
为提升GPU性能,英伟达选择对HOPPER HBM内存扩容

出于一系列技术和经济因素的考量,过去几十年来各类处理器往往存在算力过剩、内存容量/带宽不足的问题。有时候,甚至会特意针对设备和工作负载规划内存容量。
Web基础设施工作负载和相对简单的分析/数据库工作负载倒确实能在拥有十几条DDR内存通道的现代CPU上运行良好,但对于强度更大的HPC模拟/建模以及AI训练和推理用例,即使是最先进GPU上的内存带宽和容量也都有点招架不住。换言之,提高这两项指标有望改善芯片上现有向量与矩阵引擎的利用率,避免GPU把大量时间浪费在等待数据身上。
于是答案就很明显了:应该在芯片上塞进更多内存!但遗憾的是,高级计算引擎上HBM内存的成本往往比芯片本身还高,所以扩容工作面临很大阻力。特别是如果添加内存就能让性能翻倍,那同样的HPC或AI应用性能将只需要一半的设备即可达成,这样的主意显然没法在董事会那边得到支持。这种主动压缩利润的思路,恐怕只能在市场供过于求,三、四家厂商争夺客户预算的时候才会发生。但很明显,现状并非如此。
好在理性还是最终占据了上风,所以英特尔才为“Sapphire Rapids”至强SP芯片家族推出了新的变体,配备64 GB的HBM2e内存,虽然每核内存容量刚刚超过1 GB,但综合内存带宽却一举达到1 TB/秒以上。对于那些内存占用量相对不大,而且性能表现主要受到带宽影响、而非容量制约的工作负载(也就是大部分HPC应用),只需转向HBM2e就能瞬间将性能提升1.8到1.9倍。这也让Sapphire Rapids的HBM版本成为今年1月产品发布会上最有趣、也最具现实意义的内容之一。由此看来,英特尔后续也很有可能在主打MCR DDR5内存的Granite Rapids架构中推出相应的HBM变体。
英伟达在本周于丹佛召开的SC23超级计算大会上,宣布推出新的“Hopper”H200 GPU加速器。另一方面,AMD也将在12月6日推出面向数据中心的“Antares”GPU加速器家族,包括带有192 GB HBM3内存的Instinct MI300X和带有128 GB HBM3内存的CPU-GPU混合MI300A。看起来英伟达必须有所行动,至少得想办法给Hopper GPU加上更大的内存。
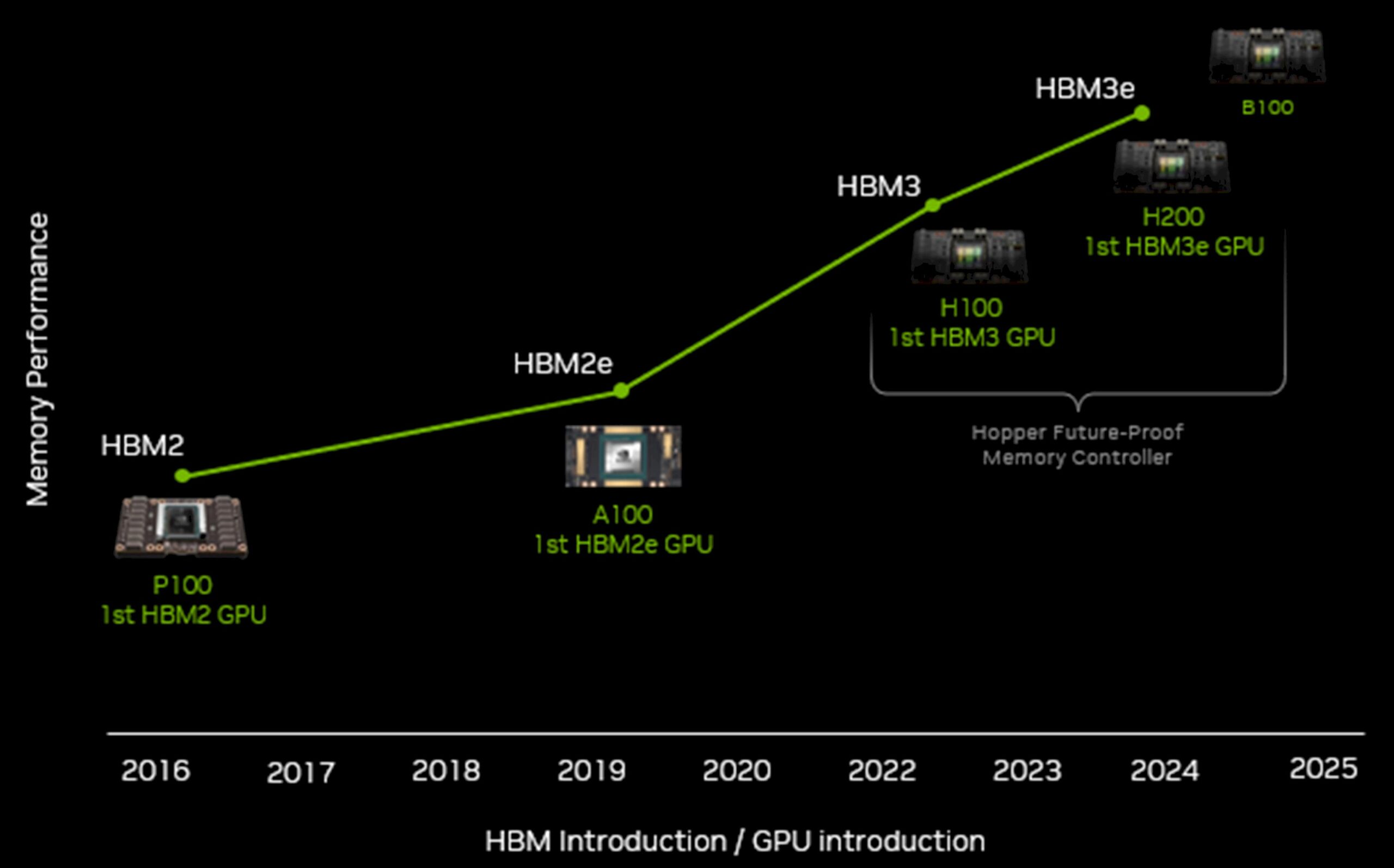
一个月前,在英伟达通过财务会议放出的技术路线图中,可以看到GH200 GPU和H200 GPU加速器将作为“Blackwell”GB100 GPU和B100 GPU之前的过渡产品,而Blackwell家族计划在明年年内推出。大家普遍认为H200套件将拥有更大的内存容量,但当时我们认为英伟达应该花时间提升GPU本身的性能。如今事实证明,通过添加更大的HBM内存和转向速度更快的HBM3e内存,英伟达完全可以在不改动现有Hopper GPU设计的前提下(即不添加更多CUDA核心或者做GPU超频)实现显著的性能提升。
但由此看来,原本这些计算引擎的设计还远称不上平衡。批评者可能认为计算引擎厂商一早就清楚问题的症结所在,只是在故意戏耍消费者。比较中肯的用户则认为考虑到HBM内存的高昂成本,这些情况也都可以理解。我们的观点居于两者之间,毕竟按照目前英伟达GPU的市场售价,塞进几百GB的最快内存也完全没有问题。更进一步讲,哪怕再引入3D V-Cache和HBM加DDR内存都不会让产品无利可图。
如果真是如此,那过去一年间花大价钱采购Hopper H100加速器的用户恐怕要骂娘了。为了防止这种情况的出现,英伟达恐怕将把141 GB HBM3e内存版本的Hopper价格定为80 GB或96 GB HBM3版产品的1.5到2倍,以此安抚客户们的暴躁情绪。

据我们了解,H200目前还只适用于SXM5插槽,而且在向量和矩阵数学方面的峰值性能也跟2022年3月公布、去年投放市场且直到今年初才大规模出货的H100加速器完全相同。二者唯一的区别在于,H100配备的是80 GB和96 GB的HBM3内存,初始设备分别提供3.35 TB/秒和3.9 TB/秒的内存带宽;而H200则搭载141 GB且速度更快的HBM3e内存,总带宽为4.8 TB/秒。与前代Hopper相比,H200内存容量增加到1.76倍,内存带宽则为1.43倍,且运行功率继续维持在700瓦不变。相比之下,AMD的Antares MI300X将提供182 GB的HBM3容量和5.2 TB/秒内存带宽,而且峰值浮点算力更高(也可能只是有效浮点算力更高)。
如今已经是摩尔定律末期,所以看到计算引擎的性能还在因HBM内存的高成本而受限着实令人震惊。但从英伟达和英特尔Sapphire Rapids至强Max CPU公布的相关数据,情况就是如此。
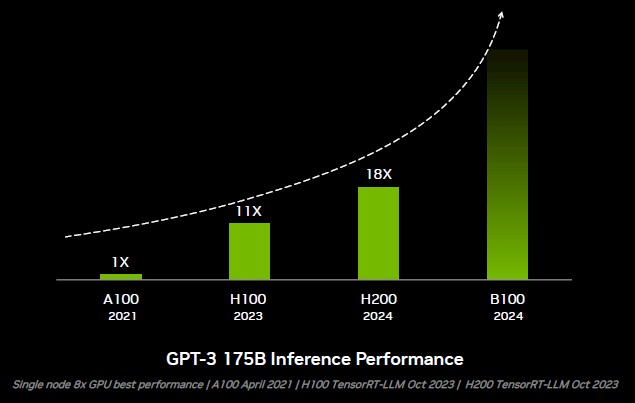
无论下一代Blackwell B100 GPU加速器将如何设计,相信其推理性能都将有所提升,而且我们强烈怀疑这种提升主要来自内存方面的扩容、而非计算架构有何突破。下图所示,为各代GPU在GPT-3 175B参数模型上的推理性能变化曲线:
就是说从现在到明年夏季,所有花钱采购英伟达Hopper G200的客户都将毫无性价比可言(但快速发展也是数据中心硬件技术的常态)。
得益于Transformer引擎、浮点运算精度的下降和速度更快的HBM3内存,今年开始全面出货的H100在GPT-3 175B模型的推理性能方面提升到了11倍。而凭借更大、更快的HBM3e内存,H200无需硬件和代码变更,就直接将性能提高到了A100的18倍。从H100到H200,性能增幅为1.64倍,而且所有这一切都是单纯通过内存容量和带宽提升实现的。
设想一下,如果在设备上添加512 GB HBM3内存和10 TB/秒的带宽,结果又会如何?大家愿意为这样的完全体GPU付多少钱?考虑到目前“残次”版本、根本无法发挥全部算力的GPU也要3万美元左右,估计英伟达很可能会报出6万、甚至9万美元的恐怖数字。
请注意:我们在这里并不是在专门针对英伟达,毕竟我们去年也曾抱怨过英特尔和AMD的“Genoa”Epyc CPU应该在部分型号上搭载HBM内存,这完全是中立的评论和建议。毕竟对于大多数HPC和AI工作负载来说,内存容量和内存带宽已经成为决定实际性能、提升浮点算力的最大瓶颈。所以摆在计算引擎厂商面前的只有两条路:要么用更多核心来填平内存结构的短板,要么至少选择更大、更快的内存容量。英特尔和英伟达谁能拿出更好的结果,客户们将会心甘情愿用钱投票。
另外补充一点:也许HBM内存厂商也该想点办法降低堆叠内存的成本,同时加快推进HBM技术路线图。毕竟这个大麻烦已经成为计算行业资金浪费和效率低下问题的根源。此外,相较于每年发布新的制程工艺,计算引擎厂商也可以考虑出台更激进的HBM升级方案,真正把计算和内存协同起来。换句话说:H100也应该推出HBM3e版本,这显然是发掘其硬件潜力的唯一方法。
下面,我们通过一组AI推理工作负载对H100和H200的相对性能做出了比较:
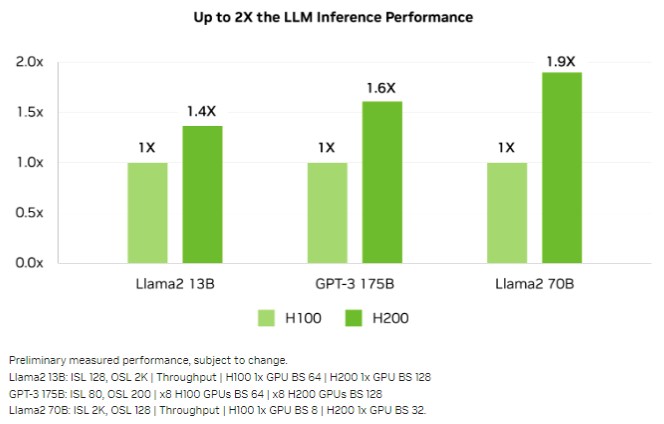
可以看到,更大、更快的内存带来的实际性能提升要视工作负载而定,而且效果并不稳定。如图所示,体量较小的Llama2 13 B模型的性能增幅不及Llama 70B模型,这是因为70B模型在接收提示词并生成token时所需处理的参数量高达13B模型的5.4倍。
很明显,如果能在相同的功率区间内实现性能倍增,就相当于把能耗和总体拥有成本降低了50%。所以从理论上讲,英伟达完全可以把H200 GPU的售价维持在与H100相同的水平上。
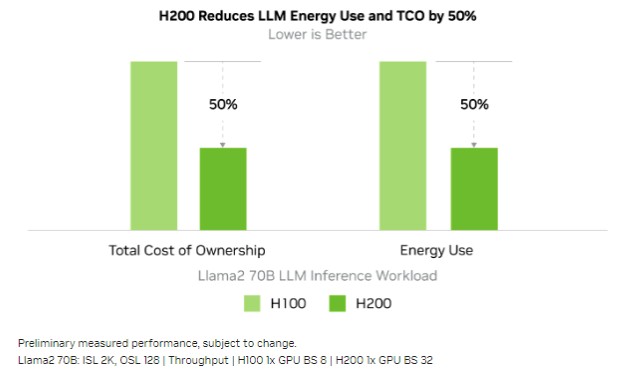
通过这幅典型的营销宣传图,我们可以断言如果英伟达真的让H200的售价与当初的H100持平,绝对会瞬间引爆市场。
对HPC从业者来说,X86 CPU与GPU之间的性能比较早已司空见惯。下图所示,为两块Sapphire Rapids至强SP-8480和4个H200 GPU在运行MILC晶格量子色动力学负载时的性能比较。由于GPU的数量是CUP的2倍,所以单设备性能增幅实际只有55倍。
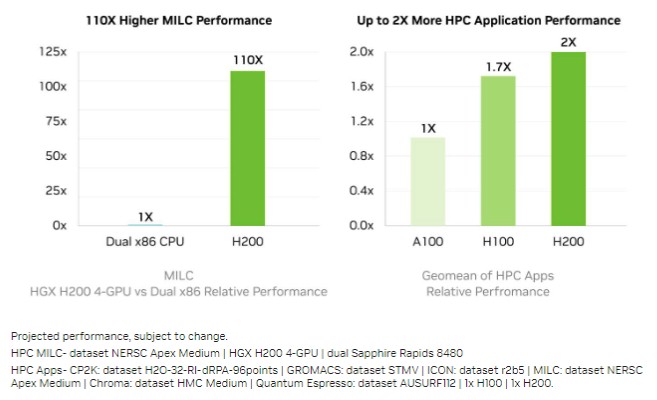
上图右侧则是A100、H100和H200在由六种不同HPC负载组成的混合测试中的性能表现。可以看到,更大的内存容量和带宽虽然仍有提升作用,但效果不如AI推理工作负载来得明显。这六种工作负载(CP2K、GROMACS、ICON、MILC、Chroma和Quantum Espresso)在H100到H200的性能差异仅有18%,无疑令人失望。这似乎也解释了为什么GPU计算引擎厂商没有一开始就疯狂扩大HBM内存容量。
但这样的结果也有其他解读方式,即HPC应用开发者很可能习惯于在给定的计算量下以较小的内存占用量做程序设计,因此工作负载本身以及中间件(例如出色的MPI协议)都更善于节约内存资源。相比之下,AI工作负载网络上存在着巨量数据流,总会有某组GPU需要闲置一段时间来保证数据的同步处理和交换。
不过从好的方面看,只要硬件设备拥有更大的HBM内存和传输带宽,相信HPC社群也会像无数AI从业者那样做出针对性调整。毕竟无论是才智还是技术能力,HPC社区都完全不逊于AI阵营。
最后要说的是,H200 GPU加速器和Grace-Hopper超级芯片都将搭载更新的Hopper GPU,拥有更大、更快的内存,且计划在明年年中正式上市。由此看来,我们可能需要修订英伟达的技术路线图,即Blackwell B100将在明年3月的GTC 2024大会上首次公布,并到2024年年底才投放市场。当然,无论大家更看好哪款产品,最好现在就提交订单,毕竟英伟达的全线产品如今都是一卡难求。
好文章,需要你的鼓励


开创电气越南基地形成80万台手持式电动工具年产能力
今天讲的出海案例是开创电气,一家金华手持式电动工具制造商,在越南基地完成首款产品验收并形成80万台年产能力。

当AI学徒“失控发疯“:中国科学院自动化研究所揭示强化学习崩溃真相,并找到了解决之道
本文介绍了中国科学院自动化所的研究,揭示了大型语言模型在多轮工具调用强化学习中崩溃的根本原因,并系统评估了五种监督信号对训练稳定性和泛化能力的影响。

一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

牛津、MIT等顶尖机构联手揭露:当前最强AI智能体,在这些任务上表现堪比新手
牛津、MIT等机构联合发布GauntletBench,测试显示最强AI智能体完成率仅19%,而普通人类完成率超80%,揭示AI在时间感知、图形理解和三维推理上的真实短板。

