
阿里蔡崇信:成为AI时代最开放的那朵云 原创
10月31日,阿里云栖大会在杭州召开。
这是阿里在这一年里经历了一系列架构调整后,核心管理团队正式亮相,对外介绍如今阿里的战略和业务。
重新回归舞台、担任阿里巴巴集团主席的蔡崇信说,“阿里正在面向AI时代进行全面的升级和创新,我们希望成为AI时代一朵最开放的云。”
再次以阿里云创始人身份重回阿里的王坚说,“人工智能与云计算在60年后(的今天)自然地走在了一起,标志着云计算第三次浪潮的到来。”
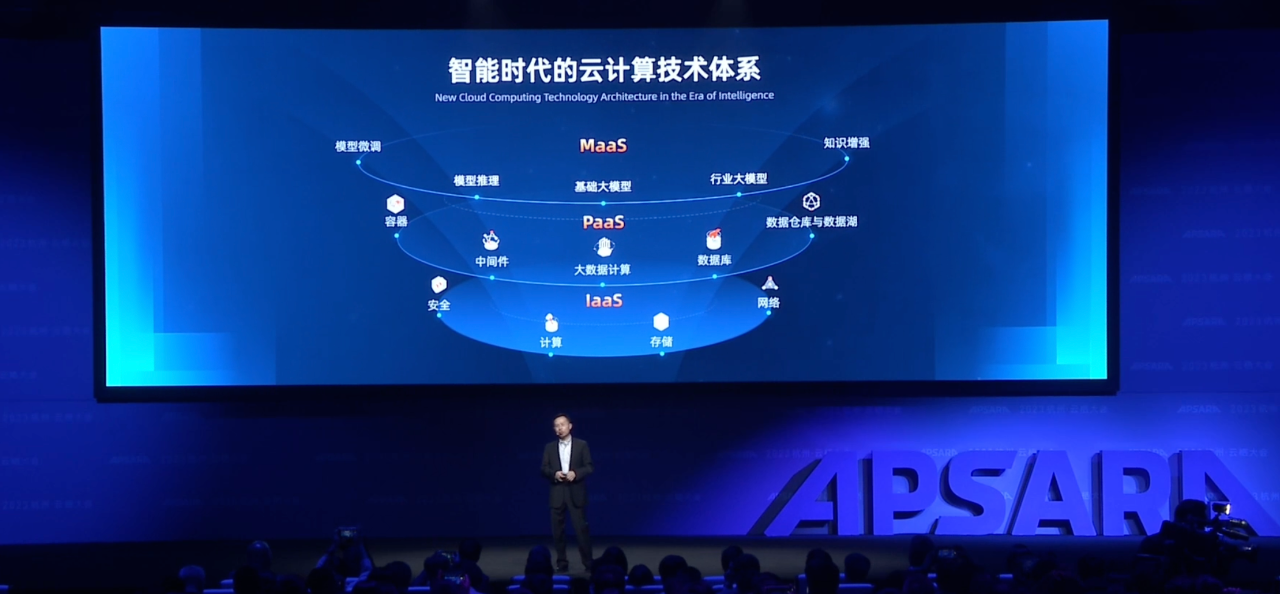
而作为当下阿里云CTO的周靖人,正式揭开了如今大模型时代,阿里云战略部署的秘密。
智能时代的计算变革
周靖人在大会上指出,智能时代,云计算也在发生着新的变化。
周靖人提到的变化,正是大模型时代的到来。
时至今日,大模型已经成为新型生产力和生产要素,云计算厂商也开始围绕大模型提AI基础设施和与大模型相关的计算和服务。
正因如此,阿里在2022年提出了model as a service——MaaS的概念。
2022年,阿里达摩院与CCF开源发展委员会联合发布了AI模型开源社区——魔搭社区(ModelScope),在这个社区中,阿里将涵盖自然语言处理、视觉、语音、多模态等300多个AI模型上线开放。
如今,魔搭社区已经聚集了270万开发者,2300多个优质模型,模型下载量超过1亿次,成为了中国规模最大、最活跃的AI社区。
此外,阿里还建立了PAI人工智能平台,通过这一平台对外提供超高性能分布式模型训练能力和低延时模型训练推理与服务能力,服务了包括百川、智谱、昆仑万维、零一万物、vivo等的大模型训练。

阿里不仅是大模型时代的基础设施构建者,同样也是“百模大战”的重要参与者。
2023年4月,阿里正式对外发布了自己的大模型——通义千问,同年9月,阿里又将7B/14B通义千问模型对外进行了开源。
本次云栖大会上,阿里官方再次对外发布了千亿级参数规模的通义千问2.0,以及一系列行业大模型。
阿里云的这些年
阿里云成立于2009年,至今已经走过14个年头,在这14年里,阿里云从最初不被理解的技术团队成长为覆盖三分之一国内公有云市场,覆盖500万客户和1000万开发者的云计算公司。
在这期间,阿里云实现了几次重要蜕变。
2009年,阿里云团队成立,飞天系统的第一行代码在这时写下;
2013年,5K集群突破与投入生产,标志着阿里云云产品矩阵的成型;
2017年,云原生和PolarDB云原生数据库的上线,标志着云计算进入到一个新的时代;

2021年,倚天710芯片的发布,成了阿里云团队从软件到硬件体系的迈出的重要一步。
今年人工智能平台与模型服务的发布,则标志着云计算智算时代的到来。
这样的云计算的发展,为产业带来了怎样的价值?
周靖人在大会现场就赛事、娱乐、能源、金融、汽车等行业应用,进行了详细解读。
2023年9月23日,第十九届亚运会在杭州正式开幕。和以往亚运会不同的是,这届亚运会实现了100%核心系统上云。

实际上,阿里云自2021年就开始助力奥运会上云,在这一年通过“奥林匹克转播云”让东京奥运会实现了云上转播;2022年,在2022年北京冬奥会期间,首次实现了核心赛事系统全面上云。
到今年的杭州亚运会期间,借助阿里云,又实现了核心系统全面上云,由此摆脱了通过卫星转播,云上传输系统达到TB级,最大可以实现60路高清和超高清信号传输。
在能源领域,国家电网与阿里云合作,构建了国内最大的标准化行业云——国网云。

这一行业云支撑国网通过一云多Region架构,形成逻辑统一的国网云,并支撑起了全国4.5亿只电表实时化改造。
在自动驾驶领域,小鹏汽车与阿里云合作,围绕自动驾驶、智能制造、全域营销三大场景在乌兰察布搭建了汽车云。

据官方统计数据显示,通过这朵汽车云,自动驾驶训练效率提升了170倍,GPU资源利用率提升了3倍,通信延时降低了80%,存储吞吐效率提升了40倍。
而这些,正是阿里云这些年里通过“计算”实现的“无法计算的价值”。
“为了无法计算的价值”
“计算,为了无法计算的价值。”
这是阿里云栖大会今年的主题,同时,这也是2015年阿里云栖大会的主题。
蔡崇信说,“当年阿里云服务了移动互联网的大发展,今天我们希望可以再次服务AI时代的创新发展。”
他还指出,“目前,中国80%的科技企业,一半的大模型公司都跑在阿里云。”
如此看来,接下来的大模型之战,阿里云如何推动产业走向,也成了战局的关键。
好文章,需要你的鼓励


超越能源使用:数据中心可持续运营策略
随着AI广泛应用推动数据中心建设热潮,运营商面临可持续发展挑战。2024年底美国已建成或批准1240个数据中心,能耗激增引发争议。除能源问题外,服务器和GPU更新换代产生的电子废物同样严重。通过采用模块化可修复系统、AI驱动资产跟踪、标准化数据清理技术以及与认证ITAD合作伙伴合作,数据中心可实现循环经济模式,在确保数据安全的同时减少环境影响。

剑桥大学突破性研究:如何让AI在对话中学会真正的自信判断
剑桥大学研究团队首次系统探索AI在多轮对话中的信心判断问题。研究发现当前AI系统在评估自己答案可靠性方面存在严重缺陷,容易被对话长度而非信息质量误导。团队提出P(SUFFICIENT)等新方法,但整体问题仍待解决。该研究为AI在医疗、法律等关键领域的安全应用提供重要指导,强调了开发更可信AI系统的紧迫性。

2026年超大规模数据中心运营商发展前瞻:全球最大数据中心运营商的未来走向
超大规模云数据中心是数字经济的支柱,2026年将继续保持核心地位。AWS、微软、谷歌、Meta、甲骨文和阿里巴巴等主要运营商正积极扩张以满足AI和云服务需求激增,预计2026年资本支出将超过6000亿美元。然而增长受到电力供应、设备交付和当地阻力制约。截至2025年末,全球运营中的超大规模数据中心达1297个,总容量预计在12个季度内翻倍。

威斯康星大学研究团队破解洪水监测难题:AI模型终于学会了“眼观六路“
威斯康星大学研究团队开发出Prithvi-CAFE洪水监测系统,通过"双视觉协作"机制解决了AI地理基础模型在洪水识别上的局限性。该系统巧妙融合全局理解和局部细节能力,在国际标准数据集上创造最佳成绩,参数效率提升93%,为全球洪水预警和防灾减灾提供了更准确可靠的技术方案。
2023
10/31
11:52
分享
点赞

Littelfuse推出适用于电动汽车电池、电机和安全系统的汽车级电流传感器
CES 2026 | 机器人开发的“ChatGPT时刻”已到 老黄定调“物理AI”的路线图
超越能源使用:数据中心可持续运营策略
2026年超大规模数据中心运营商发展前瞻:全球最大数据中心运营商的未来走向
TOTOLINK EX200存在未修复固件漏洞可被完全远程接管
Ring推出Fire Watch功能,利用家庭摄像头追踪野火威胁
Snowflake与Google Gemini深度整合,全云环境支持数据分析
联想和摩托罗拉推出自有设备端AI助手
机器海龟游向环保使命:仿生技术守护珊瑚礁
CES 2026最酷笔记本电脑:可拆卸设计成为新趋势
AMD 在 CES 2026 发布新款锐龙处理器、Ryzen AI 及 AMD ROCm,全面扩展其在客户端、图形和软件领域的 AI 领先地位
AMD发布Instinct GPU新品挑战英伟达数据中心霸主地位
