
AI 2.0时代的存储“进化论” 原创
在以大模型为核心的AI 2.0时代,数据处理能力已成为需求端的重要标准。这一时期,模型生产的成本主要取决于数据处理资源的投入。随着尺度定律在大语言模型、多模态模型、视频生成模型以及慢思考推理过程中得到验证,生产和使用大模型的成本可以直接等同于数据处理资源的消耗。
AI应用在训练阶段,通常需要处理大量的数据和参数,涉及数亿个参数,并依赖于强大的计算资源来支持高效的数据处理和存储。推理阶段则要求模型快速处理输入数据并给出准确结果,因此对延迟和带宽提出了更高要求。
以大语言模型(LLM)为例,近年来,诸如GPT-3和GPT-4等模型的规模迅速增长,参数量从数十亿增加至数千亿,甚至上万亿。这种指数级的增长意味着传统内存技术难以满足AI在计算量、带宽和响应时间方面的严苛需求。

HBM因“AI”进化
高带宽存储(HBM)内存正是为了解决这些需求而诞生的。HBM(高带宽内存)具有高带宽和高密度,远超普通DRAM,可以广泛应用于AI训练、高性能计算和网络应用。HBM内存以其独特的堆叠式设计和硅中介层连接方式,显著提高了带宽和数据传输效率。与传统的DDR和GDDR内存相比,HBM内存不仅具有更高的带宽和容量,而且在物理空间上实现了高效利用,通过将多个DRAM芯片堆叠在一起,并通过硅中介层进行高速连接,实现了比标准PCB更高密度的信号路径,从而极大提升了内存的整体性能。
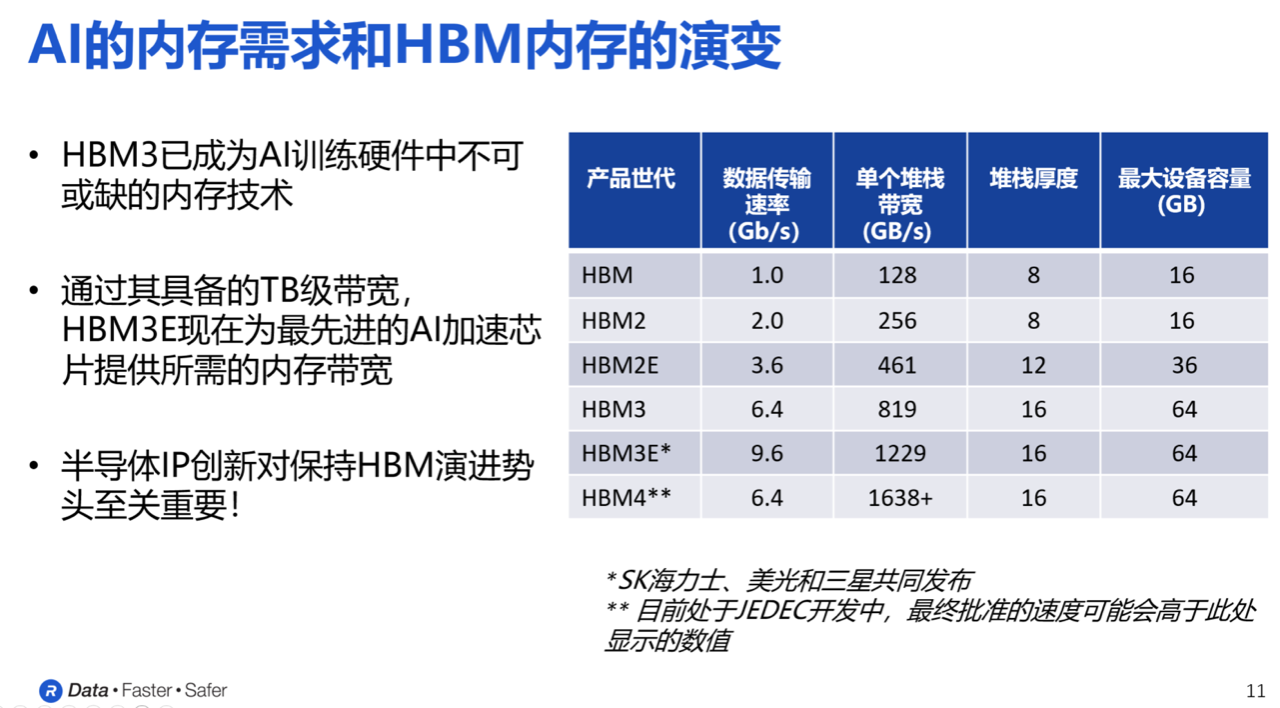
从HBM第一代到HBM3E,单个堆栈的带宽显著增加,HBM3E已超1.2TB/s,数据传输速率达9.6Gbps。目前,SK海力士、美光、三星已推出HBM3E产品,向光行业更是正子啊研发新一代的HBM4,由JEDEC制定标准,单堆栈带宽预计达1.6TB/s。Rambus作为内存控制器IP提供商,在高性能HBM内存的应用中起着关键作用。
从HBM第一代到HBM3E,单个堆栈的带宽不断提升,HBM3E的带宽已超1.2TB/s,数据传输速率达9.6Gbps。内存行业在推出越来越快的HBM内存器件,SK海力士、美光、三星已推出HBM3E产品。并正在积极研发由JEDEC制定标准的下一代HBM4,从单个堆栈的角度来看,HBM4的带宽将达到1.6TB/s
而在这一过程中,内存控制器IP能够帮助客户在其最先进的处理器与加速器中实现性能的突破式提升,满足生成式AI和高性能计算(HPC)工作负载的需求。而业界领先的半导体IP和芯片提供商,Rambus在这一领域中发挥着重要作用,确保用户能够充分利用这些高性能的HBM内存。
“Rambus在过去34年间开发了约2800项专利及专利申请,目前其芯片产品是公司最大的、增长最快的产品系列。这些芯片为DDR4和DDR5内存模块提供除DRAM外所有所需的模块组件,形成了完整的模块解决方案,并提供一站式服务。”Rambus大中华区总经理苏雷如是说。
近日,Rambus更是宣布推出业内首款HBM4控制器IP,旨在加速下一代AI工作负载。

Rambus大中华区总经理 苏雷
首款HBM4控制器IP ——2.0时代的AI“加速器”
Rambus研究员兼杰出发明家Steven Woo博士表示,该控制器IP支持新一代HBM内存的部署,适用于AI加速器、图形处理器和高性能计算等最前沿的处理器应用。

Rambus研究员兼杰出发明家Steven Woo
Rambus控制器IP的高带宽存储解决方案,不仅继承了前几代HBM的优势,更在性能和灵活性上实现了突破,帮助AI系统应对训练和推理阶段不同的内存需求。
Rambus HBM4控制器IP提供了32个独立通道接口,总数据宽度可达2048位。基于这一数据宽度,在数据速率为6.4Gbps时,HBM4的总内存吞吐量超过HBM3两倍,达到1.64TB/s。这使得HBM4在满足高带宽内存需求的应用场景中具有显著优势。
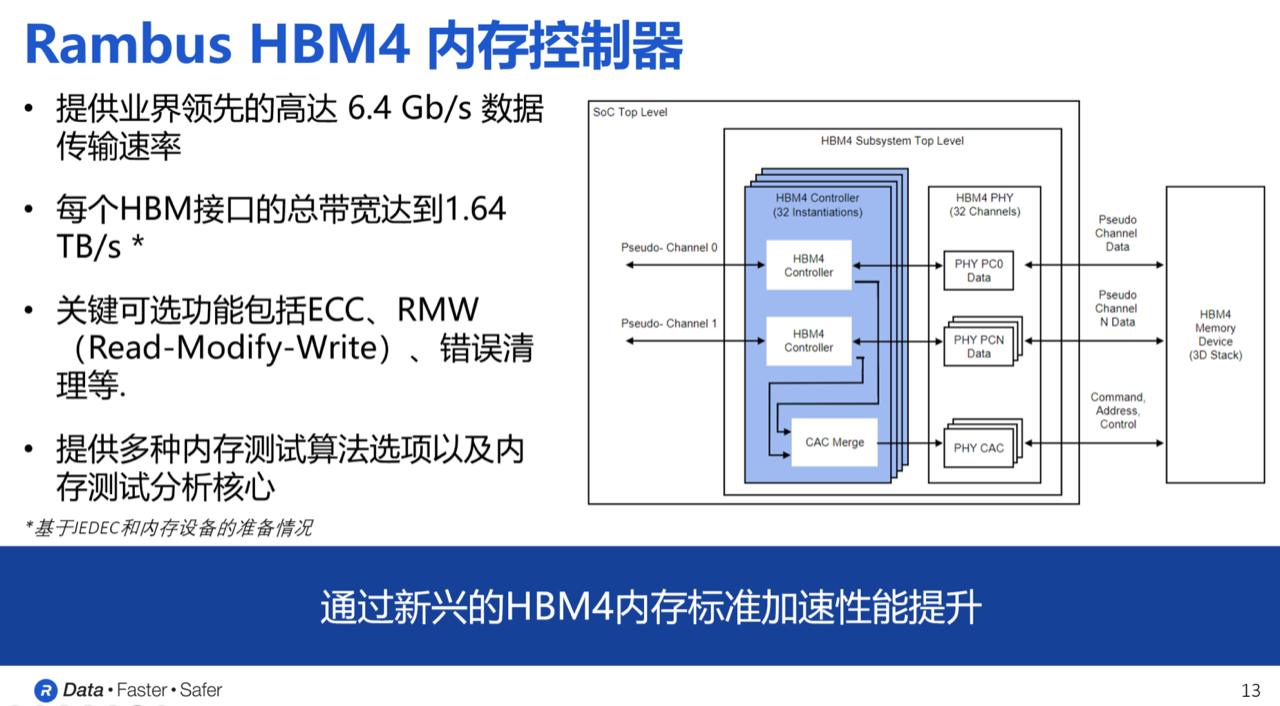
与上一代HBM3E控制器IP一样,HBM4控制器IP保持了模块化和高度可配置的设计特点,并且能够根据用户的应用需求,提供针对尺寸、性能和功能等方面的定制化服务。关键可选功能包括ECC(错误校正码)、RMW(读-修改-写)以及错误清理功能,确保系统的稳定性与可靠性。
对于AI应用而言,Rambus 半导体IP还能通过高性能接口和硬件级安全实现加速计算。
事实上,Rambus HBM4控制器支持新一代HBM内存部署,适用于尖端AI加速器、图形和HPC应用。其解决方案包括内存接口、安全IP及芯片到芯片互联协议,涵盖HBM、GDDR内存控制器,以及PCIe和CXL等关键控制器,致力于为各种AI应用和先进处理器提供卓越的性能与安全性。
具体而言,在内存控制器方面,Rambus提供了内存内加密(IMI)解决方案,确保数据在加速器与内存间传输的安全。同时,通过PCIe和CXL连接处理器时,提供数据完整性和加密功能来保障传输链路的安全性。其信任根IP还可通过安全启动、数字身份和认证签名等方式,增强硬件和数据的安全防护。
整合以上模块,Rambus的IP产品组合实现了从内存到处理器的最高带宽数据传输,以及处理器与设备之间的高速交互。同时,通过对静态、使用中和传输中的数据进行全面保护,确保了数据的安全性,为高性能AI解决方案提供了坚实保障。
帮助客户一次流片成功
为了确保客户在开发过程中能够顺利集成,Rambus与领先的第三方PHY供应商合作,为客户提供多样化的选择,帮助他们实现一次流片成功。这一合作模式为客户在开发和部署新一代HBM4内存解决方案时提供了更高的灵活性和成功率。
具体而言,在控制器测试和验证方面,Rambus提供了一整套全面的解决方案,旨在帮助用户顺利完成控制器代码库的回归测试。通过Rambus的控制器测试平台,用户可以轻松执行包括控制器和PHY在内的各种测试序列,确保产品的质量和一致性。此外,Rambus还引入了基于功能覆盖率的验证计划,以保障测试的完整性和可靠性。
在与西门子旗下Avery Design Systems的紧密合作中,Rambus提供了全面的验证IP,支持多种BFM(总线功能模型),包括内存模块BFM、主机内存控制器BFM和PHY BFM。

此外,Rambus还提供适用于汽车、IoT、政府等不同领域的认证解决方案,Steven Woo举例称:“Rambus的IP解决方案在功耗和面积方面经过优化,并且由我们的支持团队提供保障,确保客户第一次流片即成功。 ”
写在最后
Rambus的HBM4控制器再次巩固了其在行业中的领先地位,体现了其在接口和安全数字IP方面的深厚技术积累,尤其是在人工智能领域的应用场景中展现出卓越的优势。通过在多个HBM代际中成功的客户实施,Rambus积累了丰富的经验,并与行业领先的IP供应商携手,提供了完善的HBM子系统解决方案,确保客户在设计上的一次流片成功。这种整合能力和合作深度无疑展现了Rambus在高性能存储解决方案领域的独特竞争力。
在客户服务方面,Rambus更是凭借多年的HBM经验和专业技术在全球市场中位居前列。其先进的技术如信号和电源完整性,强大的售中售后支持,以及对客户的技术问题快速响应,使其产品深受中国客户信任。
对于未来产品的迭代,正如苏雷所言——我们将提前识别和规避技术难题,持续为客户推出新产品,并努力保持全球领先。
来源:至顶网计算频道
好文章,需要你的鼓励


ServiceNow或以超10亿美元收购网络安全初创公司Veza
据报道,ServiceNow正与身份管理平台初创公司Veza进行深度收购谈判,交易金额可能超过10亿美元。Veza的平台帮助企业保护员工工作账户安全,识别未使用账户和权限过度的账户,还能检测违反职责分离政策的账户。该平台还可管理机器身份和应用程序集成。此次收购将补强ServiceNow在用户账户和机器身份管理方面的功能短板。

罗切斯特理工学院推出SPHINX:让AI像人类一样“看懂“复杂视觉推理问题
罗切斯特理工学院团队开发SPHINX系统,专门测试AI视觉推理能力。该系统可无限生成25类视觉推理题目,测试发现最强的GPT-5准确率仅51.1%,远低于人类75.4%。研究显示AI主要困难在视觉信息提取而非逻辑推理,通过强化学习训练可显著改善表现并迁移到其他任务。

谷歌云推出“PanyaThAI“计划加速泰国AI应用
谷歌云发布PanyaThAI数字化转型计划,旨在帮助泰国企业部署企业级AI智能体应用。该计划首批支持15家机构,包括朱拉隆功大学、泰国证券交易所等。研究显示AI到2030年可为泰国经济贡献7300亿泰铢。计划提供全栈AI基础设施、咨询服务和员工培训,合作伙伴将培训300名本地专家。已有企业展示成果,如SE-Education通过AI语义搜索将转化率从12%提升至27%。

法国理工学院揭秘:让机器像医生一样预判设备“寿命“的突破性技术
法国理工学院研究团队开发的I-GLIDE系统,通过将复杂设备拆解为多个子系统分别诊断,结合不确定性量化技术,实现了设备剩余寿命预测的重大突破。该系统在NASA飞机引擎数据集上的预测误差比传统方法降低23-39%,同时提供了前所未有的可解释性,能够精确指出具体组件的健康状况,为工业智能维护提供了新的解决方案。
2024
11/21
10:44
分享
点赞

ServiceNow或以超10亿美元收购网络安全初创公司Veza
谷歌云推出"PanyaThAI"计划加速泰国AI应用
英国产学合作推进光纤射频通信技术商业化进程
阿里巴巴推出可换电池设计的Quark AI智能眼镜
CIO影响力提升的关键:构建内部联盟
跨越AI落地鸿沟:数据体系才是“AI-Ready”的决定性变量
高带宽闪存面临工程难题,商业化还需数年时间
戴尔Q3季度AI服务器收入破纪录,存储业务表现不佳
Mixpanel数据泄露事件波及部分OpenAI API用户账户信息
Procure AI获1300万美元融资,用智能体自动化采购流程
GigaOm评选Vespa.ai为顶级向量数据库
梅赛德斯-AMG Petronas F1车队运用增强现实技术提升测试效率
