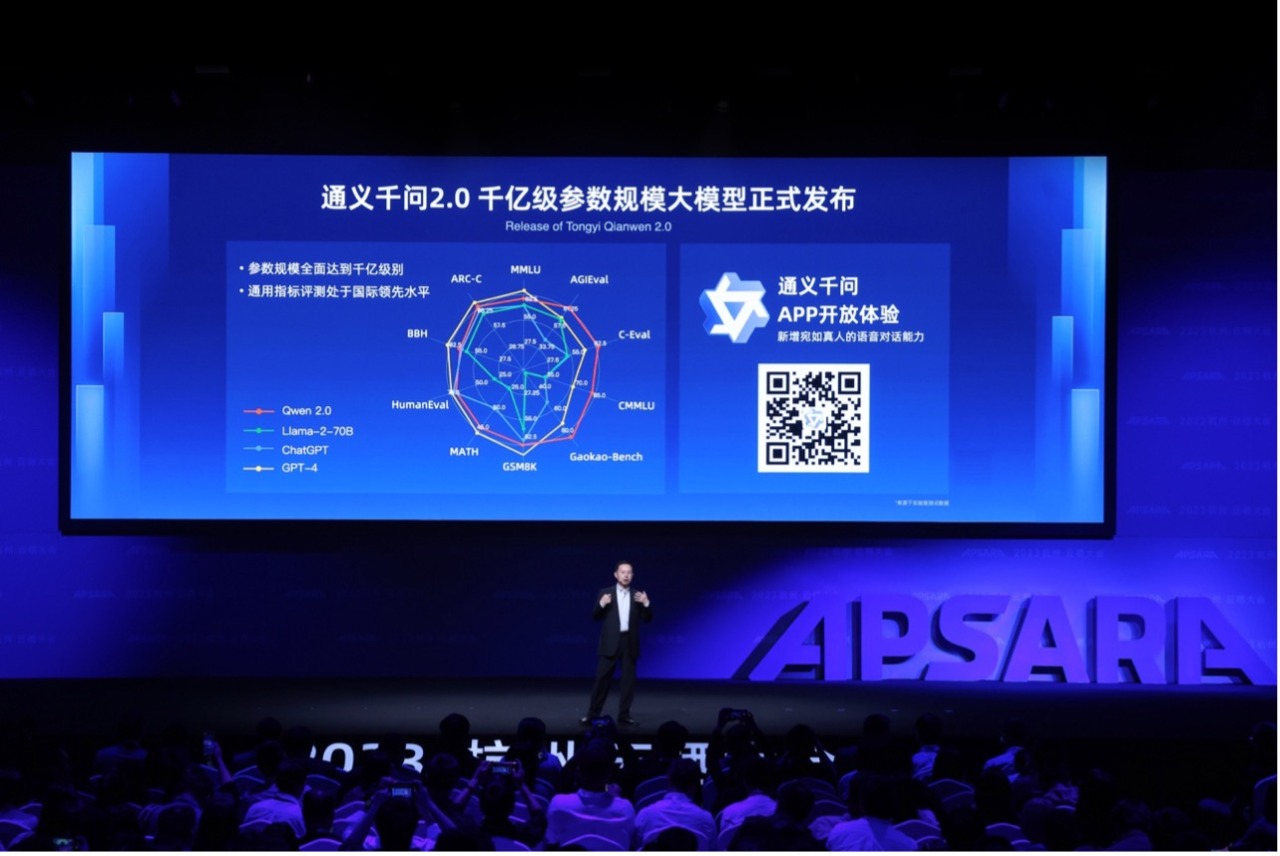
千行百业都想借助大模型实现生产和服务方式的变革,但大模型使用的高门槛把大部分人挡在了技术浪潮之外。不论是定制专属大模型,还是基于大模型构建创新应用,都有很高的人才、技术、资金要求。
在云栖大会现场,周靖人发布一站式大模型应用开发平台——阿里云百炼,该平台集成了国内外主流优质大模型,提供模型选型、微调训练、安全套件、模型部署等服务和全链路的应用开发工具,为用户简化了底层算力部署、模型预训练、工具开发等复杂工作。开发者可在5分钟内开发一款大模型应用,几小时即可“炼”出一个企业专属模型,开发者可把更多精力专注于应用创新。
为推动大模型更易在千行百业集成落地,阿里云基于通义“打样”了8个行业大模型,并在现场公布进展:个性化角色创作平台通义星尘、智能投研助手通义点金、AI阅读助手通义智文等首次亮相;智能编码助手通义灵码已在阿里云内部大规模采用,广受好评;工作学习AI助手通义听悟每天处理5万余个音视频,累积用户超100万。
大模型正引发千行百业的新一轮创新,目前,央视网、朗新科技、亚信科技等企业已率先在阿里云百炼上开发专属模型和应用,朗新科技在云上训练出电力专属大模型,开发“电力账单解读智能助手”“电力行业政策解析/数据分析助手”,为客户接待提效50%、降低投诉70%。
用坚定的开放,共促生态繁荣
“促进中国AI生态繁荣,是阿里云的首要目标。阿里云将坚定打造AI时代最开放的大模型平台,我们欢迎所有大模型接入阿里云百炼,共同向开发者提供AI服务。”周靖人表示。
阿里云是国内最早开源自研大模型的科技公司,掀起中国大模型开源浪潮。目前,阿里云已开源通义千问7B、14B版本,下载量突破百万。在现场,周靖人宣布通义千问72B模型即将开源,将成为中国参数最大的开源模型。
除了与开发者共享自研新技术,阿里云还大力支持三方大模型发展。在阿里云魔搭社区上,百川智能、智谱AI、上海人工智能实验室、IDEA研究院等业界顶级玩家,都开源首发他们的核心大模型,阿里云则为开发者们“尝鲜”大模型提供免费GPU算力,截至目前已超3000万小时。

周靖人透露,魔搭社区现已聚集2300多款AI模型,吸引280万名AI开发者,AI模型下载量突破1亿,成为中国规模最大、开发者最活跃的AI社区。
2023云栖大会上,阿里云宣布了一项重磅计划:“云工开物计划”,给中国所有大学生每人送一台云服务器。此外,阿里云还将为签约高校提供更大规模的算力资源支持,助力中国青年学者和学子攀登科研高峰。目前,清华大学、北京大学、浙江大学、上海交通大学、中国科学技术大学、华南理工大学等高校已首批达成合作。
好文章,需要你的鼓励


OpenAI CEO阿尔特曼承认当前处于AI泡沫期
OpenAI首席执行官Sam Altman表示,鉴于投资者的AI炒作和大量资本支出,我们目前正处于AI泡沫中。他承认投资者对AI过度兴奋,但仍认为AI是长期以来最重要的技术。ChatGPT目前拥有7亿周活跃用户,是全球第五大网站。由于服务器容量不足,OpenAI无法发布已开发的更好模型,计划在不久的将来投资万亿美元建设数据中心。

阿里巴巴突破AI说话人视频生成技术壁垒:首次实现动作自然度、唇同步准确性和视觉质量的完美平衡
阿里巴巴团队提出FantasyTalking2,通过创新的多专家协作框架TLPO解决音频驱动人像动画中动作自然度、唇同步和视觉质量的优化冲突问题。该方法构建智能评委Talking-Critic和41万样本数据集,训练三个专业模块分别优化不同维度,再通过时间步-层级自适应融合实现协调。实验显示全面超越现有技术,用户评价提升超12%。

英伟达发布全新小型开源模型Nemotron-Nano-9B-v2,支持推理开关控制
英伟达推出新的小型语言模型Nemotron-Nano-9B-v2,拥有90亿参数,在同类基准测试中表现最佳。该模型采用Mamba-Transformer混合架构,支持多语言处理和代码生成,可在单个A10 GPU上运行。独特的可切换推理功能允许用户通过控制令牌开启或关闭AI推理过程,并可管理推理预算以平衡准确性和延迟。模型基于合成数据集训练,采用企业友好的开源许可协议,支持商业化使用。

UC Berkeley团队突破AI内存瓶颈:让大模型推理快7倍的神奇方法
UC Berkeley团队提出XQUANT技术,通过存储输入激活X而非传统KV缓存来突破AI推理的内存瓶颈。该方法能将内存使用量减少至1/7.7,升级版XQUANT-CL更可实现12.5倍节省,同时几乎不影响模型性能。研究针对现代AI模型特点进行优化,为在有限硬件资源下运行更强大AI模型提供了新思路。
2023
10/31
15:15
分享
点赞

英伟达发布全新小型开源模型Nemotron-Nano-9B-v2,支持推理开关控制
谷歌翻译将集成AI功能并增加游戏化学习模式
边缘AI基础设施的现实挑战与解决方案
Hugging Face:企业在不牺牲性能下降低AI成本的5种方法
阿里推出Ovis2.5:多模态大语言模型的又一重要突破
对话谷歌副总裁Karen Teo:“短剧”“AI应用”现象级出海,我们看到中国开发者的三种内核
谷歌Gemini大模型登陆甲骨文云平台
Linux的微内核替代方案?Debian/Hurd证明微内核Unix梦想仍在继续
你的每一个问题、每一条评论,我都在记录
2035年最热门的十大颠覆性产业
AI"教父"提出让AI具备母性本能引发争议
生成式AI助力MIT科学家对抗超级细菌
