
混合专家模型驱动最智能的前沿 AI 模型,在 NVIDIA Blackwell NVL72 系统上运行速度提升 10 倍
如今,几乎任一前沿模型的内部结构都采用混合专家(MoE)模型架构,这种架构旨在模拟人脑的高效运作机制。

正如大脑会根据任务激活特定区域,MoE 模型将工作分配给各个专门的专家,并在每个 AI token 的生成过程中只激活与之相关的专家。这样一来,无需成比例增加计算量,就能够实现更快速、更高效的 token 生成。
业界已认识到这一优势。在独立 AI 基准测试机构 Artificial Analysis(AA)的榜单上,Top 10 最智能开源模型均采用 MoE 架构,包括深度求索的 DeepSeek-R1、月之暗面的 Kimi K2 Thinking、OpenAI 的gpt-oss-120B 以及 Mistral AI 的 Mistral Large 3。
然而,大规模部署 MoE 模型并同时保持高性能向来极具挑战。NVIDIA GB200 NVL72 系统通过软硬件的极致协同设计,将硬件与软件优化相结合,以实现性能和效率最大化,从而使规模化部署 MoE 模型变得切实可行且简便直接。
Kimi K2 Thinking MoE 模型在 AA 榜单被评为当前最智能的开源模型。它在 NVIDIA GB200 NVL72 机架级扩展系统上的性能较在 NVIDIA HGX H200 上实现了 10 倍的飞跃。基于 DeepSeek-R1 和 Mistral Large 3 MoE 模型展现的卓越性能,这一突破性进展表明 MoE 架构正在成为前沿模型的首选架构,同时也印证了 NVIDIA 全栈推理平台是释放其全部潜力的关键所在。
什么是 MoE,为何它已成为前沿模型的标准
直到最近,构建更智能 AI 的行业标准还只是打造更大、更稠密的模型,这些模型会调用所有参数(当今最强大的模型往往拥有数千亿参数)来生成每个 token 。虽然很强大,但这种方法需要巨大的计算能力和能源,使其难以扩展。
正如人类大脑在处理不同认知任务(无论是语言处理、物体识别还是数学解题)时会调用不同的特定区域,MoE 模型也由多个专业化的“专家”组成。针对每一个输入的 token,路由器仅激活其中最相关的专家。这种设计意味着,尽管整体模型可能包含数千亿参数,但生成单个 token 仅需使用其中一小部分参数——通常只需数百亿参数参与计算。

正如人脑通过不同区域处理不同任务,MoE 模型也通过路由器选择最相关的专家来生成每个 token。
通过有选择性地仅调用最重要的专家模型,MoE 模型在不增加计算成本的前提下实现了更高的智能水平和适应性。这使其成为高效 AI 系统的基石,这类系统专为"每美元性能"与"每瓦特性能"而优化,能够在单位资金和单位能耗下产出显著更高的智能价值。
鉴于这些优势,MoE 迅速成为前沿模型的首选架构也就不足为奇。今年以来,已有超过 60% 的开源 AI 模型采用这一架构。自 2023 年初至今,该架构更推动模型智能水平实现近 70 倍的飞跃式增长,不断推动 AI 突破能力疆界。
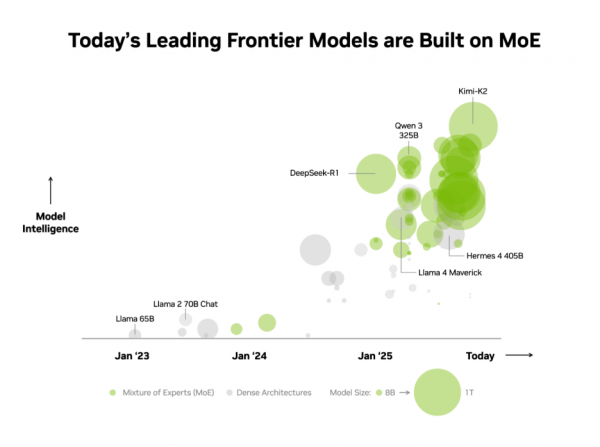
自2025年初以来,几乎所有领先的前沿模型都采用了 MoE 设计。
“我们两年前从 Mixtral 8x7B 开始,在开源 MoE 模型架构领域开展的开创性工作,确保了先进智能技术广泛应用于各类场景变得可行并且可持续。”Mistral AI 联合创始人兼首席科学家 Guillaume Lample 表示,“Mistral Large 3 的 MoE 架构使我们能够扩展 AI 系统至更高的性能与效率,同时大幅降低能耗和计算需求。”
通过极致协同设计突破 MoE 扩展瓶颈
前沿的 MoE 模型体量庞大且结构复杂,无法部署在单块 GPU 上。要运行这些模型,必须将专家分布在多块 GPU 上,这种技术称为“专家并行”。即使在 NVIDIA H200 这样的高性能平台上,部署 MoE 模型仍会遇到一些挑战,比如:
- 内存限制:对于每个 token,GPU 必须从高带宽内存中动态加载被选中专家的参数,导致内存带宽频繁承受巨大压力。
- 延迟:专家子网络必须执行近乎瞬时的 all-to-all 通信模式,以交换信息并形成最终完整的答案。然而在 H200 平台上,当专家组分布于超过八块 GPU 时,通信需通过高延迟的横向扩展网络进行,这限制了专家并行计算的优势。
解决方案:极致协同设计。
NVIDIA GB200 NVL72 是一款机架级扩展系统,搭载的 72 块 NVIDIA Blackwell GPU 协同工作,如同单一系统般运行,提供 1.4 ExaPLOPS AI 性能和 30 TB 高速共享内存。这 72 块 GPU 通过 NVLink Switch 连接成单一庞大的 NVLink 互连结构,使每块 GPU 都能以130 TB 每秒的 NVLink 连接速度相互通信。
MoE 模型能够利用这种设计将专家并行扩展到远超以往的极限——将专家分布在多达 72 块 GPU 的更大规模集群中。
这种架构方法通过以下方式直接解决了 MoE 的扩展瓶颈:
- 减少每块 GPU 上的专家数量:将专家分布在最多 72 块 GPU 上,可减少每块 GPU 承载的专家数量,从而最大限度减轻对每块 GPU 高带宽内存的参数加载压力。每块 GPU 上较少的专家数量还释放了内存空间,使各 GPU 能够服务更多并发用户并支持更长的输入序列。
- 加速专家通信:分布于不同 GPU 的专家可通过 NVLink 即时通信。NVLink Switch 还具备执行部分计算所需的算力以整合来自不同专家的信息,从而加速最终结果的生成。

其他全栈优化措施同样对释放 MoE 模型的卓越推理性能至关重要。NVIDIA Dynamo 框架通过将预填充和解码任务分配至不同 GPU 来协调分离服务,使解码任务得以采用大规模专家并行处理,而预填充任务则采用更契合其工作负载的并行技术。NVFP4 格式在保持精度的同时,进一步提升了性能与效率。
开源推理框架(如 NVIDIA TensorRT-LLM、SGLang 和 vLLM)均支持针对 MoE 模型的这些优化方案。其中,SGLang 在推动在 GB200 NVL72 平台上实现大规模 MoE 模型部署方面发挥了重要作用,助力验证并完善了当前广泛采用的诸多技术方案。
为了让全球企业都能获得这一卓越性能,GB200 NVL72 正通过主要云服务提供商及 NVIDIA 云合作伙伴进行部署,包括AWS、Core42、CoreWeave、Crusoe、Google Cloud、Lambda、Microsoft Azure、Nebius、Nscale、 Oracle Cloud Infrastructure、Together AI 等。
CoreWeave 联合创始人兼首席技术官 Peter Salanki 表示:“在 CoreWeave 平台上,客户正通过构建智能工作流,将 MoE 模型实现大规模部署。通过与 NVIDIA 的紧密合作,我们得以打造出一个高度集成的平台,能够将 MoE 模型的性能、可扩展性和可靠性融为一体。只有在专为 AI 打造的云平台上,才能实现这样的突破。”
DeepL 等客户正采用 Blackwell NVL72 机架级扩展设计来构建和部署其新一代 AI 模型。
DeepL 研究团队负责人 Paul Busch 表示:“DeepL 正借助 NVIDIA GB200 硬件训练 MoE 模型,通过推进模型架构提升训练与推理阶段的效率,为 AI 性能树立新标杆。”
性能体现在每瓦特性能上
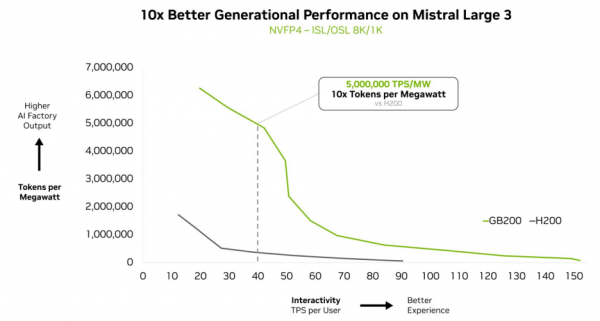
NVIDIA GB200 NVL72 能够高效扩展复杂的元学习模型,实现每瓦性能 10 倍的提升。这一性能飞跃不仅是标准上的突破,它使 token 收入可以实现 10 倍增长,彻底改变了 AI 在能效受限、成本敏感型数据中心中的规模化经济模型。
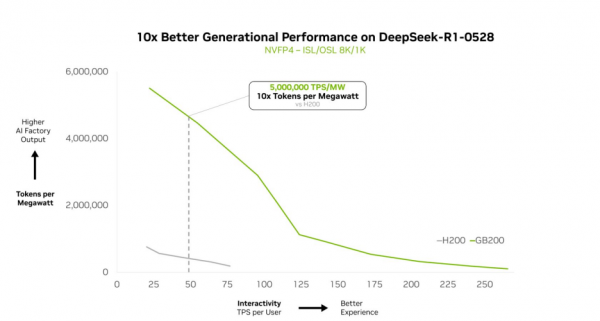
在华盛顿特区 NVIDIA GTC 大会上,NVIDIA 创始人兼首席执行官黄仁勋重点展示了 GB200 NVL72 如何使 DeepSeek-R1 的性能达到相较在 NVIDIA Hopper 架构上实现 10 倍的提升,且这样的性能提升同样适用于其他 DeepSeek 模型。
Together AI 联合创始人兼首席执行官 Vipul Ved Prakash 表示:“凭借 GB200 NVL72 和 Together AI 的定制化优化方案,我们在 DeepSeek-V3 等 MoE 模型的大规模推理工作负载表现已超越客户预期。这些性能提升源于 NVIDIA 的全栈优化技术,结合了 Together AI 在内核、运行时引擎和推测解码等领域的推理技术突破性进展。”
这种性能优势在其他前沿模型中同样显而易见。
Kimi K2 Thinking 作为最智能的开源模型,再次印证了其卓越性能——在 GB200 NVL72 平台部署时,其代际性能提升达 10 倍。

Fireworks AI 当前在 NVIDIA B200 平台部署 Kimi K2 使其在 Artificial Analysis(AA)的榜单上取得最高排名。
Fireworks AI 联合创始人兼首席执行官乔琳表示:“NVIDIA GB200 NVL72 机架级扩展设计使 MoE 模型运行效率大幅提升。展望未来,NVL72 有望彻底改变我们运行大规模 MoE 模型的方式,其相较于 Hopper 平台实现的重大性能飞跃,为前沿模型的运行速度和效率树立了全新标杆。”
Mistral Large 3 在 GB200 NVL72 架构上实现了相较前代 H200 10 倍的性能提升。这种代际飞跃为这款新型 MoE 模型带来了更优的用户体验、更低的每 token 成本以及更高的能效表现。
大规模驱动智能
NVIDIA GB200 NVL72 机架级扩展系统意在为除 MoE 模型之外的工作负载也提供强大的性能。
当我们审视 AI 的发展方向时,原因便不言而喻:新一代多模态 AI 模型拥有处理语言、视觉、音频等不同模态的专门化组件,并且仅会激活与当前任务相关的部分。
在智能体系统中,不同的"智能体"分别专精于规划、感知、推理、工具使用或搜索等任务,而编排器则统筹这些智能体以实现单一目标。这两种模式的核心逻辑都与 MoE 相呼应:将相关问题各部分分配给最相关的专家处理,再协调各环节输出以达成最终结果。
将这一原理扩展至大规模部署——即多个应用程序和智能体为众多用户提供服务的情境——将释放出全新的效率水平。这种方法无需为每个智能体或应用程序重复构建庞大的AI模型,而是建立一个共享的专家池供所有系统调用,确保每个请求都能精准路由至对应的专家。
MoE 模型是一种强大的架构,正引领行业迈向大规模能力、效率与规模并存的未来。GB200 NVL72 现已解锁这种潜力,而基于 NVIDIA Vera Rubin 架构的 NVIDIA 的路线图将持续拓展前沿模型的边界。
来源:业界供稿
好文章,需要你的鼓励


谷歌推出AI购物智能体,帮你“一站式“购物体验升级
谷歌在I/O开发者大会上发布"通用购物车"功能,基于通用商务协议(UCP)整合YouTube、Gmail、Gemini等平台的购物数据,支持Target、Shopify、Wayfair等主流零售商。AI代理可自动检测商品兼容性、推荐优惠信用卡、比价提醒,并在用户授权下自动完成日常采购。该功能旨在打通"加入购物车"到"完成结账"的全流程,实现个性化、无摩擦的购物体验。

浙大、港科大等联合机构告诉你:AI学“看“3D场景,到底该怎样聪明地“选角度“?
这项联合研究提出了COVER方法和CM-EVS数据集,用贪心算法从3D场景中智能筛选全景视角,每场景仅需25帧即可完整覆盖室内场景,并附完整溯源日志。


伦敦大学学院等多机构联合揭示:AI“调音旋钮“让大模型推理训练不再崩溃
HolderPO通过引入可调参数p的霍尔德均值替代固定的算术平均,解决了大模型推理训练中信号放大与稳定性之间的根本矛盾,配合动态退火策略在数学推理和代理任务上均创造了新的最优记录。
2025
12/08
11:39
分享
点赞

Apple Music发布公开信:致力于在AI时代维护音乐公平生态
NHS十年计划的成功关键:数字健康必须达到临床标准
xAI与Anthropic计算资源合作协议,揭示AI算力独立商业化新趋势
利用Ubicept Photon Fusion提升CMOS夜间成像性能
Humanoid与制造业巨头博世达成战略合作,推进人形机器人量产
企业网络基础设施是否已为AI工作负载做好准备?
AI遭Z世代抵制:CIO面临的人才培养危机
Flytrex在达拉斯开设无人机制造工厂,加速扩张外卖配送网络
Brain Corp与加州大学圣地亚哥分校合作推进物理AI基础智能层研究
哈丁视角:工厂竞争的现实法则——执行力才是制胜关键
Doozy Robotics宣布全球扩张,以AI人形机器人构建工厂自动化劳动力
华为AI DC全栈方案发布:以数据觉醒,驱动产业智能跃迁
