
只要加快脚步,蓝色巨人仍有望追赶AI浪潮

过去这25年来,我们先后两次见证了全新计算领域的快速扩张,如今的新一波驱动力自然就是风头一时无两的生成式AI。而25年之前,随着互联网的繁荣发展,企业开始在应用程序外头包上一层又一层的网络和Web协议,让更多人成为键盘鼠标的奴隶,也为如今仍在运行的超大规模互联网数据挖掘体系奠定了基础。
用户的鼠标点击转化成了企业的广告收益。而随着生成式AI革命,我们在网络上创建的所有文本、以及从私人数据集和公共领域资料中提取的一切文本,都经过了尽可能全面的清洗和筛选。去掉偏见之后,这些素材建立起一个包含数万亿参数的神经网络,其凭借庞大语料库中过场的文本片段成为一套极为高效的问答系统。这类生成模型已经被用于输出图像、视频和声音,世界各地的企业、政府、学界及研究机构都想搞清楚如何将其融入自身应用当中,或者借此开发出新的应用。与此同时,各方还在努力使用GPU来训练和运行这类模型,并拼命争取能支撑起这类大规模并行计算引擎的高昂预算。
这场以机器学习为基础的AI革命始于10年之前的2012年,当时技术第一次在图像处理方面追平了人类专家。在这场机器学习革命当中,IBM一直致力于开发TrueNorth系列神经形态处理器以及面向AI应用的补充性模拟芯片,并将更为传统的矩阵数学引擎以离散组件的形式嵌入在其Power和Z系列产品当中。但除了Power 10和z16处理器中两种差异巨大的矩阵单元之外,IBM的努力并没能在商业市场上取得广泛成功。毕竟蓝色巨人曾经对此充满热情、也慷慨投入,如今居然在供应严重不足的AI训练和推理引擎领域毫无作用,实在让人有点想不通。
就在上个月底,IBM位于加利福尼亚州阿尔马登的研究实验室(主要负责AI、量子计算、安全及存储类项目)公布了基于TrueNorth架构的NorthPole启动器,此架构已经在《科学》及IBM研究院的博文中正式公布。不过作为IBM研究院院士、类脑计算首席科学家Dharmendra Modha毕生工作的巅峰,NorthPole目前对外公开的技术细节并不多,这着实令人感到遗憾。

IBM的NorthPoe AI推理处理器,这块PCI-Express卡上其他芯片的作用尚不明确。
IBM公司早在2015年就已经为TrueNorth芯片申请了设计专利,并在2017年通过IEEE发表的论文中进行了更全面的披露。与其他神经形态芯片一样,TrueNorth芯片实际是受到人脑神经元结构的启发,属于软硬件相结合的神经网络,能够进行大量向量与矩阵数学计算。在SyNAPSE计划之下,IBM从美国国防研究计划局(DARPA)获得了1.5亿美元资金,用于制造这些神经形态芯片。而且根据军方的要求,TrueNorth和NorthPole芯片主要用于图像及视频识别类任务。
TrueNorth核心实现了通过突触交叉网络互连的256个神经元与256个轴突,而且总计4096个此类核心(每个核心都拥有本地内存)被共同安置在制程未知(可能是22纳米,也可能是32纳米)的单一芯片之上,总计用58亿个晶体管模拟2.68亿个神经元。作为DARPA项目的一部分,IBM还将16个TrueNorth芯片连接起来,并于2018年开始使用这套芯片网络处理立体视觉。
根据IBM的介绍,NorthPole属于TrueNorth架构的扩展成果。其不同之处,在于NorthPole的时钟速率与传统计算引擎更为相似。它的时钟速率可以扩展,运行主频在25 MHz到425 MHz之间,具体取决于工作负载,并采用12纳米制程工艺。(这听起来似乎符合Global Foundries的代工能力,但考虑到IBM与Global Foundries曾在两代Power和z芯片合作上都闹出过矛盾,所以这种可能性已经是微乎其微。)
根据发表在《科学》上的论文,NorthPole芯片没有集中式内存,而是为芯片的256个核心分配了总计224 MB的SRAM(每个核心768 KB)。看起来NorthPole的核心更为强大,所以每芯片只部署了16 x 16个核心(总共256核),而非TrueNorth的64 x 64核心阵列(总计4096核)。
据我们所知,NorthPole核心能够实现直接向量与矩阵数学指令(分为8位、4位和2位格式),且没有对核心中的突触和轴突、或者横杆间的树突进行模拟。由此看来,它似乎不能说完全受到TrueNorth架构的启发。在我们看来,其灵感更多来自Graphcore、SambaNova以及Cerebras Systems……
NorthPole芯片上共有220亿个晶体管,展开总面积为800平方毫米,在8位分辨率下每个核心每周期可处理2048次操作,而4位条件下每核心每个周期可以处理4096次操作,2位条件下每核心每周期则为8192次操作。
NorthPole芯片上设有两个不同网络,IBM表示其灵感来自人脑中的长距离白质与短距离灰质网络(分别对应两套不同的皮层感知与运动系统网络)。短距离片上网络(NoC)允许在相邻核心之间进行空间计算,长距离网络则允许神经网络激活分布在整个网络内的其他核心。
NorthPole核心的16 x 16阵列前端是一组16个帧缓冲区,总容量为32 MB,而且这些帧缓冲区(大小与NorthPole的一个核心基本相当)依次按照I/O、队列和调度电路排列。对于待处理的图像,其内容会被分成16块并分别送入16个帧缓冲区。
这就是NorthPole的巧妙之处:它并不属于冯·诺依曼架构。来看论文表述,“NorthPole在数据之外建立分支,借此支持管线、无停顿且确定性的控制操作,从而大大提高时间利用率,且不会像冯·诺依曼架构那样发生内存丢失。由于不存在内存未命情况,因此不需要执行推测性、不确定性操作。纯确定性操作使得一组八线程能够在构造上保持同步,并以极高效率执行各类计算、内存与通信操作。”
IBM表示,在ResNet-50图像识别测试及YOLOv4物体检测测试当中,NorthPole的速度可达到TrueNorth的约4000倍。
由于NorthPole架构中的数据移动量不大,至少与CPU及GPU等冯·诺依曼设备及外部主存储器相比不大,所以IBM表示NorthPole的每单位芯片面积上的能源效率更高。这也是芯片设计师及超大规模芯片厂商都在关注的重要评分指标。
英伟达“Volta”V100采用类似的台积电12纳米制程工艺,晶体管数量为211亿个,芯片尺寸为812平方毫米,但NorthPole设备每焦耳能量所处理的图像数量达到V100的25倍。即使是面对采用台积电4纳米制程、包含800亿个晶体管的英伟达“Hopper”H100 GPU,NorthPole每焦耳能量所处理的图像数量仍可达到其5倍。
下面来看各种计算引擎在 ResNet-50图像识别效果、NorthPole帧数/焦耳处理比例以及每十亿个晶体管的每秒帧数据密度结果间的比较:
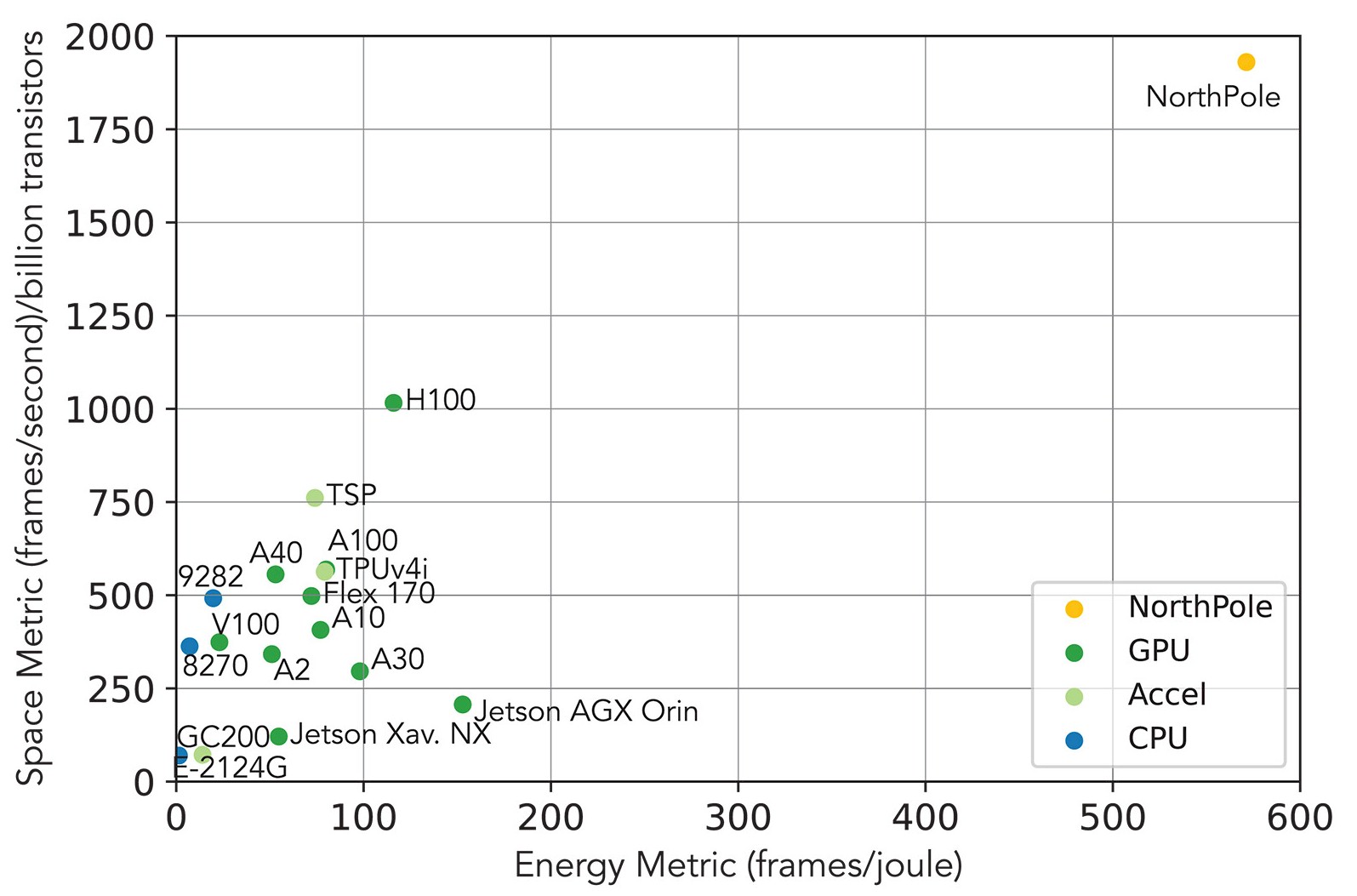
IBM方面已经明确表示,NorthPole还只是一套概念验证方案,并尝试在谷歌用于自然语言处理的BERT纯编码器大语言模型及Deep Speech 2语音识别模型上进行了推理测试。目前NorthPole还未尝试在纯解码器大语言模型(例如OpenAI的GPT-4或Meta Platforms的Llama 2)上进行推理测试,但Modha表示研究院正在着手筹备。
相信只要加快脚本,蓝色巨人仍有望追赶这波AI浪潮。毕竟生成式AI推理的成本太高,如果能够调整NorthPole以支持生成式AI模型,或者调整模型来支持NorthPole以实现多设备扩展,那么IBM也将入围这场AI推理军备竞赛……或者至少能够在AI推理领域,提供比Power 10和z16处理器上的矩阵数学单元更加强大的新方案。
我们认为IBM的目标并不是成为专利流氓,毕竟其研究工作一直在切实推进、也打造出了TrueNorth及NorthPole等芯片成果。但从目前的情况看,IBM给予的重视程度似乎还不够,没有做好成为AI计算引擎供应商的准备,至少还没想过要在价值数百万美元的AI市场上跟其他GPU和ASIC厂商正面对抗。
当然,这种情况随时可能改变,也应该有所改变。加油IBM,拿出点真功夫给这帮小年轻瞧瞧!
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2023
11/07
15:38
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
