
云智能企业,实现应用创新和云成本之间的完美平衡
如今,企业领导者正在想方设法解决当今数字经济背景下存在的固有矛盾。一方面,他们认识到必须继续在云端推动围绕应用程序的创新,才能吸引客户并在竞争中脱颖而出;但另一方面,许多企业正苦于不断上升的云成本在侵蚀企业的利润。
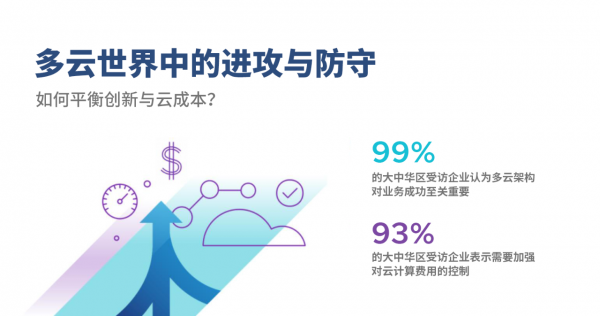
随着企业的日常运作越来越依赖多云架构,这种矛盾正在加剧。根据VMware《多云成熟度调查报告》显示,99%的大中华区企业认为多云架构对业务成功至关重要。与此同时,93%的大中华区企业表示需要加强对云支出的控制。1简而言之,虽然企业意识到多云架构至关重要,但也同时受困于不断上升的云成本。
多云模式成为主流
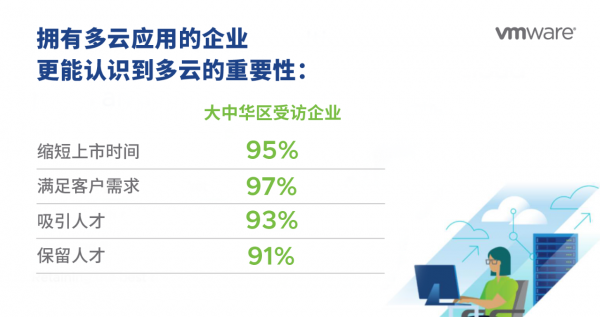
VMware全球调查证实,多云模式在过去两年中已经成为主流。企业应用开发团队在拥抱多云方面表现得尤为积极;89%的大中华区企业表示,其拥有“多云应用”或拥有能够在多个云中扩展的应用程序。1
VMware高级副总裁兼首席技术官Kit Colbert在《福布斯》杂志上发表的一篇文章中写道:“我们建议应用团队不要以‘非黑即白’的态度看待公有云(不是全盘接受、并使用其所有服务,就是不使用任何公有云服务),而是要比较云服务和来自第三方的具体服务,判定其能否满足自己的需求。作出最佳选择的基本原则是将云和第三方单纯视为服务集合,并根据应用团队的需要混合搭配。这可以给应用团队带来更大的选择范围,让他们在构建和操作应用时获得最佳体验和功能。”
拥有多云应用的企业表示,多云策略带来的优势包括缩短产品上市时间、满足客户需求、招募和留住顶尖人才等。
正视云成本问题
企业领导者认识到,随着对云端应用创新投资的不断增加,其在控制和管理云成本上承受的压力越来越大,这将不断侵蚀企业利润,并在整个IT预算中占据越来越大的份额。根据Gartner预测,公有云服务的增长率将从2022年的17.9%提升至2023年的18.5%。2 IDC的最新数据显示,45%的企业认为其在云和数据中心基础设施上的开支过大。3《多云成熟度调查报告》中的受访企业也有同样问题,约39%的大中华区企业表示其正在为超出预期的云成本感到焦虑。

疲于应对云混乱的企业与更加成熟、先进的云智能企业之间存在着鲜明的对比。与云智能企业相比,处于云混乱状态的企业遭受着巨大的财务收入损失。
云智能模式有助于多云应用创新
所有多云企业的最终目标都是最大程度地利用云固有的可扩展性来取得战略优势,而不是让这种可扩展性演变成失控的支出。处于云智能状态的企业在这方面显然更游刃有余。
VMware高级副总裁兼首席信息官Jason Conyard表示:“目前首席信息官也在评估实现云的灵活性与可扩展性所付出的成本。他们正在寻找新的方法,既能控制不断上升的云成本,同时又能够自由流畅地运行跨云服务。”
这里有一个很好的案例。日本沢井制药株式会社(Sawai Group Holdings)在其数字化转型过程中,采用VMware Aria进行成本管理和安全监控,从而使其成本降低了10%,同时保证了运营安全。该公司的目标是在未来降低26%的成本。
沢井制药株式会社集团信息技术部门总经理Koji Takeda表示:“我们上云面临的难题是如何将整体成本和安全状况可视化,并创建一个易于理解和管理的系统。无论是从技术,还是从成本角度来看,这个目标似乎都难以实现。最后,我们在VMware解决方案的帮助下快速、低成本地解决了这个难题。”
1 Vanson Bourne,《多云成熟度调查报告》,2022年10月。
2 Gartner,《2022年第4季度更新的2020-2026年全球公有云服务预测报告》,2022年12月20日。
3 IDC,《业务成果和关键绩效指标在全球不确定时期塑造了数字基础设施支出的优先权:IDC全球数字基础设施2022年全球情绪调查结果》,文件编号US49066722,2022年8月。
来源:业界供稿
好文章,需要你的鼓励


Waymo因洪水问题发布召回,近4000辆自动驾驶车辆受影响
Waymo近日发布软件更新,对旗下约4000辆自动驾驶车队实施召回,以帮助车辆规避积水道路。美国国家公路交通安全管理局(NHTSA)指出,此前Waymo机器人出租车在遭遇无法通行的积水路段时,仅减速而未完全停车。此次召回涵盖第五代和第六代自动驾驶系统车辆,共计3791辆。Waymo表示正在完善软件防护措施,并已限制车辆在极端天气及易发洪涝区域的运营。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。

AI驱动的“地面情报“系统:Samsara如何帮助城市主动修复坑洼路面
路面坑洞每年给城市造成数百万美元损失。车队管理公司Samsara推出名为"Ground Intelligence"的AI解决方案,通过已安装在数百万辆商用卡车上的摄像头,自动识别并追踪坑洞的位置与劣化程度。该系统以仪表盘形式呈现,可主动向城市管理者推送预警信息,将被动响应转变为主动规划。目前,芝加哥已成为其新客户。未来还将扩展至涂鸦、损坏护栏等城市基础设施监测。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。
2023
04/19
10:47
分享
点赞

遭黑客入侵的Klue称犯罪分子正在删除窃取的客户数据,但新的黑客组织接连发出威胁
苹果起诉OpenAI窃密:前员工利用零日漏洞下载机密文件
Monarch Tractor陷入困境,被卡特彼勒收购
Uber联手Hertz为Lucid无人驾驶出租车提供运营支持
Aurora与McLane达成合作,无人驾驶卡车将在德克萨斯州运营
Waymo因洪水问题发布召回,近4000辆自动驾驶车辆受影响
AI驱动的"地面情报"系统:Samsara如何帮助城市主动修复坑洼路面
特斯拉Robotaxi披露两起远程操控事故
特斯拉FSD自动驾驶软件加速进军欧洲市场
Waymo暂停高速公路服务,因自动驾驶出租车难以应对施工区
Waymo自动驾驶车辆注册数量领跑德克萨斯,特斯拉远落后
Siri AI、ChatGPT、Claude真实横评,谁才是最强AI助手?
