
美国能源部百亿亿次超级计算机初探

除了HPE之外,还有谁愿意帮劳伦斯伯克利国家实验室打造下一代NERSC-10超级计算机,还有橡树岭国家实验室的未来OLCF-6超算系统?好的,微软举手了,还有亚马逊云科技。收到,还有没有其他感兴趣的?
没错,现在情况大概就是这样。
劳伦斯伯克利国家实验室已经于9月15日就当前Perlmutter系统提出了技术升级邀约,橡树岭国家实验室也紧随其后,于9月27日就Frontier系统开放了技术升级招标。面对两项需求,我们不禁好奇,美国能源部下属的这些国家实验室在采购下一代超级计算机时,具体有哪些选项可以考量?
英特尔已经不愿承包超级计算机业务,公司CEO Pat Gelsinger也清醒过来,不再讨论在2027年之前实现Zettascale(即1000百亿亿次)算力的计划。两年之前,Gelsinger曾经对此信誓旦旦,但我们在计算之后发现,哪怕英特尔在2021年至2027年间每年都能把CPU和GPU性能提高一倍,也仍然需要11.6万个节点加772兆瓦的能耗才能实现Zettascale。问题是这可能吗?明显不可能。
在经历之前大型计算系统项目亏损之后,IBM也退出了这部分承包市场,开始专注冲击以AI推理为核心的HPC工作负载。几年之前,英伟达和Mellanox曾与IBM合作开发过百亿亿次系统,成果如今就坐落在劳伦斯利弗莫尔和橡树岭国家实验室当中。但在此之后,英伟达发现AI训练才是最来钱的道儿,所以不再像2008年到2012年那样关注HPC模拟和建模。时至今日,哪怕英伟达的HPC业务规模再翻一番,小小的数字在如今生成式AI业务的爆发式增长当中,也只能作为可被舍去的小数点后部分。
Atos或者富士通也不可能向美国政府实验室出售产品。戴尔倒是可以,但Michael Dell本人并不喜欢赔钱赚吆喝,所以帮得克萨斯大学搞的高性能计算项目已经足够彰显其爱国情怀,再多投入实无必要。
那市场上还有谁?没错,基本就是三大云巨头——微软、AWS和谷歌了。而根据最近的相关报道,他们也分别有着自己的问题。最大的问题就是这帮云服务商必须拿恐怖的设施规模吸引受众,但客户实际用得上的资源却非常有限。无限容量、易于切换这些东西看似简单,可在公有云端跟在国家级超级计算中心内的实现根本就不是一回事。后者需要把数千万个并发核心连接起来以完成工作,同时辅以高带宽、低延迟的网络互连。与之相比,众多小体量租户各自使用有限资源的公有云业务简直就像过家家。
劳伦斯伯克利国家实验室、特别是旗下的国家能源研究科学计算中心,早在今年4月就要求各供应商提供NERSC-10超算的设计方案。下面来看技术文件中提出的开发路线图:
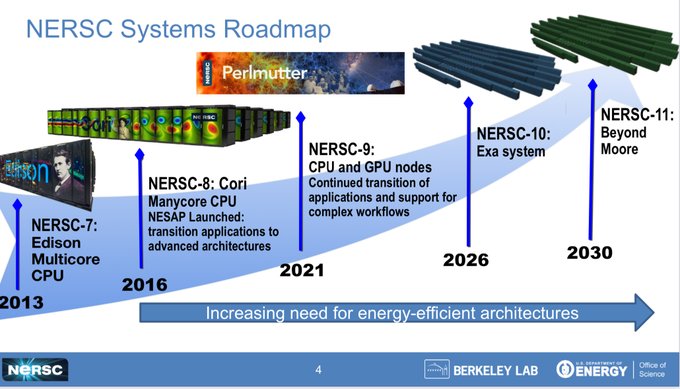
请注意,技术征求意见书跟真正的征求意见书不太一样,前者更多是种预览草案,希望初步定下盈亏基调来吸引更多厂商的参与。NERSC-10的正式征求意见书将于2024年2月5日发布,经过一段时间的质询后最终在3月8日截止。早期访问机器必须在2025年内交付,NERSC-10系统本体则须在2026年下半年交付,系统验收(暨主承包商收款时间)预定在2027年之内。
与之对应,技术征求意见书则像是份长长的特性加功能清单,具体内容并不要求太过精确,因为劳伦斯伯克利实验室也希望能对开放架构、复杂HPC和AI工作流程,以及各因素之间的相互匹配持开放态度。该实验室先进技术小组负责人兼NERSC机器架构师Nick Wright在最近的HPC用户论坛会议上发表演讲,表示HPC技术、行业乃至整个社区都处于发展拐点,而核心影响因素一是摩尔定律的终结、二是AI技术的崛起。
NERSC-10的目标就是在HPC工作负载之上提供至少10倍于当前Perlmutter的性能。劳伦斯伯克利实验室拥有一整套量子色动力学、材料、分子动力学、深度学习、基因组学和宇宙学应用程序,能够准确衡量性能提升是否达到10倍。从其中的表述来看,只要最终大规模并行计算阵列能够提供比CPU-GPU混合架构更好的算力和每瓦性能,那么所有国家实验室都会快速跟进、采购相关设备来构建自己的数据中心。这样的潜在收益,当然会令更多技术大厂为之心动。
四年之前,Hyperion曾表示NERSC-10的峰值性能将在8到12百亿亿次之间,而Frontier的峰值性能预计将在1.5到3百亿亿次之间。至于劳伦斯利弗莫尔的El Capitan,最终成绩约在4到5百亿亿次左右。但NERSC-10的征求意见书不会公布峰值失败率,所以我们无法判断以上预测跟现实有多大出入。Wright还补充称,劳伦斯伯克利实验室也在努力扩大供应商群体,包括那些之前没有就能源部征求意见书做出响应的供应商。
遗憾的是,NERSC-10目前的技术征求意见文件缺乏细节,唯一确定的就是拟议系统最大功耗不可超过20兆瓦,且最大占地面积不可超过4784平方英尺。此外,NERSC也对能源效率非常重视,考虑到狭小空间内极高的发热密度,相关设备必然需要采用水冷(与Perlmutter一样)。
橡树岭国家实验室坐落于伯克利大学正东偏南约2466英里外的田纳西州荒山当中。在这里,OLCF-6系统的技术征求意见书也已出炉,向HPE及其他有意参与的竞争对手提出了挑战。
下图所示为2019年时公布的旧路线图,点明了Frontier及其后续系统的发展方向:
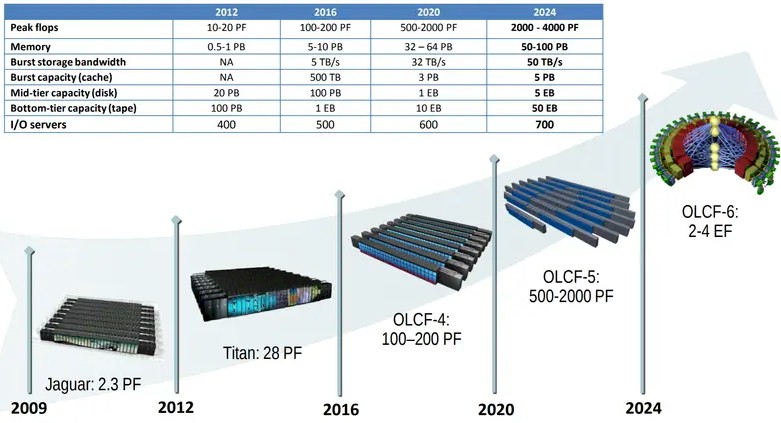
“Summit”OLCF-4机器已经成功达成了性能目标上限,而Frontier OLCF-5机器只能说是几乎接近上限。如果把系统的实际发布时间均取中间值,则OLCF-4和OLCF-5相当于分别在2018年和2022年交付,OLCF-6则预计在2027年。但实际上“Jaguar”系统是在2009年交付的,“Titan”系统则是2012年,所以猜测这里标出的时间其实就是相应超算系统的实际发布时间。
这也不要紧,毕竟每家厂商的HPC路线图都有延后。预计未来十年在摩尔定律走入困境的大背景之下,技术承诺无法实现将成为一种常态。
无论如何,当时的路线图预计OLCF-6的峰值性能应该是在2到4百亿亿次,最乐观的估计就是在4百亿亿次。而根据目前的技术征求意见文件来看,Frontier将于2028年迎来其生命周期终点,就是说在此之前(也就是2027年),OLCF-6必须准备就位。橡树岭实验室愿意接受Frontier升级、全新系统设计以及其他场外系统投标——我们认为,最后一点就是在向超大规模基础设施运营商和云服务商伸出橄榄枝。橡树岭还对并行文件系统和AI优化型存储系统敞开了怀抱(指向的应该是DataDirect Networks和Vast Data)。
对了,顺带一提,如果Frontier的继任者没有部署在田纳西州,则中标方还须缴纳9.75%的销售税。这就是美国东部诺克斯维尔数据中心专区的规矩……
无论后续机型是什么,它都必须匹配橡树岭数据中心4300平方英尺的物理面积,且不可超过30兆瓦的功耗上限。目前还未公布应用性能目标,但OLCF-6基准测试套件中的应用程序列表(包括LAMMPS、M-PSNDS、MILC、QMCPACK、SPATTER、FORGE 和 Workflow)已经涵盖各类HPC模拟和AI训练方面的NERSC-10基准套件。
很难想象,除了HPE之外还有谁会愿意参与这场竞标,但政府项目要求至少要有两家参与竞标的厂商。如果实在没有,可能就得生生“创造”一个。
真正的拐点和由此引发的问题在于,专门设计本地系统的HPE到底能不能在这两笔交易中击败微软或AWS。云服务商必然采用跟传统云业务截然不同的方法——更多类似于托管业务,借此在HPC和AI工作负载上提供更好的性能。而即便如此,恐怕也只有他们才参与竞标的能力、完成工作的资金储备、以及冲击百亿亿次的实力。
唯一的问题就是,他们肯定不会像之前的SGI、IBM、英特尔和HPE那样接受更低的构建成本。这才是真正的难题所在,毕竟如今的AMD已经不会再像Frontier和El Capitan项目那样用CPU和GPU项目从美国政府手中换取特殊利益。美国政府当然可以用免于起诉和允许垄断等特权换取廉价的HPC/AI超级计算机,但至少我们还没听说过如此大胆的交换条件,所以新一代超算的命运仍是个未定之数。
好文章,需要你的鼓励


Glean年收入突破3亿美元,削减AI成本成核心卖点
企业AI搜索公司Glean宣布年度经常性收入(ARR)达3亿美元,较15个月前的1亿美元增长三倍。尽管谷歌、微软、OpenAI等科技巨头纷纷入局企业AI搜索市场,Glean凭借"上下文图谱"技术深度理解企业业务需求,并帮助客户显著降低AI计算成本。该公司提供按用量计费和混合定价两种模式,客户涵盖Databricks、Reddit、Pinterest及三星等企业。Glean上轮融资后估值达72亿美元。

香港中文大学与MiniMax联手破解AI图像描述的“说多错多、说少漏多“困局
香港中文大学与MiniMax提出ClaimDiff-RL框架,将图像描述的AI训练从整体打分升级为逐条核查,有效解决了传统方式导致AI"少说保平安"的问题,同时在多项基准测试上超越Gemini-3-Pro-Preview。

蓝色起源“新格伦“火箭在佛罗里达测试中发生爆炸
杰夫·贝索斯旗下的蓝色起源公司在佛罗里达卡纳维拉尔角进行静态点火测试时,新格伦重型火箭发生爆炸。这是美国历史上最大规模的火箭爆炸之一,也是蓝色起源公司遭遇的最严重失败。所有人员安全,但该事故可能导致新格伦火箭项目长期暂停。此前该火箭已成功完成三次发射,并实现了助推器回收和重复使用。

NTU、HKU等多所顶校联手,让AI同时“多角度看片“——视频理解的并行探针革命
ParaVT是一个由南洋理工等多校联合提出的并行视频工具调用框架,通过让AI同时分析多段视频并引入PARA-GRPO算法解决训练中的格式崩溃与工具跳过问题,在六项长视频理解测试中平均提升约7.9%。
2023
10/03
17:50
分享
点赞

Glean年收入突破3亿美元,削减AI成本成核心卖点
蓝色起源"新格伦"火箭在佛罗里达测试中发生爆炸
智能体AI正在重塑企业架构与Token经济学
堪培拉理工学院如何借助技术革新重塑课堂教学体验
Gemma 4携手Arm:优化端侧AI,加速移动应用体验
制药公司与初创企业如何携手推动AI落地
《星球大战》导演盛赞生成式AI:电影制作的革命性工具
Salesforce借助Informatica布局企业级无头数据管理架构
几乎所有M5 MacBook Air配置现在都降价近200美元
企业用好Agent,关键不在“买一个智能体”|原点Talk 分享会
大模型评测风向变了,Testin云测如何构建企业级AI质量标尺?
因民事养老金管理失误,英国政府拒绝向Capita授予5.63亿英镑合同
