
极智芯 | 解读NVIDIA B100 B200 以及两个"留了一手"
NVIDIA GTC 2024 大会已经于 2024 年 3 月 18 日至 21 日举行,今年的 GTC 大会的焦点毫无疑问就是新一代 GPU 架构 Blackwell 以及搭载新一代 GPU 架构的产品 B100、B200 以及 GB200 等。这里先来解读一下 B100 和 B200。
老黄整个的介绍下来,可能你会发现英伟达是在弱化 PCIe 板卡的概念,并在向 SXM 架构收敛。介绍一下 SXM,SXM 架构是一种高带宽插座式解决方案,用于将 NVIDIA Tensor Core 加速器连接到其专有的 DGX 和 HGX 系统。而 SXM 架构其实并不算 "新鲜玩意",在 NVIDIA 的每一代企业级计算产品中都是有 SXM 形态的,比如 P100、V100、A100、H100。SXM 相比于 PCIe 的优势在哪里呢,一个在带宽互联、一个在体型体态。PCIe 的带宽通常较低,虽然可以通过 NVLInk 桥接达到和 SXM 相同的带宽,但仍然会受到 PCIe 总线的限制,而且 SXM 在多 GPU 互联方面也具有优势,而这些优势在大模型时代尤其重要。另外由于 SXM 没有板卡外壳,不依赖于 PCIe 卡槽,同样密度的机箱能够插更多的计算卡,能够提升计算卡的布置密度。所以在大模型 AI 计算中心构建方面,SXM 架构形态的优势明显。下面的是 H100 SXM 的产品图。

回到 Blackwell,B100 其实可以直接参考英伟达的传统,比如看作是 A100、H100 的延伸,是其系列的下一代。但是英伟达似乎这次是直接越过了 B100,重心是在推 B200。那么 B200 又是什么呢,这个可以原地参考之前的 H200,关于 H200,可以翻翻我之前的对于 H200 的解读内容《极智芯 | 不要神乎其神 来看全球最强芯H200的提升到底在哪里》。其实简单理解就是两颗 B100 die Chiplet 了一下,形成了 die-to-die 的架构,关于 Chiplet 的解读,可以翻下我的这篇内容《极智芯 | 先进封装技术Chiplet》。当然,B200 相对于 B100 和 H200 相对于 H100 又不太一样,之前的 H200 相对于 H100,其提升点主要是在显存方面,但是 B200 相对于 B100 的提升则是全方位的。为了说明这一点,我整理了 H100、H200、B100、B200 的主要性能参数对比。
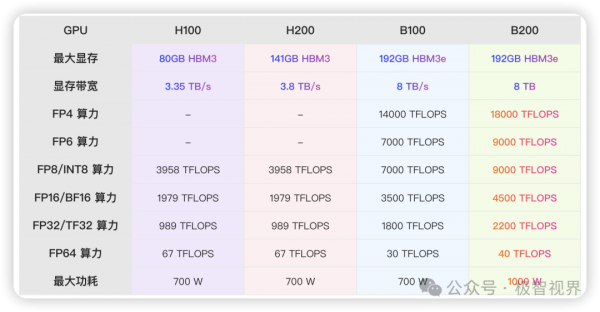
来分析一下,H200 相对于 H100,显存提升到了 141 GB,而这里的 B100 和 B200 在显存容量方面进一步提升,已经来到 192GB (这个 192GB 是不是稍微有些熟悉,苹果 M2 Ultra 最大也是支持 192GB 的统一内存),当然这种提升会是直接来自 HBM3 -> HBM3e 带来的提升受益。你可能还会发现,B200 其实相对于 B100 在显存方面是一致的,包括显存容量和显存带宽。这里就需要好好解释一下了,H200 相对于 H100 的显存提升主要是因为堆叠了更多颗的 HBM3,而 B100 相对于 H100 或者说 B200 相对于 H200 的提升主要受益于 HBM 本身的提升,而 B200 和 B100 的显存情况一致是因为 B200 和 B100 都是 HBM3e,而且颗数也一样。这样应该解释清楚了。除了显存,另外很重要的点在算力,Blackwell 架构新增加了 FP4 和 FP6 精度,这可以认为是之前 FP8 精度的更低版,所以 FP4 相对于 FP8、FP8 相对于 FP16 算力之间会有倍数的差别。在算力方面,B200 相对于 B100 对比 H200 相对于 H100 就不一样了,B200 相对于 B100 在算力方面可谓全面提升,但是并不是理想状态下 two-die 呈倍数的提升,这里其实你也可以认为英伟达给自己 "留了一手"。
好文章,需要你的鼓励

英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。

