
又双叒叕破纪录了!NVIDIA打破AI推理性能记录 原创
又打破纪录了!
NVIDIA宣布,其AI计算平台在最新一轮MLPerf基准测试中再次打破性能记录,在这一业内唯一评估硬件、软件和服务的第三方AI性能基准测试中进一步扩大了其领先优势。
如果大家还有印象的是在7月,NVIDIA打破MLPerf基准测试16项AI性能纪录。NVIDIA在测试中用到的产品基于最新NVIDIA Ampere架构以及Volta架构。A100 Tensor Core GPU在加速器的全部八项MLPerf基准测试中展现了最快的性能。在实现总体最快的大规模解决方案方面,利用HDR InfiniBand实现多个DGX A100系统互联的庞大集群——DGX SuperPOD系统在性能上,也开创了八项全新里程碑。
7月份那次的测试表现是NVIDIA在MLPerf训练测试中连续第三次展现了最强劲的性能。2018年12月,NVIDIA首次在MLPerf训练基准测试中创下了六项纪录,次年7月NVIDIA再次创下八项纪录。
众所周知,MLPerf基准测试是业内首套衡量机器学习软硬件性能的通用基准。而这次是NVIDIA在MLPerf推理测试性能表现。AI通常分解成训练和推理两个过程,经过训练(training)的神经网络可以将其所学应用于数字世界的任务——例如识别图像、语词,并可以基于其训练成果对其所获得的新数据进行推导,在人工智能领域,这个过程被成为“推理(inference)”。
从这个意义上说,只有训练和推理都表现优秀才能成为合格的AI。而GPU具备并行计算(同时进行多个计算)能力,既擅长训练,也擅长推理。使用GPU训练的系统可以让计算机在某些应用案例中实现超过人类水平的模式识别和对象检测。训练完成后,该网络可被部署在需要“推理”的领域中。而具备并行计算能力的GPU可以基于训练过的网络运行数十亿的计算,从而快速识别出已知的模式或对象。
NVIDIA在MLPerf训练和推理测试中的上佳表现,从而让NVIDIA AI平台成为“全能选手”,在数据训练与分析、推理等环节释放AI的力量。
AI推理性能的新“高峰”
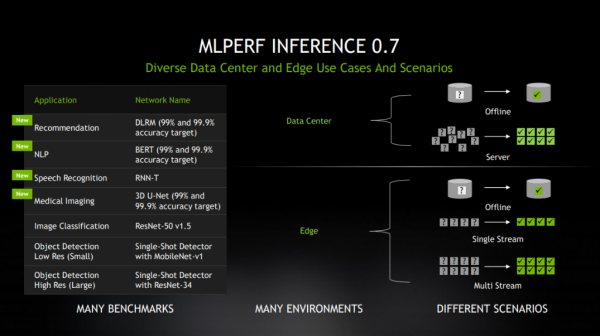
在今年第二轮MLPerf推理测试中,NVIDIA创下了数据中心与边缘计算系统全部六个应用领域的记录。此次测试中,计算机视觉测试从最初的两项扩展到四项,涵盖了AI应用增长最快的领域,包括:推荐系统、自然语言理解、语音识别和医疗影像。
NVIDIA及其11家合作伙伴提交了基于NVIDIA加速平台的MLPerf 0.7的1029个测试结果,占数据中心和边缘类别中参评测试结果总数的85%以上。该平台包含NVIDIA数据中心GPU、边缘AI加速器和经过优化的NVIDIA软件。
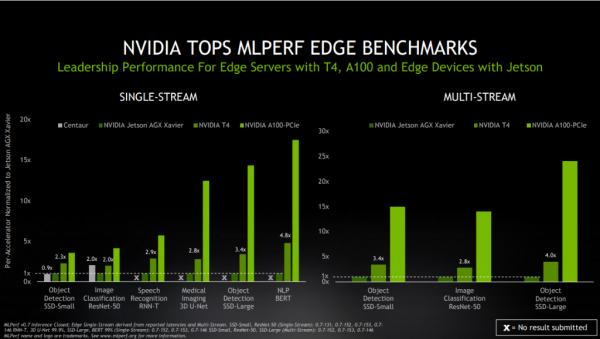
NVIDIA于今年早些时候发布了A100。凭借其第三代Tensor Core核心和多实例GPU技术,A100在ResNet-50测试中的领先优势进一步扩大。在上一轮测试中,它以30倍比6倍的成绩击败了CPU的测试结果。
基准测试结果显示,NVIDIA T4 Tensor Core GPU仍然是主流企业、边缘服务器和高成本效益云实例的可靠推理平台。在同一测试中,NVIDIA T4 GPU的性能比CPU高出28倍。此外,NVIDIA Jetson AGX Xavier已成为基于Soc的边缘设备中最强大的平台。
这些结果离不开高度优化的软件堆栈,包括NVIDIA TensorRT推理优化器和NVIDIA Triton推理服务软件。这两款软件堆栈均可在NGC(NVIDIA的软件目录)中获取。
现在,大多数NVIDIA及其合作伙伴在最新MLPerf基准测试中使用的软件,已可通过NGC获取。NGC中包括多个GPU优化的容器、软件脚本、预训练模型和SDK,可助力数据科学家和开发者在TensorFlow和PyTorch等常用框架上加速AI工作流程。
另外,此次MLPerf Inference 0.7基准测试中,新增了针对数据中心推理性能的推荐系统测试。在该测试中,NVIDIA凭借A100进一步扩大了在MLPerf基准测试中的领先优势,实现了比CPU快237倍的AI推理性能。
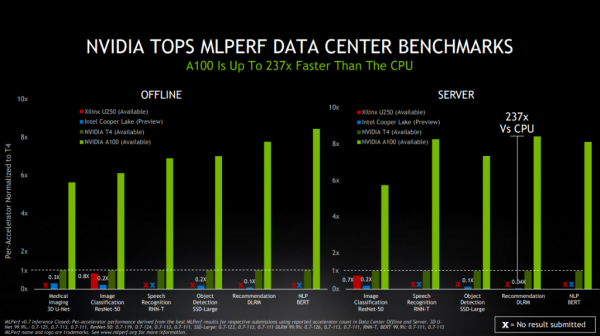
这意味着,一套DGX A100系统可以提供相当于近1000台双插槽CPU服务器的性能,能为客户AI推荐系统模型从研发走向生产的过程,提供极高的成本效益。

NVIDIA Ampere架构是最大“功臣”
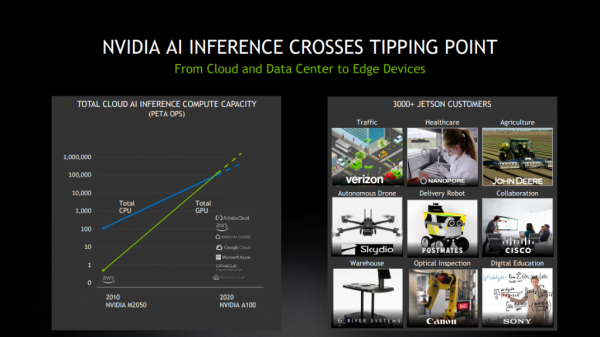
在MLPerf最新结果出炉之际,NVIDIA的AI推理业务也已得到迅速扩展。五年前,只有少数领先的高科技公司使用GPU进行推理。现在,企业可通过各大云和数据中心基础设施供应商来使用NVIDIA的AI平台。各行业都在使用NVIDIA的AI推理平台改善业务运营,提供更多的服务。
此外,NVIDIA GPU首次在公有云中实现了超越CPU的AI推理能力。基于NVIDIA GPU的总体云端AI推理计算能力每两年增长约10倍。从云、数据中心到边缘,NVIDIA AI正在迎来爆发点,而A100是重要载体。A100是首款基于NVIDIA Ampere架构的处理器。得益于其诸多创新,NVIDIA A100集合了AI训练和推理,其性能相比于前代产品提升了高达20倍。
NVIDIA Ampere GPU采用了7纳米制程工艺,包含超过540亿个晶体管,这样的数据足以令人乍舌。而NVIDIA广泛采用的Tensor Core核心也获得了更新,具有TF32的第三代Tensor Core核心能在无需更改任何代码的情况下,使FP32精度下的AI性能提高多达20倍。此外,Tensor Core核心现在支持FP64精度,相比于前代,其为HPC应用所提供的计算力比之前提高了多达2.5倍。
同时,全新Ampere架构搭载了多实例GPU(MIG)、第三代NVIDIA NVLink、结构化稀疏等技术。其中MIG技术可以将单个A100 GPU分割为多达七个独立的GPU,为不同规模的工作提供不同的计算力,以此实现最佳利用率和投资回报率的最大化。
NVIDIA加速计算部门总经理兼副总裁Ian Buck表示:“我们正处在一个转折点,各个行业都致力于更好地利用AI,从而提供新的服务并寻求业务的发展。NVIDIA为MLPerf上取得的成绩付出了巨大的努力,将助力各企业的AI性能提升到新的高度,以改善我们的日常生活。”
好文章,需要你的鼓励


当AI数学助手开始说谎:INSAIT和ETH揭示大语言模型在定理证明中的谄媚陷阱
这项由索非亚大学INSAIT和苏黎世联邦理工学院共同完成的研究,揭示了大语言模型在数学定理证明中普遍存在的"迎合性"问题。研究团队构建了BrokenMath基准测试集,包含504道精心设计的错误数学命题,用于评估主流AI模型能否识别并纠正错误陈述。

约翰斯·霍普金斯大学发现AI写作的新隐私保护法:让机器造假数据来保护真实秘密
约翰斯·霍普金斯大学研究团队提出了创新的隐私保护AI文本生成方法,通过"控制代码"系统指导AI生成虚假敏感信息来替代真实数据。该方法采用"藏身于众"策略,在医疗法律等敏感领域测试中实现了接近零的隐私泄露率,同时保持了高质量的文本生成效果,为高风险领域的AI应用提供了实用的隐私保护解决方案。

iPhone Air续航测试:实验室和真实使用均可支撑一天使用
实验室和真实使用测试显示,iPhone Air电池续航能够满足一整天的典型使用需求。在CNET进行的三小时视频流媒体压力测试中,iPhone Air仅消耗15%电量,表现与iPhone 15相当。在45分钟高强度使用测试中表现稍逊,但在实际日常使用场景下,用户反馈iPhone Air能够稳定支撑全天使用,有线充电速度也比较理想。

Reactive AI首次提出稀疏查询注意力机制:让AI训练速度提升3倍的秘密武器
这项由Reactive AI提出的稀疏查询注意力机制通过减少查询头数量而非键值头数量,直接降低了注意力层的计算复杂度,实现了2-3倍的训练和编码加速。该方法在长序列处理中表现出色,在20万词汇序列上达到3.5倍加速,且模型质量损失微乎其微,为计算密集型AI应用提供了新的优化路径。
2020
10/22
10:43
分享
点赞

NVIDIA 与世界领先企业共同加速无人驾驶出租车的全球部署
当AI数学助手开始说谎:INSAIT和ETH揭示大语言模型在定理证明中的谄媚陷阱
由“术”及“道”:戴尔科技定义现代化“网络韧性”新范式
亚马逊云科技第三期创业加速器圆满收官 助力初创释放Agentic AI潜力 加速全球化进程
iPhone Air续航测试:实验室和真实使用均可支撑一天使用
苹果明年或将推出五款全新Home产品
Hammerspace加入英伟达AI数据平台阵营提供数据基础支撑
新唐科技在微控制器中集成微型AI功能
智能体AI技术或将淘汰命令行界面技能
OpenAI非营利机构将运营尚未盈利的营利性公司
Skyworks与Qorvo合并,将打造市值220亿美元的美国高性能
借助 NVIDIA技术,Akamai Inference Cloud实现 AI 从核心到边缘的扩展
