
这个“五一”,用AI来创作你的绘画大作吧
AI绘画是近年来热门的话题之一,不仅仅局限于艺术家群体,已经有越来越多的人和机构,通过AI绘画来实现自己的创作需求。譬如游戏公司,通过AI绘画来获得初级的场景和人物形象素材;电商公司,通过AI绘画更快地实现产品描述配图等。
去年11月,UCloud上线了AI绘画stable diffusion平台,在GPU云主机内置stable diffusion模型,提供jupyter可编程页面,根据用户的创意描述来生成图片。今年,UCloud将AI绘画平台全新升级,内置可视化操作界面,提供图像精准控制(Controlnet)、图像分割(Segment Anything)、图像微调等插件,为艺术创作者和设计师提供更多便利。
在UCloud使用AI绘画服务,创建仅需三步:
1) 创建GPU云主机,镜像市场选择“AI绘图 Web UI”镜像,防火墙策略开放7860端口接口
2) 登录GPU云主机,执行镜像首页提示的命令,就可快速启动AI绘画服务
3) 登录http://eip:7860即可访问stable diffusion Web UI页面(EIP为创建的GPU云主机的外网ip)
*参考文档:
https://docs.ucloud.cn/gpu/practice/stable_diffusion_webui
产品新特性:

可视化操作界面,预装多种风格模型
目前已预装stable-diffusionV1.5,stable-diffusionV2.1,anythingV3(动漫风格),dreamlike-photoreal(写实风格),deliberate_v2(写实风格)等模型。
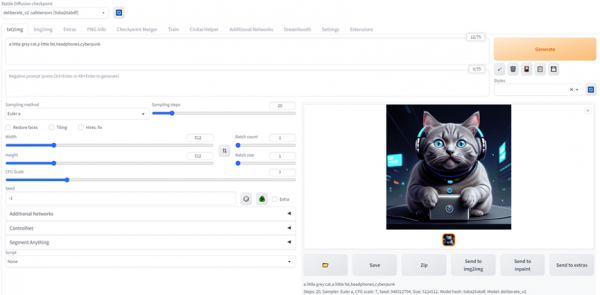
以Prompt:
“a grey cat, headphone, cyberpunk”为例,不同模型出图效果示例如下:

Anything V3

Deliberate

Stable diffusionV2.1

图像精准控制
在AI绘画平台镜像中,已配置Controlnet插件,预装了canny、openpose、scribble等图像精准控制模型,支持边缘检测、pose指定、涂鸦等图像条件输入。
以canny模型为例,输入及输出结果如下:

Input
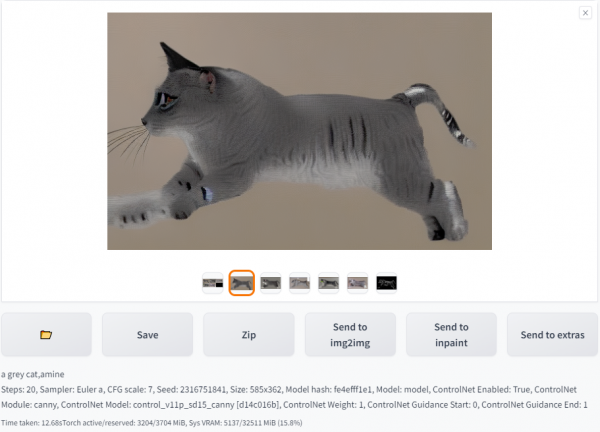
Output
以openpose模型为例,输入及输出结果如下:

Input
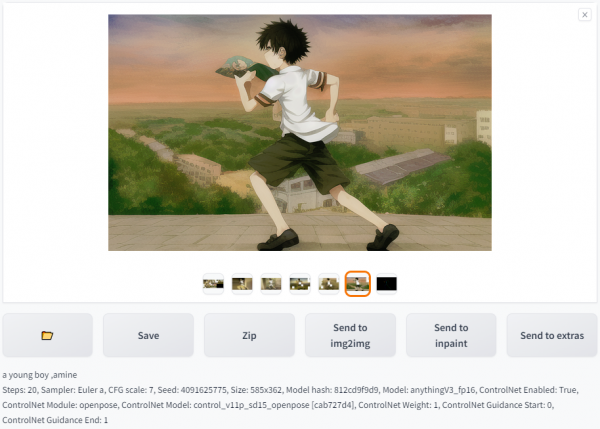
Output
以scribble模型为例,输入及输出结果如下:
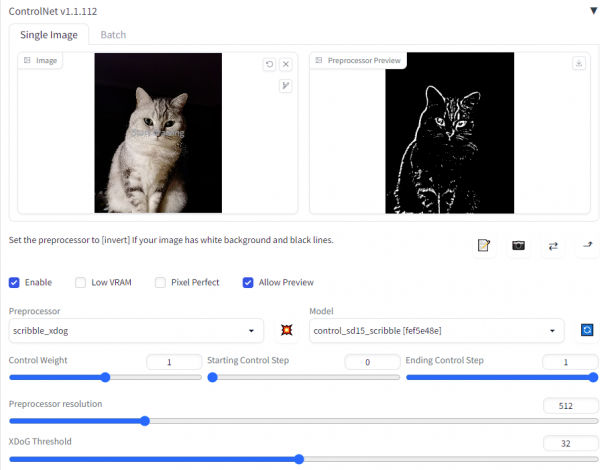
Input
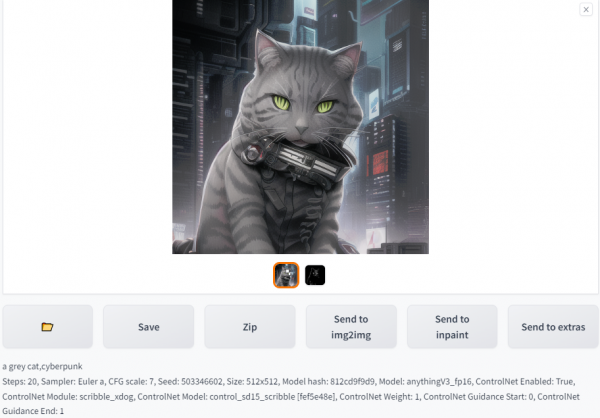
Output

图像分割
预装segment anything插件,支持图像分层,切割,单次可处理单张或多张图片。页面预览如下:

例如输入一只猫的图片,基于预装的sam模型,可以快速实现图像的分层、蒙版、分割。如下图所示:
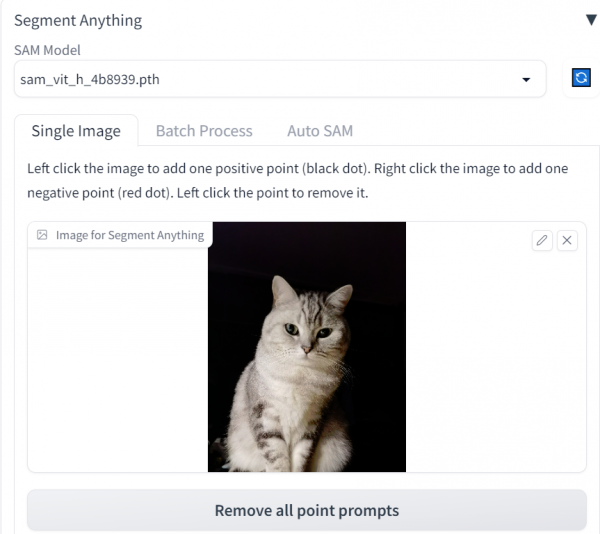
Input
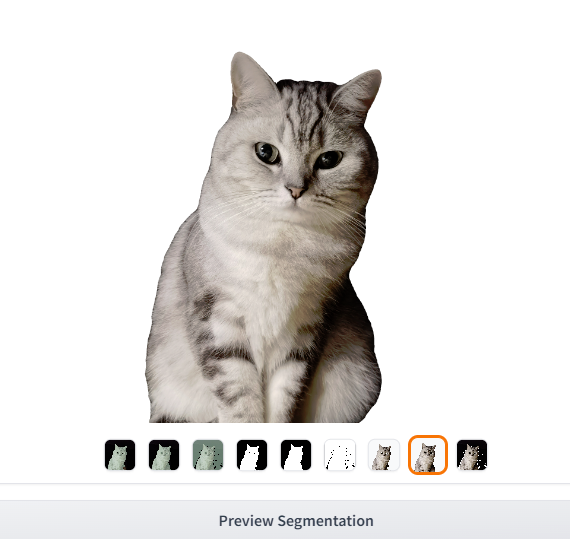
Output

图像微调
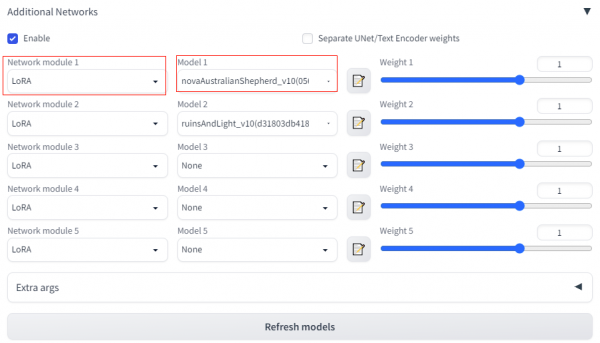
AI绘画平台镜像预装Additional-Networks插件,支持基于LoRA模型微调图片风格。
在webui页面操作步骤如下:
1) Checkpoint选择
“chilloutmix_NiPrunedFp32Fix.safetensors”
2) 选择“Additional Network”
3) module选择“LoRA”
4) 选择需要叠加的风格模型

模型选择页面
以Prompt:
“a grey cat, headphone, cyberpunk”为例,如图所示模型输出结果如下:
Input

Output
写在最后
AI绘画的应用场景非常广泛,可以用来创作美术作品、设计图形、制作动画和游戏等。它能够快速地生成高质量的图像和图形,同时还能够自动化一些重复性的工作,节省了大量的时间和精力。所以,不论您是专业的绘画爱好者,还是对AI技术感兴趣的普通人,都欢迎通过我们的AI绘画服务来体验一次AI与艺术的融合。

更多产品咨询,请扫码了解
来源:业界供稿
好文章,需要你的鼓励


SAP 2026年蓝宝石大会:CEO承认AI战略曾走弯路,全面转向业务自主化【正常】
SAP首席执行官Christian Klein在2026年Sapphire大会上坦承,公司约在八九个月前调整了AI战略方向,从强调AI技术本身转向聚焦业务成果,目标是实现"自主企业"愿景。SAP发布了全新品牌SAP Business AI和SAP Autonomous Suite,重构AI平台以更好融入客户业务上下文。SAP高管还强调,需防范"智能体失控"风险,并引入"企业记忆"概念提升AI决策的精准度。

眼睛看得多,就一定懂得多吗?清华大学等机构揭开多源视觉推理的隐藏陷阱
研究揭示多源视觉融合并非总有益,提出MARS框架通过单源锚点量化信息增益,动态调节多源融合优势,在多个视觉推理任务上实现显著性能提升。

NHS单一患者电子档案或每年减少两万次急诊就诊并节省两千万英镑【正常】
英国卫生与社会保障部发布测算数据,显示NHS数字化单一患者记录(SPR)每年可减少约2万次急诊就诊,并节省约2000万英镑。该计划将强制要求全科医生和医院共享患者数据,形成统一的健康档案,患者可通过NHS App访问。该措施是政府100亿英镑医疗数字化计划的核心。此外,NHS虚拟医院NHS Online已正式成立,预计2027年上线,首三年可提供约850万次诊疗服务。

MiniMax推出超高效AI大模型:用10%的“算力油耗“,跑出顶级AI的实力
MiniMax发布M2系列混合专家大模型,总参数2299亿但每次仅激活98亿,通过专项数据流水线、Forge强化学习系统和自进化机制,在代理编程、深度搜索等任务上达到顶级闭源模型水平。
2023
04/28
13:46
分享
点赞

NHS单一患者电子档案或每年减少两万次急诊就诊并节省两千万英镑【正常】
苹果智能眼镜据报道推迟至2027年底发布
2026年第一季度Mac恶意软件威胁态势全面回顾【正常】
AI的冷漠与空洞:它的乏味之声为何契合当下政治氛围【正常】
苹果新版Apple TV与HomePod mini将于今秋发布,Siri遥控器或迎来更新
从被动响应到自主运营:IT领导者下一步该怎么做【正常】
苹果AI智能眼镜延迟至2027年底发布,Vision Air最早2029年亮相
真正改善日常生活的家居AI功能盘点
"心灵子嗣"会是人类繁殖的未来吗?
水资源成为AI数据中心扩张的新瓶颈【正常】
CoreWeave推出AI智能体自主优化能力,企业部署效率大幅提升
英国智库呼吁:赋予员工更多AI决策权,确保技术红利公平共享
