
破解AI集群扩展中的关键瓶颈
人工智能(AI)正以前所未有的速度向前发展,整个市场迫切需要更加强大、更加高效的数据中心来夯实技术底座。为此,各个国家以及不同类型的企业正在加大对人工智能基础设施的投入。据《福布斯》报道,2025年,泛科技领域对人工智能的支出将超过2500亿美元,其中大部分投入将用于基础设施建设。到 2029 年,全球对包括数据中心、网络和硬件在内的人工智能基础设施的投资将达到4230亿美元。

德科技产品营销经理 Emily Yan
然而,人工智能技术的快速创新迭代也给数据中心网络带来了前所未有的压力。例如,Meta最近发布的有关Llama 3 405B模型训练集群的论文显示,该模型在预训练阶段需要超过700 TB的内存和16000颗英伟达H100 GPU芯片。据Epoch AI预计,到2030年,人工智能模型所需的计算能力将是目前领先模型的1万倍。
如果企业拥有数据中心,那么部署人工智能只是时间问题。此篇是德科技署名文章旨在探讨人工智能集群扩展面临的关键挑战,同时揭示为何“网络会是新的瓶颈”。
人工智能集群的崛起
所谓人工智能集群就是一个高度互联的大型计算资源网络,用于处理人工智能工作负载。
与传统的计算集群不同,人工智能集群针对人工智能模型训练、推理和实时分析等工作任务进行了优化。它们依靠数千个GPU、高速互连和低时延的网络来满足人工智能对密集计算和数据吞吐量的要求。
建设人工智能集群
人工智能集群的核心功能类似于一个小型网络。构建人工智能集群需要将GPU连接起来,形成一个高性能计算网络,让数据在GPU之间实现无缝传输。这其中强大的网络连接至关重要,因为分布式训练往往需要使用数千个GPU进行长时间并行计算。
人工智能集群的关键组成部分
如图1所示,人工智能集群由多个重要部分组成。
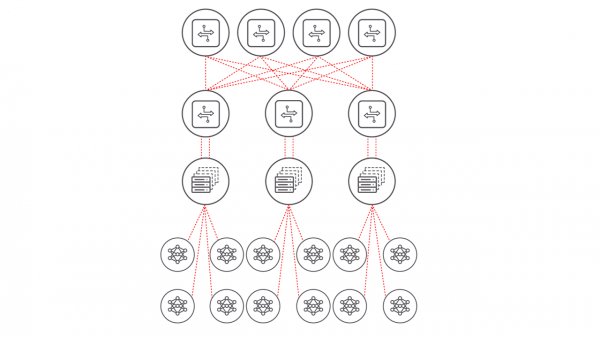
图1:AI数据中心集群
- 计算节点如同人工智能集群的大脑,由成千上万个GPU组成并连接到了机架顶部的交换机。随着复杂性的提升,对GPU的需求也在增加。
- 以太网等高速互联技术可实现计算节点之间的快速数据传输。
- 网络基础设施包括网络硬件和协议,它们能够支持在数千个GPU之间进行长时间的数据通信。
扩展人工智能集群
人工智能集群可进行扩展,以应对日益增长的人工智能工作负载和复杂性。直到近期,由于网络带宽、时延等因素的限制,人工智能集群的规模局限在约3万个GPU。然而,xAI Colossus超级计算机项目打破了这一局限,将所使用的GPU数量扩展到了超过10万颗英伟达H100 GPU芯片,网络和内存技术的进步使得这一突破成为可能。
扩展面临的关键挑战
随着人工智能模型的相关参数增长到数万亿个,人工智能集群的扩展会遇到大量来自技术和财务层面的阻碍。
网络挑战
GPU可以有效地执行并行计算。然而,当数千个甚至几十万个GPU在人工智能集群中共同执行同一工作任务时,如果其中一个GPU缺乏所需的数据或遇到延迟等情况,其他GPU的工作就会停滞不前。这种长时间的数据包延迟或网络拥堵造成的数据包丢失会导致需要重新传输数据包,从而大幅延长了任务完成时间(JCT),造成价值数百万美元的GPU闲置。
此外,人工智能工作负载产生的东西向流量,也就是数据中心内部计算节点之间的数据迁移,急剧增加,如果传统的网络基础设施没有针对这些负载进行优化,可能会出现网络拥堵和延迟问题。
互联挑战
随着人工智能集群规模的拓展,传统的互连技术可能难以支持必要的吞吐量。为了避免瓶颈问题,企业必须进行升级迭代,采用更高速的互连技术,如800G甚至1.6T的解决方案。然而,要满足人工智能工作负载的严格要求,部署和验证此类高速链路并非易事。高速串行路径必须经过仔细调试和测试,以确保最佳的信号完整性、较低的误码率和长距可靠的前向纠错(FEC)性能。高速串行路径中的任何不稳定因素都会降低可靠性并减慢人工智能训练的速度。企业需要采用高精度、高效率的测试系统,在高速互联技术部署前对其进行验证。
财务挑战
扩展人工智能集群的总成本远远不止于购买GPU的花费。企业必须将电源、冷却、网络设备和更广泛的数据中心基础设施等相关投入考虑在内。然而,通过采用更出色的互连技术并借助经过优化的网络性能来加速处理人工智能工作负载,可以缩短训练周期,并释放资源用于执行其他任务。这也意味着每节省一天的培训时间,就能大幅降低成本,因此对于财务风险和技术风险需要给予同等的重视。
测试和验证面临的挑战
优化人工智能集群的网络性能需要对网络架构和GPU之间的互连技术进行性能测试和基准测试。然而,由于硬件、架构设计和动态工作负载特性之间的关系错综复杂,对这些器件和系统进行验证具有很大的挑战性。主要有三个常见的验证问题需要解决。
第一,实验室部署方面的限制
人工智能硬件成本高昂、可用的设备有限以及对专业网络工程师的需求缺口,使得全盘复制变得不切实际。此外,实验室环境通常在空间、电力和散热方面受到限制,与现实世界的数据中心条件不同。
第二,对生产系统的影响
减少对生产系统的测试可能会造成破坏,并影响关键的人工智能操作。
第三,复杂的人工智能工作负载
人工智能工作负载和数据集的性质多种多样,在规模和通信模式上也有很大差异,因此很难重现问题并执行一致性的基准测试。
人工智能将重塑数据中心的产业格局,因此构建面向未来的网络基础设施对于在技术和标准快速演进的过程中保持领先地位至关重要。是德科技先进的仿真解决方案可在部署前对网络协议和系统运行的场景进行全面验证,进而帮助企业获得关键优势。是德科技致力于帮助网络工程师降低人工智能工作负载的复杂性并优化网络性能,从而确保系统的可扩展性、效率,并为应对人工智能需求做好充分准备!
来源:业界供稿
好文章,需要你的鼓励


据说算力高达1000 TOPS,华硕Ascent GX10深度评测——开箱
当超级计算机被压缩进一个比书本还小的盒子里,这画面有多炸裂?想象一下,你桌面上摆着的不是什么花瓶摆件,而是一台能跑200B参数AI推理的"超算怪兽"——这就是我们今天要聊的主角:华硕Ascent GX10。

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的“稀疏化魔法“
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。


不用再训练AI模型,香港科技大学团队发明“智能管家“,让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。
2025
04/30
17:32
分享
点赞

据说算力高达1000 TOPS,华硕Ascent GX10深度评测——开箱
苹果发现:只需一个注意力层,就能让AI图像生成既快又好
YouTube推出基于Gemini 3的创作者游戏制作工具
英伟达是唯一能负担免费提供AI模型的厂商
OpenAI发布新旗舰图像生成AI模型GPT Image 1.5
脑启发算法可大幅降低AI能耗
Mac办公桌升级必备配件指南:提升工作效率的最佳选择
PTC Windchill+ 助力 HOLON研发全球首批符合汽车行业标准的 L4 级电动汽车
航旅行业的AI“乘法效应”:迈向指数级进化
OpenAI推出GPT Image 1.5模型加速图像生成竞争
Zoom推出AI Companion 3.0智能体工作流程
ChatGPT成为互联网最受阻止的爬虫机器人
