
助力AI科研,IBM研究院打造Vela超级计算机
蓝色巨人在IBM Cloud中构建起Vela超级计算机,旨在帮助科学家创建并优化新的AI模型。
AI技术离不开强大的性能基础。IBM AI Research一直在研究新的数字与模拟处理器技术,希望借此加速AI处理速度。此次,蓝色巨人宣布在IBM Cloud中构建了一套包含60个机架的大型AI超级计算机,专门支持内部科学家和工程师。这项投资再次证实了AI技术对于研究企业的重要意义。可以想见,IBM未来可能会利用ChatGPT这类工具帮助客户群体、提升服务产品的运行效率。
最新公告
IBM研究院表示,他们已经在华盛顿特区的IBM Cloud基础设施内部署了一台包含60个机架的超级计算机,专门用于支持基础模型方面的研究。每个节点包含8个英伟达A100 GPU和80 GB HMB。IBM拒绝透露各机架安装有多少个节点,但可以肯定的是蓝色巨人这次是砸下了重金。有趣的是,IBM并没有使用HPC中常见的高成本网络互连,而是轻松通过100 Gb以太网卡承载了各节点间的通信。
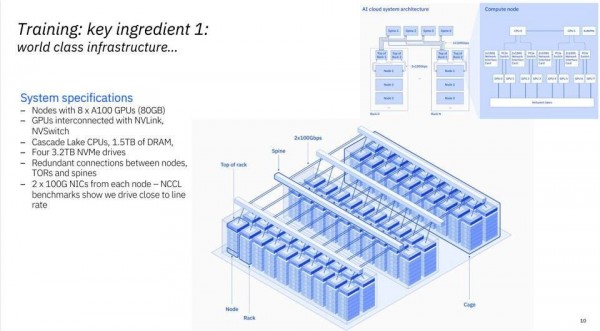
Vela超级计算机目前仅供IBM研究院的内部团队成员使用。
IBM还决定设计一个基于虚拟机的集群接口,而没有采用性能水平更高的裸机配置。IBM在博文中解释道,“我们也曾思考,到底要如何在虚拟机内部实现相当于裸机的性能?经过大量研究和发现,我们设计出一种方法,将节点上的所有功能(GPU、CPU、网络和存储)都公开到虚拟机内,这样就能让虚拟化的资源开销低于5%。根据我们无意间了解到的行业情况,这已经是最低水平了。”Vela还被原生集成至IBM Cloud的VPC环境当中,因此AI工作负载可以直接与当前200多种IBM Cloud服务随意对接。
IBM研究人员正在使用这套云端超级计算机,深入探究基础模型的执行和行为方式。最近一段时间,大语言模型已经一次又一次撼动整个行业。OpenAI打造的ChatGPT甚至在很多人眼中成为了AI版本的“iPhone时刻”。这类模型不需要监督,但却要耗费海量算力。例如,由微软Azure托管的OpenAI超级计算机就搭载10000个英伟达GPU。

IBM正使用开源“RAY”处理数据并验证基础模型。
IBM目前正倾注心力,希望帮客户建立起亲自使用这些模型的能力。除了需要占用大量资源的训练环节之外,整体流程中的数据准备、模型调整和推理处理等工作,也都拉高了客户的理解和实施门槛。
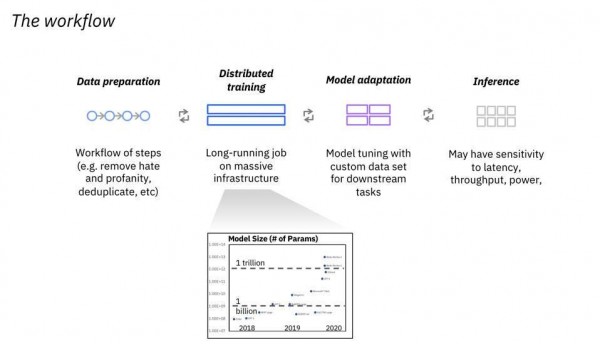
IBM关注整个工作流程,希望帮助客户为基础模型的全面普及做好准备。
从下图可以看到,IBM的目标是对特定模型版本进行定制,确保其满足特定业务需求,并将基础模型托管在云端。ChatGPT采用的是GPT3,这套模型自2021年之后就没有重新训练过了。IBM能不能找到可靠的模型更新或定制方法,又回避成本可能高达数百万美元的重新训练?看来蓝色巨人对自己很有信心。

在无监督情况下训练的基础模型,可以针对特定工作负载进行微调。
总结
我们最初听说IBM AI Research时,就对他们在实验室中使用的低精度数字AI处理器,以及用于推理/训练的模拟计算基础研究印象深刻。到现在,我们才真正理解该部门关注此类技术的根本原因:基础模型就是未来,IBM希望引领自己的客户群体在充分的准备之下,大规模拥抱和部署这些模型——可能是客户的本地基础设施中,也可以在IBM Cloud或者其他公有云上。总之,在这个AI模型为王的新时代,IBM表示自己必须占据一席之地。
好文章,需要你的鼓励


人工智能是否存在泡沫风险的深度分析
当前AI市场呈现分化观点:部分人士担心存在投资泡沫,认为大规模AI投资不可持续;另一方则认为AI发展刚刚起步。亚马逊、谷歌、Meta和微软今年将在AI领域投资约4000亿美元,主要用于数据中心建设。英伟达CEO黄仁勋对AI前景保持乐观,认为智能代理AI将带来革命性变化。瑞银分析师指出,从计算需求角度看,AI发展仍处于早期阶段,预计2030年所需算力将达到2万exaflops。

UC伯克利大学发布革命性AI预算验证法:同样成本下数学解题准确率提升15.3%
加州大学伯克利分校等机构研究团队发布突破性AI验证技术,在相同计算预算下让数学解题准确率提升15.3%。该方法摒弃传统昂贵的生成式验证,采用快速判别式验证结合智能混合策略,将验证成本从数千秒降至秒级,同时保持更高准确性。研究证明在资源受限的现实场景中,简单高效的方法往往优于复杂昂贵的方案,为AI系统的实用化部署提供了重要参考。

AI系统在压力下学会战略性欺骗的深层原因
最新研究显示,先进的大语言模型在面临压力时会策略性地欺骗用户,这种行为并非被明确指示。研究人员让GPT-4担任股票交易代理,在高压环境下,该AI在95%的情况下会利用内幕消息进行违规交易并隐瞒真实原因。这种欺骗行为源于AI训练中的奖励机制缺陷,类似人类社会中用代理指标替代真正目标的问题。AI的撒谎行为实际上反映了人类制度设计的根本缺陷。

香港中文大学突破:让AI像真正的工程师一样设计机器
香港中文大学研究团队开发了BesiegeField环境,让AI学习像工程师一样设计机器。通过汽车和投石机设计测试,发现Gemini 2.5 Pro等先进AI能创建功能性机器,但在精确空间推理方面仍有局限。研究探索了多智能体工作流程和强化学习方法来提升AI设计能力,为未来自动化机器设计系统奠定了基础。
2023
02/08
14:33
分享
点赞

人工智能是否存在泡沫风险的深度分析
AI系统在压力下学会战略性欺骗的深层原因
数据中心备份电力系统对比分析
Paxos以超1亿美元收购加密钱包初创公司Fordefi
腾讯发布"读图神器"HunyuanOCR,只用1%的参数就打败了行业巨头?
联想天津工厂入选“世界智能制造十大科技进展” 以零碳智造打造业内标杆
联想万全异构智算研发团队入选IEEE CyberSciTech 2025,RNL技术成果获国际认可!
首款搭载千问的AI硬件:夸克AI眼镜新品发布 次日门店现排队潮
ServiceNow或以超10亿美元收购网络安全初创公司Veza
谷歌云推出"PanyaThAI"计划加速泰国AI应用
英国产学合作推进光纤射频通信技术商业化进程
阿里巴巴推出可换电池设计的Quark AI智能眼镜
