
独家揭秘DeepSeek核心优势:动态思维链与内置专家模型
一、DeepSeek横空出世,震惊全球
2025年初,中国人工智能企业深度求索(DeepSeek)凭借其革命性大模型DeepSeek-R1引爆全球科技界。这款模型以极低成本(仅为GPT-4的十分之一)实现顶尖性能,在数学解题(MATH测试准确率77.5%)、编程竞赛(Codeforces评分超越96%人类)等核心领域与OpenAI旗舰产品平分秋色,甚至在中文语境理解上更胜一筹。
DeepSeek-R1上线首周即登顶中美苹果应用商店免费榜,引发美股科技股震荡(英伟达单日市值蒸发5900亿美元),美国总统特朗普更公开表示“这为美国企业敲响警钟”。随后OpenAI创始人奥特曼表示,GPT5.0发布后将采用免费策略。
对普通用户而言,DeepSeek有两个显著的优越特性:动态思维链和内置专家模型。本文以深入浅出的语言揭秘这两个特性。
二、对动态思维链的深度解析
思维链的本质探究
动态思维链在DeepSeek架构中占据着非常重要的地位,其本质是对人类复杂思维过程的高度模拟。人类在面对难题时,会凭借逻辑思维和经验,将大问题拆解为一个个小问题逐步攻克。
DeepSeek 的动态思维链正是借鉴了这一智慧,通过先进算法把输入任务细化为多步骤,并引导模型有序执行。这一机制使得模型在处理任务时,能像人类一样有条理地思考,极大地提升了其解决问题的能力。
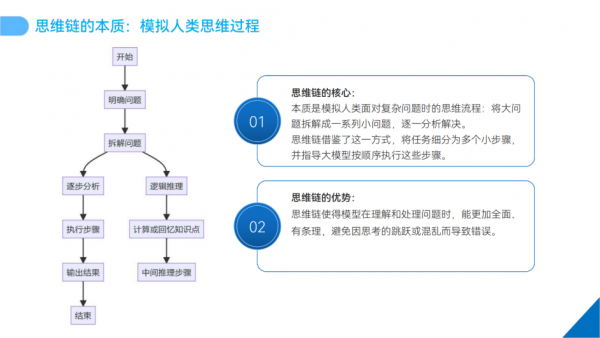
比如当它遇到一个复杂的商业决策问题时,如企业要制定新的市场拓展策略,思维链会促使模型先分析企业当前的市场地位、产品优势与劣势,再研究目标市场的需求、竞争态势等因素,最后综合考虑得出可行的策略建议,整个过程严谨且有序。
思维链的优势体现
动态思维链为DeepSeek带来了多方面的显著优势。在理解和处理复杂问题上,它使模型的思维更加全面、系统。与传统模型相比,传统模型可能会因问题复杂性陷入困境或得出片面结论,而DeepSeek的思维链能让模型从宏观到微观深入分析,不放过任何关键细节。
在处理自然语言理解任务中,对于一段含义模糊、包含隐喻的文本,思维链会引导模型先剖析句子结构,确定关键词,再结合上下文和语义知识进行多轮推理,从而准确把握文本的真正含义,大幅提高了语言理解的准确性和深度。
三、内置专家模型的工作机制揭秘
DeepSeek的内置专家模型(MoE,混合专家模型)就好比一个由多个专业领域专家组成的团队,每个专家都有自己擅长的领域,而一个“指挥官”(门控网络)决定每个任务由哪些专家来处理。
具体来说,DeepSeek的专家模型工作原理可以分为三个关键步骤:路由、计算和聚合。首先,输入的任务(比如一段文本)会被“指挥官”(门控网络)评估,它会根据任务的特点,决定哪些专家最适合处理这个任务。比如,处理数学问题时,会分配给擅长数学的专家;处理情感分析时,会分配给擅长语言情感的专家。
接下来,被选中的专家会开始工作,处理分配给他们的任务。每个专家只负责自己擅长的部分,这样既高效又精准。最后,所有专家的处理结果会被“指挥官”加权合并,形成最终的答案。
DeepSeek的专家模型还有一个很厉害的地方,就是它采用了“稀疏激活”机制。DeepSeek的每个混合专家层配置了1个共享专家与256个路由专家,每个词能激活8个专家,极大提升了大模型的洞察力。这意味着每次处理任务时,只有少数专家会被激活,而不是让所有专家都参与计算。这样一来,模型在处理复杂任务时,不仅速度快,而且计算资源的消耗也大大减少。
这种设计让DeepSeek在面对各种复杂任务时,都能灵活应对,同时保持高效的性能。混合专家模型的设计更为合理,标志着大模型由概率模型走向专家模型,它的火爆让全球首次见证中国企业主导的AI技术革命性创新的强大力量。
四、动态思维链与内置专家模型的协同工作机制
这里将动态思维链与内置专家模型协同工作的关键步骤简单讲解如下。
问题解构剖析
当接收到用户的问题后,DeepSeek 首先调用相关专家模型对问题进行解构。这一过程旨在识别问题的核心主题、关键要素以及它们之间的逻辑关系。
例如,对于“在智能交通系统中,如何利用深度学习技术优化交通流量预测并减少拥堵?”这个问题,模型会将其解构为“智能交通系统的现状与特点”“深度学习技术在交通流量预测中的应用原理和方法”“影响交通拥堵的因素分析”“优化交通流量预测与减少拥堵的关联和策略”等多个子问题,为后续的处理提供清晰的方向。
专家模型智能调度
在完成问题解构后,DeepSeek 根据子问题的性质和需求,自动调度相应的内置专家模型。这些专家模型涵盖了众多领域和专业知识,如交通工程、计算机科学、数学、统计学等。
对于上述智能交通问题中的交通流量预测子问题,模型会调度专门的交通数据分析和机器学习专家模型,该模型能够利用其内置的专业算法和大量的交通数据案例,对交通流量的历史数据进行分析和建模;对于深度学习技术应用子问题,则会调用人工智能领域的专家模型,提供关于深度学习模型架构、训练方法和优化策略的专业建议;对于交通拥堵因素分析子问题,会启用交通规划和城市管理方面的专家模型,从道路设施、交通规则、人口流动等多个角度进行综合分析。
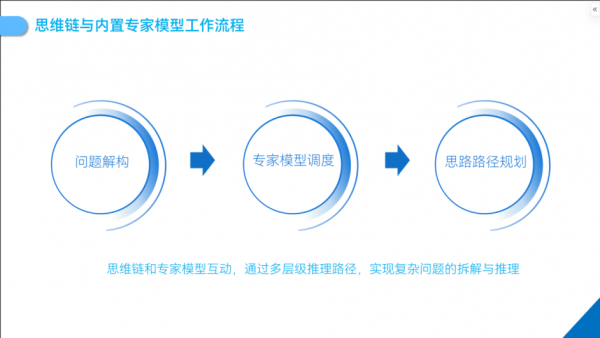
思路路径规划与推理
在专家模型被调度后,DeepSeek 通过思维链为解决问题规划出合理的思路路径。它根据问题的逻辑结构和各个专家模型的处理能力,确定每个子问题的解决顺序和方法,并引导专家模型之间进行信息交互和协同工作。
比如在规划智能交通问题的解决路径时,专家模型会先利用交通数据收集和预处理专家模型对交通流量数据进行清洗和整理,然后通过数据分析和机器学习专家模型构建交通流量预测模型,接着利用专家模型对预测模型进行优化和改进,最后再结合交通拥堵分析专家模型和城市规划专家模型,根据预测结果制定减少交通拥堵的策略和措施,如调整信号灯时间、优化道路布局等。在整个过程中,思维链不断地对各个环节的结果进行评估和反馈,确保问题的解决过程朝着最优方向推进。
通过思维链和内置专家模型的紧密协同工作,DeepSeek 能够高效地处理各种复杂问题,为用户提供高质量的回答和解决方案。这种独特的工作机制使得DeepSeek在人工智能领域具有显著的优势,无论是在学术研究、工业应用还是日常生活中的问题求解,都发挥出重要的作用,成为推动智能技术发展和应用的关键力量。
随着DeepSeek的不断进步和数据的持续积累,思维链和内置专家模型还会进一步优化和完善。未来它将能够处理更加复杂和多样化的问题,在更多领域展现出更高的准确性和效率。
附:动态思维链和专家模型解析实例
知识检索与信息收集
当用户询问“哪吒两个字的正确读音是什么”时,DeepSeek R1 联网版迅速启动强大的知识检索和信息收集机制。它一方面在自身庞大的预训练库中搜索与哪吒读音相关的信息,另一方面利用联网功能,广泛查阅各类权威资料,包括但不限于字典、学术文献、语言研究报告等。
在这个过程中,它获取到了来自不同地区和领域的丰富信息,如内地权威辞书《新华字典》和《现代汉语词典》的注音,台湾地区的《国语辞典》记录,以及港澳地区的常见读音情况,同时还收集到了一些关于方言读音和历史演变的资料,为后续的分析提供了全面的数据支持。

信息分析与整合优化
收集到大量信息后,DeepSeek内置的专家模型和动态思维链对这些信息进行深入分析和整合。它能够敏锐地识别出信息中的重复、矛盾和不完整之处,并进行合理的筛选和优化。
当发现某些网页对哪吒读音的解释存在简单重复或不够准确的情况时,模型会依据权威来源和学术共识进行判断和修正。对于“哪”字读音的不同解释,模型会深入研究古代韵书和语音演变规律,特别是果摄字的演变对其的影响,从而确定在“哪吒”一词中“哪”字的准确读音为“né”,并将相关的分析过程和依据融入到最终的回答中。
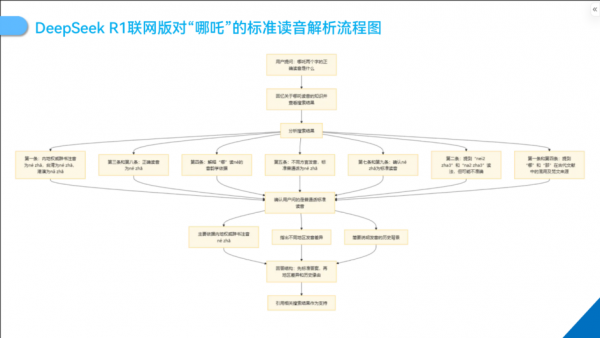
需求确认与精准回答构建
在完成信息分析和整合后,DeepSeek R1 联网版会根据用户的问题需求进行精准定位和回答构建。由于问题明确要求“正确读音”,模型判断用户需要的是普通话的标准发音,因此主要依据内地权威辞书的注音“né zhā”来组织回答内容。
在回答中模型不仅清晰地给出了标准普通话读音,还详细阐述了每个字的发音特点和声调,此外还深入探讨了读音的演变历史,的确表现出一个“思维缜密的专家”的特征。
来源:业界供稿
好文章,需要你的鼓励



Allen AI团队推出SAGE:首个能像人类一样“想看多长就看多长“的智能视频分析系统
Allen AI研究所联合多家顶尖机构推出SAGE智能视频分析系统,首次实现类人化的"任意时长推理"能力。该系统能根据问题复杂程度灵活调整分析策略,配备六种智能工具进行协同分析,在处理10分钟以上视频时准确率提升8.2%。研究团队创建了包含1744个真实娱乐视频问题的SAGE-Bench评估平台,并采用创新的AI生成训练数据方法,为视频AI技术的实际应用开辟了新路径。

联想推出DE6600系列:更智能的存储解决方案
联想推出新一代NVMe存储解决方案DE6600系列,包含全闪存DE6600F和混合存储DE6600H两款型号。该系列产品延迟低于100微秒,支持多种连接协议,2U机架可容纳24块NVMe驱动器。容量可从367TB扩展至1.798PiB全闪存或7.741PiB混合配置,适用于AI、高性能计算、实时分析等场景,并配备双活控制器和XClarity统一管理平台。

AI视觉模型真的能看懂长篇文档吗?中科院团队首次揭开视觉文本压缩的真相
中科院团队首次系统评估了AI视觉模型在文本压缩环境下的理解能力,发现虽然AI能准确识别压缩图像中的文字,但在理解深层含义、建立关联推理方面表现不佳。研究通过VTCBench测试系统揭示了AI存在"位置偏差"等问题,为视觉文本压缩技术的改进指明方向。
2025
02/17
16:09
分享
点赞

数智时代,openGauss Summit 2025即将发布哪些技术创新破局
“算力+储能”深度融合:超智算发布分布式算力超级节点储能解决方案
联想推出DE6600系列:更智能的存储解决方案
创业公司如何在严格监管行业中实现生死攸关的创新
OpenAI发布GPT-5.2-Codex模型,软件工程自动化能力大幅提升
Waterfox浏览器宣布拒绝AI功能,瞄准Firefox忠实用户
TikTok美国业务出售交易将于下月完成
破局AI数据中心安全瓶颈:Fortinet联合NVIDIA引领隔离式加速新航向
智算中心进化论,科华数据如何做到“更懂”
更高负载、更快建设:2026年数据中心六大趋势
Snowflake数据库更新引发全球大规模服务中断
AI编程初创公司Lovable融资3.3亿美元,英伟达等科技巨头支持
