
极智芯 | 解读NVIDIA新一代Blackwell GPU架构 正式迈向MCM

先来看这篇内容《极智芯 | GPU架构与计算能力》里提到的 NVIDIA GPU 架构的发展趋势,
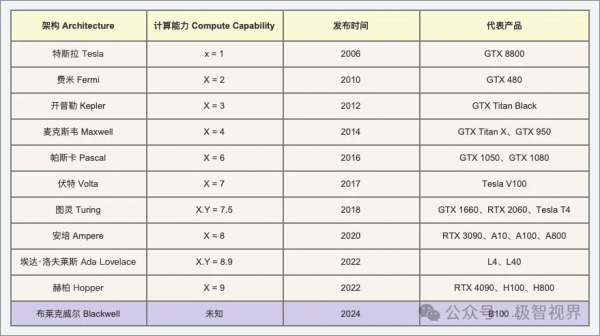
上图表中最下面紫色的 Blackwell 就是这次 NVIDIA GTC 发布的新一代的 GPU 架构,也就是 B100、B200、GB200 所搭载的 GPU 架构,包括未来的 RTX50 系列将会要搭载的 GPU 架构,也是 Hopper 架构的下一代。前面说到 Blackwell GPU 和 Hopper GPU 很不一样,Hopper 及其之前的 NVIDIA GPU 都是单 die 的,但是 Blackwell GPU 是 MCM 的,也就是两颗 B100 Chiplet 了一下。这种架构设计一旦踏足可能就会一发不可收拾,想象一下下一代的 GPU 是不是可能 4 颗 die Chiplet 一下、8 颗 die Chiplet 一下 .... 这不得玩坏了。当然,从设计单的大芯片转向设计小芯片,对于更低制程的良率提升肯定是有帮助的,这有利于切到下一代的 3nm 制程工艺。
回到 Blackwell,作为新一代的 GPU 架构,自然会有很多 "领先" 的地方,下面的图就汇集了 Blackwell 架构的六大优势,下面展开。

-
世界上最强大的芯片 => Blackwell 架构集成了 2080 亿个晶体管,采用 4NP TSMC 工艺 (这里其实并没有上之前谣传的 3nm 制程工艺),两颗单个统一的 GPU 通过 chip-to-chip 10 TB/s 的方式连接成整体,因为带宽特别高,所以用户基本会无感,可以直接看成一块统一的 GPU;==> "最强大" 说的很霸道了;
-
第二代 Transformer 引擎 => 提供新的 micro-tensor 缩放支持,对于 TensorRT-LLM 和 NeMo Megatron 框架的支持更好,新支持双倍效率的 4 位低精度浮点推理;==> 你其实只要无条件的相信未来几年里新的 AI 芯片架构、新的 AI 芯片的发布都是为了更好适配、加速基于 Transformer 的大模型的训练 + 推理就行了,当然,这里的 Blackwell 也不会例外;
-
第五代 NVLink => 最新一代的 NVLink 为每个 GPU 提供了突破性的 1.8 TB/s 双向带宽,能够确保多达 576 个 GPU 之间的无缝高速互联;==> 也还是为了更好适应大模型时代,更加高的带宽无疑利好大模型的训练+推理,以及利好大算力中心的构建;
-
RAS 引擎 => 主要是上面三个,下面三个不多说了;
-
安全的 AI => 同上;
-
解压缩引擎 => 同上;
其实主要是三点,一个是本身的算力提升,第二个是低精度的推出更好适配 Transformer,第三个是互联带宽的提升。其中互联带宽的提升是特别重要的,这点是进一步拉近 GPU 冯诺依曼架构和存算一体芯片访存密集型计算效率的重要方式了,试想一下,我只要拷贝的足够快,我是不是可以像近存计算或者存算一体那样很自然的取、放数据了。下面两张图很好展示了高速互联的重要性。

与 Hopper 相比,NVIDIA Blackwell GPU 提供了 1280 亿个以上的晶体管 + 5 倍的 AI 性能 + 4 倍的显存。说到显存,Blackwell 架构 GPU 堆了 8 个 HBM3e 堆栈,通过 8192 位总线接口提供 8 TB/s 的显存带宽和高达 192 GB 的 HBM3e 显存。与 Hopper 相比,具体的性能提升如下:
-
20 PFLOPS FP8 (2.5x Hopper)
-
20 PFLOPS FP6 (2.5x Hopper)
-
40 PFLOPS FP4 (5.0x Hopper)
-
740B Parameters (6.0x Hopper)
-
34T Parameters/sec (5.0x Hopper)
-
7.2 TB/s NVLINK (4.0x Hopper)
另外还有一些重要参数汇总如下:
-
TMSC 4NP Process Node
-
Multi-Chip-Package GPU
-
1-GPU 104 Billion Transistors
-
2-GPU 208 Billion Transistors
-
160 SMs (20,480 Cores)
-
8 HBM Packages
-
192 GB HBM3e Memory
-
8 TB/s Memory Bandwidth
-
8192-bit Memory Bus Interface
-
8-Hi Stack HBM3e
-
PCIe 6.0 Support
-
700W TDP (Peak)
最后附一张 David Harold Blackwell 老爷子的图。

好了,以上分享了 解读NVIDIA新一代Blackwell GPU架构 正式迈向MCM,希望我的分享能对你的学习有一点帮助。
来源:极智视界
好文章,需要你的鼓励



牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

美国多源电子患者数据采集方法研究综述
随着医疗数据数字化与互操作性的进步,跨机构纵向患者数据的研究应用成为可能。本研究通过对20位领域专家的访谈,识别出8种数据收集方法,涵盖智能手机应用、结构化数据导出、区域/全国研究查询及聚合数据源等。研究发现,各方法均有其优缺点,无单一最优方案。参与者中介交换方式可绕过复杂治理安排,但存在数据缺口;全国性网络尚不支持研究查询。公共政策的持续推进将对该领域发展起关键作用。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。

