
AI基准测试MLPerf推理V1.1发榜 浪潮获15项冠军蝉联榜首
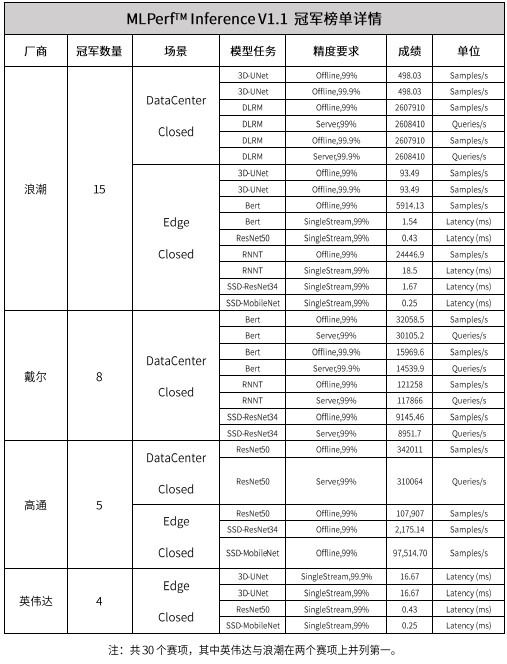
9月23日,全球权威AI基准评测MLPerf™公布最新榜单Inference(推理) V1.1,在最受关注的固定任务(Closed)测试中,浪潮获得15项冠军,戴尔、高通、英伟达分别获得8项、5项和4项冠军。
MLPerf™是影响力最广的国际AI性能基准评测,由图灵奖得主大卫•帕特森(David Patterson)联合顶尖学术机构发起成立。2020年,非盈利性机器学习开放组织MLCommons基于MLPerf™基准测试成立,其成员包括谷歌、Facebook、英伟达、英特尔、浪潮、哈佛大学、斯坦福大学、加州大学伯克利分校等50余家全球AI领军企业及顶尖学术机构,致力于推进机器学习和人工智能标准及衡量指标。目前,MLCommons每年组织2次MLPerf™ AI训练性能测试和2次MLPerf™ AI推理性能测试,为用户衡量设备性能提供权威有效的数据指导。
MLPerf™推理V1.1 AI基准测试固定任务(Closed)包括数据中心(共16个项目)和边缘(共14个项目)两大场景。在数据中心场景下设置6个模型,分别是图像识别(ResNet50)、医学影像分割(3D-UNet)、目标物体检测(SSD-ResNet34)、语音识别(RNN-T)、自然语言理解(BERT)以及智能推荐(DLRM),其中Bert、DLRM和3D-Unet设有高精度(99.9%)模式。除3D-UNet模型任务只考察Offline离线推理场景性能外,其他模型任务按照Server在线推理和Offline离线推理两种应用场景分别进行性能测试。边缘场景AI模型在数据中心场景的6个模型基础上删减了智能推荐(DLRM)模型,并增加目标物体检测(SSD-MobileNet)模型,所有模型均有Offline离线推理场景和SingleStream单流推理两个场景。
固定任务(Closed)要求参赛各方使用相同模型和优化器,这对于实际用户评测AI计算系统性能具备很强的参考意义,也一直是MLPerf™中角逐最激烈及主流厂商最关注的领域。此次共有英伟达、英特尔、浪潮、高通、阿里巴巴、戴尔、HPE等19家厂商参与到固定任务(Closed)测试竞赛中,其中数据中心场景收到了754项成绩提交,边缘场景收到了448项成绩提交,共1199项成绩提交。
在固定任务的全部30个项目中,浪潮获得15项冠军,位居冠军数量第一,这也是浪潮连续第四次位居MLPerf™ AI基准测试冠军数量榜首。
此次MLPerf™的开放任务(Open)赛道允许参赛方对模型进行任意处理,参加者有cTuning、Krai等6家厂商,数量较上届有下降。此外,本次MLPerf™还共有NVIDIA、浪潮、高通以及戴尔等5家厂商在功耗任务上提交了结果,功耗评测或将成为未来MLPerf™的关注重点之一。
来源:业界供稿
好文章,需要你的鼓励


腾讯开源混元MT翻译模型系列
腾讯今日开源混元MT系列语言模型,专门针对翻译任务进行优化。该系列包含四个模型,其中两个旗舰模型均拥有70亿参数。腾讯使用四个不同数据集进行初始训练,并采用强化学习进行优化。在WMT25基准测试中,混元MT在31个语言对中的30个表现优于谷歌翻译,某些情况下得分高出65%,同时也超越了GPT-4.1和Claude 4 Sonnet等模型。

如何让AI像电影配乐师一样创作完整的长篇音频故事——腾讯ARC实验室团队AudioStory突破性进展
腾讯ARC实验室推出AudioStory系统,首次实现AI根据复杂指令创作完整长篇音频故事。该系统结合大语言模型的叙事推理能力与音频生成技术,通过交错式推理生成、解耦桥接机制和渐进式训练,能够将复杂指令分解为连续音频场景并保持整体连贯性。在AudioStory-10K基准测试中表现优异,为AI音频创作开辟新方向。

Unity Stoakes谈科技、科学与设计的融合变革全球健康
今年是Frontiers Health十周年。在pharmaphorum播客的Frontiers Health限定系列中,网络编辑Nicole Raleigh采访了Startup Health总裁兼联合创始人Unity Stoakes。Stoakes在科技、科学和设计交汇领域深耕30多年,致力于变革全球健康。他认为,Frontiers Health通过精心选择的空间促进有意义的网络建设,利用网络效应推进创新力量,让企业家共同构建并带来改变,从而有益地影响全球人类福祉。

Meta与特拉维夫大学联手打造VideoJAM:让AI生成的视频动起来不再是奢望
Meta与特拉维夫大学联合研发的VideoJAM技术,通过让AI同时学习外观和运动信息,显著解决了当前视频生成模型中动作不连贯、违反物理定律的核心问题。该技术仅需添加两个线性层就能大幅提升运动质量,在多项测试中超越包括Sora在内的商业模型,为AI视频生成的实用化应用奠定了重要基础。
2021
09/23
09:30
分享
点赞

百度学术:行业首个一站式AI学术平台,6.9亿文献资源加持
腾讯开源混元MT翻译模型系列
Unity Stoakes谈科技、科学与设计的融合变革全球健康
微软结束OpenAI独家合作,Office将引入Anthropic模型
亚马逊推出Zoox无人出租车服务,在拉斯维加斯提供免费乘车体验
OpenAI与Oracle签署3000亿美元云计算合作协议
Akamai联合IDC研究:生成式AI驱动边缘演进,亚太80% CIO将依赖边缘服务支持AI工作负载
Gartner发布2025中国网络安全技术成熟度曲线
Lucidity将成本控制焦点转向Kubernetes存储
Spotify因万名用户出售数据构建AI工具而愤怒
Anthropic服务大规模宕机,开发者调侃重回"原始编程时代"
AI说谎的原因:它只是在迎合你想听的答案
