
思科将大规模AI基础设施塞入小型服务器套件

思科计算高级副总裁兼总经理Jeremy Foster在最近的IT供应商客户顾问委员会会议上,就发现几乎所有企业都正在不同程度地开展AI项目。
Foster在采访中指出,“其中一些项目可能是从云端起步,有些项目可能是从本地项目开始,但总体上这种变化趋势要比过去六个月乃至更久之前明显加快。我们也相信这股势头还将持续下去。其中一些企业已经提交了初始订单,正在等待交付。在预约到交付之间的这段时间,他们正积极设计用例并思考如何开发应用程序以创造价值。尽管仍处于早期规划阶段,但对生成式AI项目的应用占比已经从原先的十之一二快速增长至如今的十之八九。相信在收到设施资源之后,他们会立即行动起来。”
而企业必须面对的一大现实挑战,就是确保掌握运行AI工作负载所需要的正常基础设施。根据思科的AI就绪指数,89%的受访IT专业人士表示他们计划在未来两年之内部署AI工作负载,但只有14%的受访者确认其基础设施已经为这类新型工作负载做好了准备。而对基础设施的全面改造,往往是一项昂贵且复杂的任务。
思科希望通过本周在洛杉矶合作伙伴峰值上公布的全新硬件产品,让这场转型来得更轻松、更便宜。相关产品基于其UCS产品组合以及经过验证的设计方案,努力将更多所需技术整合进这些高度集成的系统当中。这些产品对于正权衡到底是在云端、抑或是本地执行AI任务的企业来说,不啻于一份厚礼。
思科计算产品管理副总裁Daniel McGinniss在采访中表示,“我们看到很多客户更倾向于选择本地部署,而具体基础设施模式则视工作负载需求而定。比如说以企业身份在云端运行模型训练,而后再转向本地。业务数据一般都集中在本地设施之内,这一点非常重要。因此对于最重要、对业务影响最大的应用程序,企业肯定更希望能在本地基础设施上运行。这也符合我们观察到的普遍情况,即将全部业务用例都汇总起来,尽可能排除干扰和外泄因素。总之,不同需求对应的基础设施模式也是各不相同的。企业可能会在CPU上运行推理,但不会在CPU上运行训练。我们的不少大型企业客户则更加灵活,可能在云端进行模型训练,也有可能在本地基础设施上完成训练。”
在本次会议上,思科发布了UCS C885A M8服务器,专门用于处理大规模GPU密集型AI训练与推理任务。这是UCS产品家族中的最新成员,思科于2009年首次公布了这条产品线,当时希望在网络之外进一步拓展数据中心业务,借此与戴尔、惠普等厂商在计算领域展开竞争。

UCS C885A M8以英伟达的HGX超级计算平台作为构建基础,包含8张英伟达H100或H200 Tensor Core GPU或者8张AMD MI300X OAM GPU加速器(后续预计还将支持英特尔芯片),且每张GPU都配备一块英伟达ConnectX-7网络接口卡(NIC)或BlueField-3 SuperNIC,允许客户在服务器集群之上运行AI模型的训练工作负载。另有英伟达BlueField-3数据处理单元(DPU),同时配备两块AMD第四代或第五代EPYC芯片。
这些系统通过思科的Intersight云平台进行管理。
与此同时,思科还公布了AI POD。此POD扩展了思科另一套经过长期验证(这套设计方案发布已有20多年)的方案成果,用于为AI推理工作负载提供预配置的基础设施堆栈,能够从边缘部署扩展至大规模集群以实现检索增强生成(RAG)。
AI POD同样在很大程度上依托于英伟达技术,包括其GPU及AI Enterprise软件平台与HPC-X工具包,此外辅以思科自家的UCS X系列模块化设计、机箱、M7计算节点、带有英伟达GPU的PCI-Express节点、思科UCS结构互连以及Intersight管理软件。
其中还囊括了红帽OpenShift应用平台,并允许用户根据需求在Nutanix、NetAPp的FlexPod或者Pure Storage的FlashStack等方案间灵活做出选择。
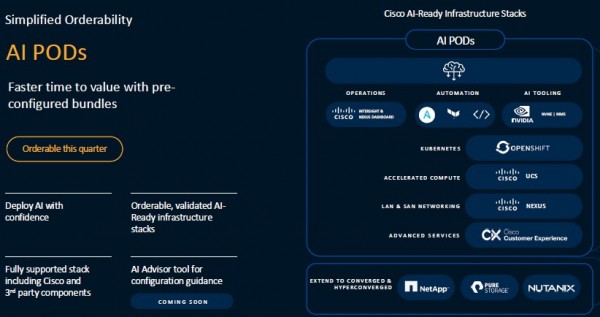
思科的McGinnis表示,这样的技术堆栈对于仍在努力理解AI所需复杂基础设施环境的组织来说,无疑是大有裨益。
他解释道,“几十年来,人们一直在努力构建虚拟化环境。刚开始大家对此也不熟悉。而现在的生成式AI浪潮又带来了类似的问题,可以说是历史的重演。整体堆栈的概念确实能让客户感到安心,缓解他们对于未知的焦虑和恐惧。比如他们并不清楚要如何确定环境规模,也不了解该如何搭配CPU、内存、驱动器和GPU组合。这是个需要认真考虑的全新方向。而我们则为他们确定了设施规模,在必要时整个堆栈都将随时听候调遣。而随着他们更好地了解自己的需求和环境,客户可以进一步做出定制和调整。但作为启动的第一步,整体解决方案这个概念往往非常重要。”
UCS C885A M8服务器(现已开放订购,并将于今年年底发货)和AI POD(11月内开放订购)正是思科不断增长的AI基础设施产品家族中的最新成员,其他成员还包括运行在思科Silicon One G200芯片上的800G Nexus交换平台,以及与英伟达合作开发并于今年6月推出的Nexus HyperFabric AI集群——其将思科AI网络同英伟达的加速计算和AI Enterprise软件,连同VAST数据存储全面融合了起来。
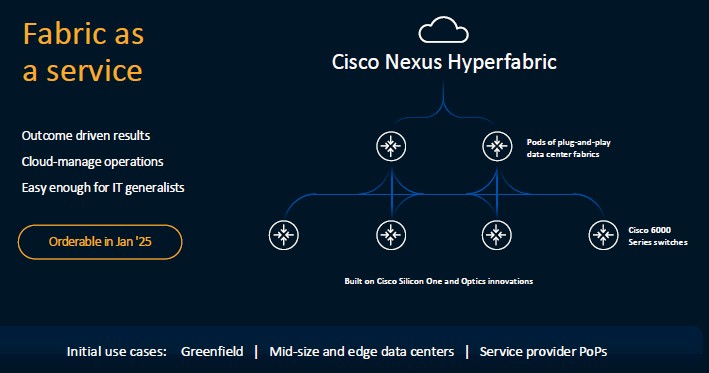
思科的Foster表示,Nexus HyperFabric AI集群将于明年开始开放订购,希望能帮助更多企业快速建立起业务需要的AI网络。
Foster总结道,“如果大家打算训练两套网络,那就得区分前端网络和后端网络。现在我们将其合并成统一的以太网网络,允许客户将管理能力从网络一直延伸到服务器上的网络接口卡,而后配合Intersight保持服务器环境的正常运行,再根据客户的用例需求进行整体环境优化。”
好文章,需要你的鼓励


AI对就业的影响:大规模裁员背后的真相与数据
近期数据显示,2026年5月前企业已宣布约9万个与AI相关的裁员岗位,部分预测称未来五年美国15%的工作将被AI取代。然而,Ramp与Revelio Labs追踪近2.2万家企业的最新报告显示:重度投入AI的企业反而实现了更快的人员增长,包括初级岗位在内的各职能人数均有上升。但这一数据主要来自技术型企业,能否普遍适用仍存疑。报告同时指出,资源匮乏的企业可能在AI浪潮中持续落后。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。

AI重复申请问题推动电网转向“承诺优先“规划
AI数据中心开发商向多家电力公司同时提交大负荷接入申请以确定选址,导致区域需求预测虚高、电网投资失衡。美国联邦能源监管委员会(FERC)及ERCOT、PJM、SPP等机构正推动"承诺优先"规划机制,要求项目具备实质性商业承诺方可纳入长期传输规划。谷歌、亚马逊、微软、OpenAI等科技巨头支持建立标准化的项目成熟度评估体系,但各方在具体机制上仍存分歧。发电建设问题尚未被纳入联邦传输改革议程。

谷歌研究院打造“论文助手工具“,AI审稿时代正在悄然开启
谷歌研究院开发的论文助手工具PAT,利用分阶段深度推理流水线自动审查学术论文,在真实错误检测任务上达到89.7%召回率,并已在STOC和ICML两大顶会完成超4700篇论文的真实部署。
2024
11/12
10:09
分享
点赞

AI重复申请问题推动电网转向"承诺优先"规划
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
8090 Solutions完成1.35亿美元融资,加速AI软件开发自动化布局
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
Tidal宣布将为AI生成音乐添加标签并移除欺诈内容
Claude Tag:将职场AI从个人助手升级为团队协作伙伴
数百万颗超新星爆炸或将揭开暗能量的秘密
Base44发布自研大语言模型,氛围编程平台寻求核心竞争壁垒
遗留系统与数据鸿沟制约亚洲财资中心发展
机器人手部公司与特斯拉达成商业秘密诉讼和解,完成1100万美元融资
