
互联网级的视频需要属于自己的超级计算力
视频已经占领了互联网,几乎有80%的流量都是来自视频。过去几年,数据中心越来越依赖GPU加速卡来对网络上运行的大量视频流量进行转码,从而卸载CPU的大部分工作,以期降低延迟、成本和功耗。
随着视频性质的转变,这也只会变得更具挑战性。过去流行的模式,是由Netflix这样的公司为主导的一对多点播环境,或者是像体育比赛直播这样的赛事,其中视频源从一个地方开始,流经云数据中心运行,内容交付网络(CDN)和边缘服务器,然后到达企业办公室或者是消费者家中。
但是这个过程中总是存在一点点延迟的,因为需要在数据中心完成大量处理和计算以确保良好的质量,或者因为广播公司需要几秒钟的延迟来进行视频编辑。在这种情况下,这种程度的延迟并不是一个很大的问题。
但视频的交互性越来越强,不仅是Twitch视频游戏直播服务等消费者应用,还有在疫情期间被在家办公群体采用的视频会议等企业工具。2019年12月,Zoom每天有1000万用户。到2020年6月,随着疫情席卷全球,这个数字达到了3亿,其他服务例如微软的Teams和思科的Webex,也出现了类似的增长。
这种交互式视频环境带来了更大的压力,也就是需要数据中心资源来减少延迟或者是消除延迟。2021年,视频市场中有70%的视频都是交互式视频。
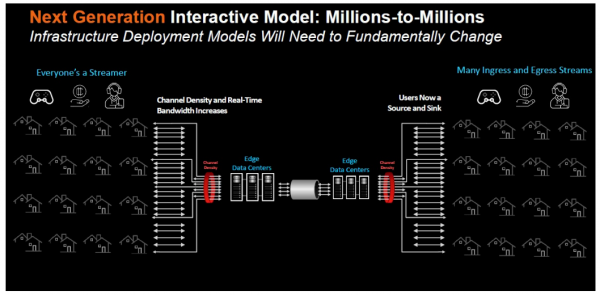
AMD公司高级产品营销经理Vincent Fung表示:“在网络管道和服务器端处理方面,这开始给基础设施造成压力。以前传统[的基础设施]模型开始没有太大经济意义了,要跟上发展步伐满足这些场景的需求,变得越来越困难。”
此类用途正是AMD首席执行官Lisa Su和其他高管在去年初以350亿美元收购可编程芯片制造商赛灵思(Xilinx)时想到的。通过Zen微架构、Epyc服务器CPU以及Radeon GPU,AMD过去几年中大举回归数据中心,占据了超过25%的数据中心CPU市场,同时看到了在GPU市场的增长空间。
将赛灵思收入囊中,让AMD在数据中心领域的影响力越来越大,不仅通过FPGA,还通过AI引擎、自适应片上系统、以及用于网络和边缘等领域的软件。赛灵思还构成了AMD自适应和嵌入式计算事业部的基础,带来了一系列专用视频编码卡。
这其中,还包括了赛灵思在2020年推出的Alveo U30媒体加速卡,旨在用于实时流媒体工作负载,通过云端的Amazon Web Services EC2 VGT1实例或者在预配置设备中进行现场视频转码。Fung表示,AMD“一直期待互动媒体的发展,因此我们推出了第一代产品,即U30。”现在,AMD正在推出下一代产品Alveo MA35D的样品,这是一款数据中心媒体加速卡和专用视频编码卡,与U30相比有显著的改进。

Fung说,实时视频流越来越多,这“造成了流量的急剧增加”。“在一对多变成多对多的情况下,当我们查看这些交互式用例时,从视频的角度,这就需要做更多的处理。你消除了为解决这些非常苛刻的交互式用例而必须做出的妥协。有很多人在使用它,所以你需要高性能。你希望将带宽成本降至最低,因为带宽占用量是很大的,耗电量都成为了一部分支出。”
与Alveo U30一样,MA35D专为实时交互式视频编码而设计,是AMD收购赛灵思之后推出的首款产品。MA35D包含了2个5nm ASIC视频处理单元(VPU),可以提供4倍的同步视频流——最多32个1080p60通道——并支持8K和AV1分辨率编码,Fung表示,这是计算密集型的最新标准。
根据AMD公司视频战略和开发负责人Sean Gardner表示,现在有很多大公司都采用了该标准,包括Meta、微软和思科,以及谷歌YouTube、Netflix和Roku等此类服务。
Gardner说:“这项标准已经问世,但十分有限,每一个新标准,理论目标都是实现比以前标准高50%的压缩效率。如果我们锁定在了视觉质量,那么我需要多少字位才能达到这一质量标准?每个新标准都力求降低50%的带宽来实现这一质量水平,但每个步骤都要在编码端有所花费,因为这就是差异所在。你要让解码成本更低,因为编码体积很大——或者曾经体积很大,现在已经开始有所改观——但这会导致每个新编解码器有5到7倍的损失。”
他说,延迟是关键。
“Netflix没有延迟[问题],他们可能需要10个小时——确实如此——来处理一小时的视频,并且他们可以在产能过剩的下班时间使用这些带宽。但现场直播需要在16毫秒内进行,否则你就落后于实时,每秒60帧。想想这个场景,你可以使用Zoom、Teams或者Webex,可能有数十亿人同时使用这些服务。或者像Twitch这样拥有数十万个用户的服务。另一方面是,对于实时[流媒体]来说,你不能使用类似缓存CDN的架构,因为你无法承受它所带来的延迟。这就是为什么需要加速。”
除了4倍的通道密度外,测试还表明,将于第三季度投产、建议零售价为1595美元的MA35D每通道成本降低2倍,压缩率降低1.8倍,延迟降低4倍。此外MA35D还可以进行扩展,从带有卡的32个流到扩展到有8个卡的服务器格式256个流,然后扩展到机架或数据中心级别,提供高达52%的比特率降低以节省带宽。
除了VPU,该加速卡还包括了编码器和解码器、自适应比特率缩放器、用于沉浸式计算的合成器引擎、视觉质量引擎和“Look-Ahead”,用于分析运动内容以及高效压缩,此外还有用于优化视觉质量的AI处理器。
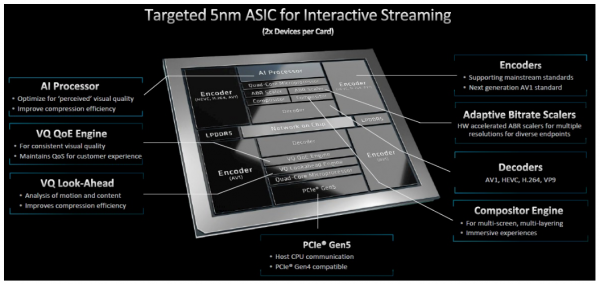
主机CPU通信是通过PCI-Express 5.0总线进行,该总线向后兼容Gen4。
Fung表示:“加速器是整个视频管道,目标是不必把任何这类任务放在芯片之外,这样我们就可以保持一致的性能水平。我们可以交付的内容不会受到近实时用例的影响。一切都在这里,硬件化了。我们这里有一个AI模块,典型的编码、解码都在这里进行,但同时我们也有基础的优化。”
在视频领域,AMD正在寻求摆脱Nvidia的GPU战略,Nvidia的T4 Tensor Core主要针对AI推理和L4图形,而英特尔及其GPU Flex系列则主要用于数据中心媒体流。Gardner说,当流媒体视频数量开始增加的时候,唯一真正厉害的是Nvidia GPU。
现在大家都看到这类加速卡有两个关键应用,分别是视频和人工智能。视频市场现在很庞大,但AI也在兴起。AMD正在针对这两大用例制定策略。
他还说:“一切都开始开放了,英特尔和Nvidia继续通过GPU推动发展,或者英特尔正在尝试用大AI和小视频,英特尔正以一种中等视频、中等AI来解决这个问题。我们从99%的视频开始,已经添加了一些小型AI,但我们并没有试图进入智能城市和监控领域。这种AI专门针对在线的、像素级的处理。”
好文章,需要你的鼓励


Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
火箭实验室(Rocket Lab)宣布计划以现金加股票方式,斥资80亿美元收购主要卫星运营商铱星通信(Iridium Communications),交易预计于2027年中完成。铱星目前运营着由66颗活跃低轨卫星组成的星座网络,拥有约255万活跃用户,2024年营收达8.717亿美元。收购完成后,Rocket Lab计划借助其新型重型运载火箭Neutron及Lightning卫星平台,扩大铱星星座规模,开拓未被覆盖的市场并降低发射成本。

腾讯混元视觉团队打造“图像翻译官“:让AI用离散数字读懂每一张照片
腾讯等机构提出ViQ框架,通过两阶段渐进量化训练,让离散视觉编码在多模态理解和图像重建上同时追平连续特征编码器,训练速度最高提升70%。

Tidal宣布将为AI生成音乐添加标签并移除欺诈内容
音乐流媒体平台Tidal宣布,将于7月中旬启用自动化工具,对完全由AI生成的音乐添加"AI"标识,并移除具有欺诈性质的曲目。平台还将取消AI生成音乐的版税资格,仅向真人创作、演唱的原创音乐开放变现渠道。此外,Tidal明确将高频异常上传、干扰真实艺术家等行为列为欺诈活动。Deezer、Spotify等竞争对手此前已推出类似检测机制,流媒体行业正加速构建AI内容治理体系。

香港科技大学联手华为研究院:AI绘图训练速度提升2.78倍,秘诀藏在“概率分工“里
香港科技大学与华为联合提出LISA训练方法,通过让副网络对齐"似然分数",将ControlNet等图像生成模型的训练收敛速度提升逾2.78倍,同时改善图像质量与条件控制精度。
2023
04/13
12:31
分享
点赞

Tidal宣布将为AI生成音乐添加标签并移除欺诈内容
Claude Tag:将职场AI从个人助手升级为团队协作伙伴
数百万颗超新星爆炸或将揭开暗能量的秘密
Base44发布自研大语言模型,氛围编程平台寻求核心竞争壁垒
遗留系统与数据鸿沟制约亚洲财资中心发展
机器人手部公司与特斯拉达成商业秘密诉讼和解,完成1100万美元融资
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
想进大厂?初创公司或许才是你的最佳跳板
公共电力性价比优势面临多年来最严峻考验
特斯拉开始向HW3车型推送FSD v14"精简版"
新品牌Gobao推出电动自行车快充电池与eCVT驱动系统
闲置GPU集群每日损失可达数百万美元
