
Hot Chips|NVIDIA的下一块“未来版图” Spectrum-XGS 定义“行星级”AI超级工厂 原创
人工智能的竞赛,早已从模型算法的精细化比拼,演变为一场“水电煤”级别的“重工业”较量。以OpenAI、Google为首的科技巨头们,正在以前所未有的规模建设“AI工厂”——其作为由数万乃至数十万块GPU组成的庞大计算集群,是驱动AI时代创新的核心引擎。
伴随万亿参数模型的算力需求指数级爆涨,“AI工厂”的规模正迎来更高级形态——"十亿瓦级"AI工厂(Gigawatt-Scale AI Factory)。
但同时,一个严峻的物理挑战正横亘在所有“玩家”面前:规模极限!
一座数据中心的建设,受限于土地、能源和散热影响。目前,超大规模AI数据中心的功率上限普遍在100~150兆瓦左右。但在万亿、乃至未来十万亿参数模型的恐怖算力需求面前,显得捉襟见肘。当一个数据中心的“容量”被填满,唯一的出路就是——建造下一个。
于是,AI巨头们开始在全球范围内布局,数据中心如雨后春笋般涌现。而新的问题随之而来,这些地理上分散的“算力孤岛”,如何才能协同工作。
答案是“网络”。
然而,用于连接不同数据中心的广域网(WAN)或城域网(MAN),最初设计是为了满足网页浏览、视频会议等对延迟和抖动不敏感的通用应用需求。
相比之下,AI训练作为高度紧耦合的任务,需要数万个GPU以微秒级延迟、几乎零抖动的条件下完成海量数据交换(或者说“集合通信”,Collective Communications)。一旦网络出现极其细微的波动,都会让GPU集群被迫停滞等待,导致大规模算力的严重浪费。
这就构成了AI竞赛中的“下一公里”的难题,如何将分散在全球的AI工厂,无缝连接成一个十亿瓦级的AI超级工厂。
行业困顿之际,作为AI“风向标”的NVIDIA,带来了答案。在2025年8月22日的Hot Chips上,NVIDIA更新了一项重磅技术——Spectrum-XGS以太网。
该项技术是NVIDIA Spectrum-X以太网平台的全新拓展,其能够将Spectrum-X以太网的超高性能与弹性,延伸至多个分布式数据中心,并整合为具备“十亿瓦级”的超级AI工厂。 
这次发布,NVIDIA显然有着更深的考量。其用这张全新的“网”,拆掉“规模受限”这堵墙,为NVIDIA在AI计算版图上,拼上“下一块拼图”。
01 “Scale-Across”:AI计算的“第三大支柱”
“新工业革命已经到来,AI工厂是这场变革的核心基础设施。”这是 NVIDIA CEO 黄仁勋的标志性观点,也是整个行业正在形成的共识。
过去,NVIDIA在 AI计算依托两大核心支柱——Scale-Up(纵向扩展) 和 Scale-Out(横向扩展),逐步构建出如今的AI工厂雏形。
然而,当AI的规模扩张跨越单一数据中心的边界。面对"十亿瓦级"级的算力需求,仅依赖纵向和横向扩展,已无法满足全球化的训练和推理任务。这便是第三根支柱——Scale-Across(跨区域扩展)的使命。
该技术专为跨区域的算力整合而设计,能助力多座相互独立的数据中心融合成逻辑统一、性能一致的“十亿瓦级 AI 超级工厂”。
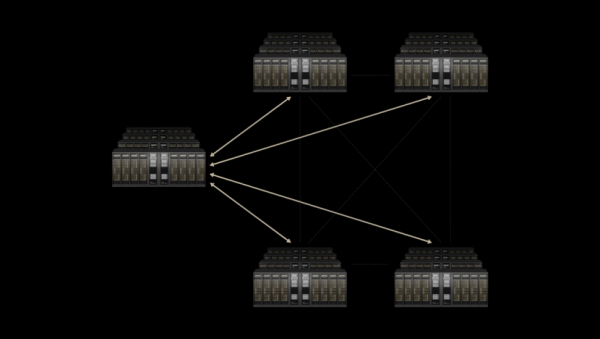
截取自NVIDIA官方资料
当然,Spectrum-XGS做的并不是将传统广域网(WAN)技术做迁移,而是在Spectrum-X 数据中心内部网络核心技术的基础上,进一步针对跨区域AI通信的复杂需求,进行了深度优化。具体而言在于三方面:
其一是动态距离适应。该网络能够自动感知数据中心之间的物理距离,并据此动态调整拥塞控制、路由和延迟策略,使距离不再是不可控的瓶颈,而成为可计算、可优化的变量。
其二是精准延迟管理与端到端遥测。通过先进算法有效抑制长距离传输中的抖动(Jitter),确保分布式训练与推理能够始终维持稳定、可预测的性能表现。
其三是性能的提升。NVIDIA官网数据显示,在跨区域场景下,Spectrum-XGS能将NVIDIA集合通信库(NCCL)的性能提升近1.9倍。其中,NCCL作为主流AI框架进行多GPU通信的基石,这一提升意味着,AI训练和推理的效率在跨区域数据中心场景下得到了根本性的改善。
目前,Spectrum-XGS已经进入实际部署阶段。云服务商CoreWeave已率先成为 优先部署Spectrum-XGS的合作伙伴。CoreWeave联合创始人兼CTO Peter Salanki表示:“通过 NVIDIA Spectrum-XGS,我们可以将数据中心连接成一个统一的超级计算机。”
02 Scale-Up、Scale-Out、Scale-Across NVIDIA“三位递进”的计算网络战略
Spectrum-XGS的发布,让NVIDIA的网络战略拼图,更加丰富。一个覆盖从芯片内部到全球范围的“三位一体”网络体系已经形成。
如果把世界比喻成一个主体,可以这样理解,Scale-Up的作用是连接AI的“超级大脑”的“神经束,Scale-Out得作用是连接同一城市中的所有大脑的“毛细血管”,而 Scale-Across 就是搭建起跨越区域的神经网络的“主动脉”,让全球的大脑像整体一样思考。
具体拆解这三层,也依托了NVIDIA一些列颠覆性技术和产品:
第一层:“神经束”Scale-Up—— NVLink与NVLink Fusion
AI 计算的最小单位,或许如今已经不再被定义为单个GPU。而是一个由 NVLink 互联形成的 GPU域。在最新的 Blackwell 架构 GB200 NVL72系统 中,NVIDIA 通过第五代 NVLink Switch,将72个GPU 以高达1.8 TB/s 的带宽进行全互联,整机聚合带宽更是高达130 TB/s——这个数字甚至超过了互联网骨干网的总带宽。
这种互联方式,具备了“内存语义”的连接,能够将所有GPU的显存融合为统一的巨大内存池,让大模型可以一次性完整加载,无需再在不同 GPU 之间进行复杂的数据切分和拷贝,有效提升模型训练和推理的效率,也让多GPU协同计算的上限,被进一步拉高。
更具战略意义的是,在今年的COMPUTEX 2025上,NVIDIA还推出了NVLink Fusion。该技术将机柜级“Scale-Up”开放,允许第三方(如大型云厂商 Hyperscaler)将自研的 CPU 或 XPU(专用处理器)通过标准化接口(如 UCIe)接入NVLink生态。
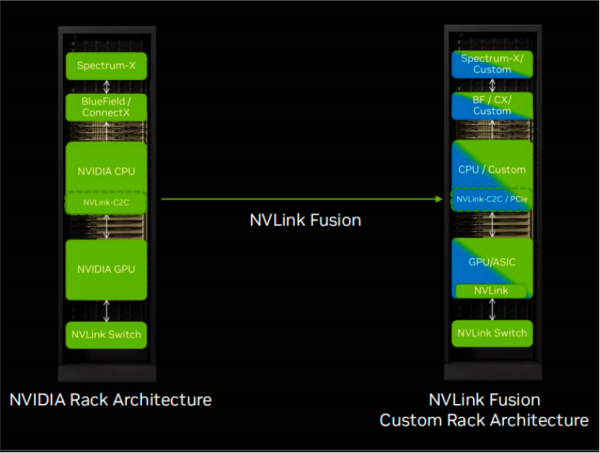
截取自NVIDIA官方资料
这一开放策略,进一步巩固了NVLink作为行业事实标准的地位,也通过更广泛的合作,吸引并绑定了生态伙伴,为NVIDIA的技术版图奠定了更牢固的基础。
第二层:“毛细血管”Scale-Out—— Spectrum-X以太网
当计算规模超出单个机柜,就需要“Scale-Out”模式将数千个节点连接起来。而NVIDIA提供的便是Spectrum-X以太网平台。
和为通用业务设计的传统以太网不同,Spectrum-X是为AI量身定制的。其通过RoCE(RDMA over Converged Ethernet)技术,结合自适应路由、拥塞控制机制,实现了接近无损、低延迟的数据传输。其核心组件包括:
其核心组件中,Spectrum 系列交换机可提供高密度、高带宽端口,构建AI网络的主干;ConnectX系列SuperNIC(超级网卡):能够将集合通信等复杂的网络任务从 CPU/GPU 卸载,在网卡层直接处理,从而显著降低通信开销。
根据NVIDIA的数据,Spectrum-X平台提供的带宽密度比传统以太网高出1.6倍,能够保证在拥挤的AI网络环境中依然维持高达95%的有效吞吐率,而传统以太网可能因冲突和丢包下降到60%甚至更低。
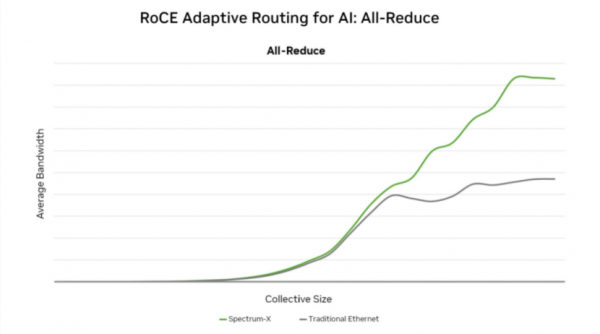
截取自NVIDIA官网
第三层是“洲际动脉”Scale-Across—— Spectrum-XGS
新推出的Spectrum-XGS将Spectrum-X的能力从数据中心内部延展至全球,通过克服长距离带来的物理限制,使得构建一个真正意义上的全球化超级AI工厂成为可能。这三层网络,从内到外,层层递进,共同构成了一个无缝、高效的AI计算基础设施。
03 技术底座“CPO”:拥抱光,告别铜
要支撑如此规模的网络,在带宽和能耗上,传统的电信号(铜缆)传输已力不从心。这一次,NVIDIA还推出了颠覆网络硬件形态的根本性创新产品——Co-Packaged Optics (CPO,共封装光学)。
其实,在传统交换机中,电信号由交换芯片(ASIC)输出后,需要经过PCB、电路连接器,最终到达可插拔光模块,在模块中被转换为光信号。这个过程路径长、环节多,因此带来了一系列问题。
一方面,信号衰减严重。电信号在长距离传输中损耗可达22dB,为了补偿损耗,必须依赖复杂的数字信号处理(DSP)芯片,这不仅增加了功耗,也延长了延迟。另一方面,功耗和散热压力巨大。单个高速可插拔光模块的功耗可达30W,而一个拥有数百个端口的交换机,仅光模块的功耗就可能达到数千瓦,成为数据中心的“电老虎”,同时带来严重散热难题。此外,可靠性低也是传统架构的痛点。可插拔模块和连接器是网络硬件中故障率最高的部分,长期运维成本高。
CPO技术彻底改变了这一格局。其可将负责光电转换的光学引擎(Silicon Photonics)与交换芯片ASIC,直接封装在同一基板上,光纤可以直接连接到这一集成模块。
这一创新带来了一系列优化。
具体而言,在信号完整性方面,信号路径被大幅度缩短,电气损耗从22dB降至约4dB,信号质量提升约64倍。
能效提升上,无需强大DSP和冗长的电路,每个端口功耗从30W降至9W,整体能效提升3.5倍。对于拥有数万个端口的AI工厂,这意味着每年可节省数百万甚至数千万美元的电费。
可靠性方面,大幅减少了分立元件和连接点,使网络硬件可靠性提高约10倍。
如今,NVIDIA已将CPO技术全面应用于下一代网络产品线,包括Spectrum-X Photonics和Quantum-X Photonics系列交换机。基于CPO的交换机单台即可提供高达409.6Tb/s的带宽和512个800Gb/s端口。
截取自NVIDIA官网
04 写在最后
从NVLink的“神经束”(Scale-Up),到Spectrum-X的“毛细血管”(Scale-Out),再到Spectrum-XGS的“洲际动脉”(Scale-Across),NVIDIA的“三位递进”战略阐述了一套关于规模、空间与协同的计算战略“方法论”。
依托这套方法论,NVIDIA通过多层次、统一的通信,构建出计算架构的“局部性原理”,让Spectrum-XGS以算法确定性对冲地理延迟,实现全球算力孤岛的微秒级同步,而基于CPO光子技术,则也标志着大规模计算通信从“电力时代”迈向“光力时代”。
NVIDIA将这一“宏观”与“微观”的“连接”融入世界AI版图时,真正的竞赛便已不在于GPU的数量,更在于,谁能构建让全球算力如单体般“思考”的“行星级”中枢系统。
如果规模极限不再成为阻碍,光与网络便铺就了新的前行阶梯!
好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

马萨诸塞大学的研究者们证明了:搜索引擎的“比较策略“在数学上优于传统方法
马萨诸塞大学从数学角度证明,MaxSim评分策略在理论能力上超越传统单向量内积方法,并提出Signed MaxSim扩展,显著改善否定查询性能。


新加坡国立大学与英伟达研究院联手打破视频生成的“非此即彼“困局:一个模型,两种能力,任意切换
新加坡国立大学与英伟达联合提出Flex-Forcing框架,通过时间帧和去噪步骤两个维度的灵活分块,将双向扩散和自回归视频生成统一到单一模型中,实现质量与效率的自由权衡。
2025
08/22
23:19
分享
点赞

“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
牙科诊所软件漏洞修复:患者医疗记录曾遭泄露
关键基础设施巨头Itron确认遭遇网络攻击
Vercel数据泄露范围扩大,黑客早于已知时间节点已入侵
苹果与博通签署300亿美元协议,共同生产美国本土无线芯片
摩托罗拉领投BRINC 1.25亿美元,推动紧急救援无人机大规模扩张
AI赋能芯片设计:前景广阔,疑问犹存
Arm今夏将推出自研芯片,Meta成首批客户
从AI崛起到智算中心腾飞,电力保障如何重新定义未来
AI再走一步,会发生什么?答案在“预见2026”
对话谷歌副总裁Karen Teo:“短剧”“AI应用”现象级出海,我们看到中国开发者的三种内核
少即是多:Google如何让软件开发变得“极简主义”
人人可享的超算力,Dell Pro Max with GB10让AI算力触手可及
多家机器人企业亮相WRC“秀肌肉” NVIDIA Jetson Thor成“标配”
EVOLVE 2025|跨越数据主权与云弹性 Cloudera“融合三部曲”定义AI转型“四重境界”
2025戴尔科技峰会 - 破局者 智行合璧
施耐德电气:当AI进入产业主场,核心技术+场景知识带来价值最大化
AI“变身”运维“老师傅” 施耐德电气用30年OT积累 打造更“懂行”的“楼宇智能体”
