
微软的智能奥秘:专为AI运行而构建的基础设施

与整个技术行业一样,我们也一直在关注微软如何运用AI基础模型转变其服务和软件产品组合。虽然不敢妄下断言,但从微软在数十个区域部署的几十万个GPU来看,软件巨头可能已经积累起地球上规模最大的AI训练基础设施池。
从某种程度上讲,这种规模的AI训练是个只有超大规模服务商和云服务提供才有资格下场的游戏。相比之下,其他领域只能对预训练模型做微调,或者运行体量较小的新模型。
而作为基础模型的最大消费者之一兼基础模型生产基础设施的最大提供商之一,微软算是两边押宝,意味着无论市场走向何方、如何发展,微软都永远不亏。与其说这是精明的商业算盘,倒不如说这是经济体系中规模化资本的天然优势。其实微软之前的路走得并不顺,没能抓住2008年经济衰退的机会及时扩大规模,差点因此断送了跟亚马逊云科技正面抗衡的机会。但值得庆幸的是,微软的股东知耻而后勇,从十年前开始认真投资Azure。Windows Server堆栈和它的数千万客户也给微软提供了Azure发展所必需的资金和受众群体,后发者微软终于也拥有了前景光明的云业务。
所有这一切的关键,是将正确的超级计算基础设施投入其中,而这项工作的执行者就是微软Azure HPC与AI总经理Nidhi Chappell。Chappell的团队负责Azure全部工作负载优化型计算、存储和网络任务的落地,具体包括HPC模拟和建模、AI训练与推理,还有SAP HANA、自动驾驶、可视化和机密计算等。
Chappell于2019年6月加入微软,此前曾担任英特尔数据中心企业与HPC业务高级总监,还管理过英特尔的AI产品线及入门级服务器与定制化至强SoC业务。她非常了解微软的客户群体,努力保证Azure的基础设施能够帮助不同规模、各行各业的公司参与到AI革命中来。在日前开幕的英伟达GPU技术大会(GTC)之前,Chappell接受了The Next Platform的采访,探讨微软与英伟达的合作关系以及微软如何建立自己的AI基础设施。
主持人:咱们开门见山,从微软的超大规模厂商和云提供商这双重身份说起。在运行Prometheus或者OpenAI训练这类服务时,微软用的就是自家Azure吗?更确切地说,微软会像普通客户一样使用Azure实例,还是说设立了单独的基础设施,克隆了Azure体系但专门只为微软自己服务?
Nidhi Chappell: 我们的基础设施完全来自Azure公有云,所以面向所有用户。无论是内部团队运行的Bing、ChatGPT还是其他负载,一切都完全依托于Azure公共基础设施。
主持人: 那微软的内部团队会提前试用吗?用这种方式确保基础设施在面向公众发布时能运行良好?
Nidhi Chappell: 不不,当然不会。我们用的是完全相同的基础设施,同时面向内部和外部开放。我们从业务建立之初就在朝这个方向努力。我们希望确保自己能建立起灵活缩放的构建块。因为你知道,客户的规模不同,他们的实际要求会有所不同,所训练的模型大小也有差别。我们的架构具有极强的可扩展性,既能支持低端训练也能承载高端训练。但其中使用的都是完全相同的构建块。我们不会根据业务规模改变构建方式,只会根据业务规模改变交付方式。
主持人: 说到规模,我还有另一个问题。微软与英伟达在合作倡议中公布了“Hopper”GPU系统,那这到底是通过NVLink Switch结构把256个GPU粘合到同一个内存地址空间内,还是说用独立的PCI-Express版Hopper或者带NVSwitch互连的Hopper HGX系统把八块基板整合在一起?如果微软确实用到了NVSwitch,那当然很棒;但如果没用,我其实对这种架构并不太看好。
Nidhi Chappell: NVLink扩展仍处于开发阶段。我们非常关注NVLink的未来扩展,但归根结底,我们真正需要提GPU之间能够相互通信。所以通信能力才是关键,具体技术选择不要妨碍通信就好。
现在,有了我们自己和整个行业已经及正在开发的各种模型,尤其是各种专家模型,接下来的任务就是保证一定水平的通信吞吐量。经过分析,我们发现最新一代InfiniBand已经能为GPU的相互通信提供良好性能。这已经符合我们的既定目标,就是保证获得可扩展的充足性能。当然,展望未来,我们也将继续关注NVLink扩展并逐步尝试引入。如果效果不错,我们就会全面使用。这里还有个区别,如果选择NVLink,用户必须清楚NVLink域有多大,但InfiniBand就没这个必要——只需编写代码,各个GPU之间就能顺利实现通信。
主持人: 那底层可能会使用支持MPI的GPUDirect?
Nidhi Chappell: 没错,基本就是MPI。
主持人: 这就是我提这个问题的初衷。我本人比较守旧,记得2000年初那会就出现过搭载128甚至256个CPU的大型NUMA设备,记得微软还为这机器编写了一些早期操作系统。虽然让128或者256个CPU一起共享内存确实方便,但NUMA域管理起来要比很多人以为的麻烦得多。而且跟20年前的内存速度相比,互连速度也要慢得多。这个咱们有一说一。NVSwitch架构也会增加成本,所以除非真能增加价值,否则很多大规模厂商和云服务商并不喜欢。
Nidhi Chappell: 另外我还想强调一点,这种架构会将GPU互连量限制在256个。我无法公开OpenAI训练中所使用的GPU规模,但肯定要比256个GPU大上一个数量级。
主持人: 哈哈,我猜可能会在10000到12500个节点中使用80000到100000个GPU吧,这应该是微软这样的技术巨头能够建立的最大实例了。
Nidhi Chappell: 我不能说得更多,但确实是个相当大的数字。
主持人: 这个数字非常重要,因为大家应该了解如今的基础模型到底对应着怎样的AI训练规模。十年前,Hot Chips大会上大家都在争相讨论,因为当时谷歌估计是在用8000个GPU进行AI训练。现在,这样的规模的集群实例在各大公有云服务商那里都能租到了。

Nidhi Chappell: 总之,我觉得在AI训练和NVLink扩展方面,成本其实没那么重要,毕竟它基本就固定在那里。更重要的是,小域之内的256个GPU之间将拥有更快的通信速度,而这个规模之外的GPU通信速度就要差得多。
目前,大家可以在Azure上通过InfiniBand架构直接租用4000个GPU,我们以公共实例的形式对外开放。但就在两年之前,我还觉得这样的规模根本就不可能。所以如果客户是一家刚刚成立的初创公司,初步着手构建AI模型,那根本不会马上用到几万个GPU,这4000个GPU就足够起步了。我们还扩展了InfiniBand架构,在其上添加了更多GPU,希望服务于少数“胃口更大”的客户。所以我们在4000个GPU之外,还有6000个GPU的实例选项,都对客户公开可用。我们还将为需求更复杂的客户提供规模更大的选项,相信从事基础模型开发的客户很快就会超越这样的上限。
主持人: 这样规模的服务要怎么使用啊?客户肯定得跟云服务商建立某种程度的协作。我猜如果真要一口气用4000甚至6000个GPU,那肯定得单独打电话联系……
Nidhi Chappell: 在构建大语言模型时,过程中肯定需要疯狂吞噬计算资源。所以客户必须搞清楚自己对资源的扩容需求,我们也会在这方面跟客户合作,讨论未来计划要走多远,再据此为他们整合基础设施。但我们提供的具体方案很多,不只是把基础设施粘合在一起,而是投入了很多精力来保证客户能够运行起规模如此庞大的基础设施。
相信你的知道,AI训练其实是一项同步工作,要求把同一项工作内容分发给那么多的GPU。我曾经开玩笑说,我的工作就是指挥芝加哥交响乐团和纽约爱乐乐园一同演奏。基础设施编排真的跟乐园指挥很像,一个GPU出了故障都会引发大问题。所以我们才建立起现在的系统,保证运行永远不会失败。流程内置了弹性空间,基础设施也内置了弹性空间,这样才能对模型做线性扩展、始终保证稳定的算力供应。
主持人: 无论是从自主运行大规模AI训练的用户角度,还是从为大量客户提供训练后AI模型的云平台的角度,微软都必须借助英伟达的GPU资源。那微软和英伟达之间,保持着怎样的密切合作关系?
Nidhi Chappell: 我们采购的是英伟达的标准部件,也会在某些方面与英伟达共同开展工程设计。我们会预计考虑未来几代产品的实际情况,包括交流微软将以怎样的节奏升级数据中心冷却、需要怎样的可靠性,或者需要达到怎样的精度标准等……
主持人: FP0威力无穷,所以这个问题应该不难找到答案……
Nidhi Chappell: 哈哈,真是那样就好了。但严肃来讲,我们在大规模AI方面经验丰富,可以在这方面提供很多反馈。我们还提供了很多关于英伟达产品质量的反馈。他们想要打造的是迅如闪电般的产品,但这样的硬件并不一定是规模化应用下的最优方案。而我们的需求就是大规模部署,所以只能边测试边实际部署。就这样,我们实际上成了英伟达的规模化应用测试伙伴。
主持人: 所以英伟达才开始构建DGX服务器,之后开始在内部构建“Saturn-V”和“Selene”超级计算机,并尝试用Grace-Hopper构建Eos设备。他们不单要考虑如何把各个部分组合起来,还得探索如何在自己的工作负载上大规模运行。
Nidhi Chappell: 你知道英伟达正把所有开发负载都转向Azure吗?
主持人:不知道,但这个很重要,能不能多讲讲?
Nidhi Chappell: 这个确实很重要,他们也没有公开发布,但多少也提到过。英伟达其实已经把所有工作负载都迁移到了Azure上,包括内部应用开发、软件堆栈、企业堆栈等等……
他们在文章中委婉地表达过这方面消息,所以现在回头看,大家会意识到“哦,原来是这么个意思。”是的,他们已经把所有开发负载迁往Azure公共基础设施,于是英伟达现在既是我们的合作伙伴、也是我们的客户。他们知道我们正在以怎样的规模发现问题,我们的运行规模比任何业内同行都要大。
主持人: 明白,这事我会继续跟进。
那咱们再聊下一个问题。我很好奇,您在Azure AI项目底层的InfiniBand网络采取了怎样的拓扑设计?应该有很多不同的方法可以实现计算聚合吧?
Nidhi Chappell: 我们没有透过关于拓扑结构的细节消息,我只能说:这是个胖树拓扑。
主持人: 有意思。这跟我想象得不太一样,但胖树拓扑确实是HPC模拟和建模负载领域比较常见的结构。
Nidhi Chappell: 这也是我们跟客户联合设计之后的结果,双方会讨论新模型将面对怎样的流量,特别是在专家模型运行起来之后,这里会有大量通信,所以我们的结构后端有一个完整的胖树InfiniBand拓扑。
主持人:说起新东西,你们正在用400 Gb/秒的Quantum 2 InfinBand;如果1.6 Tb/秒的Quantum 4来了,你会立马向英伟达下单吗?
Nidhi Chappell:
我觉得最重要的是在系统中寻求平衡吧。没错,想要保证GPU得到正确馈送,就必须确保内存架构和内存带宽不断扩展。绝对不能让GPU的网络成为枢轴点或者性能瓶颈。所以我们才会与英伟达等供应商密切合作,确保内存带宽和内存容量始终随模型大小的变化而伸缩。
主持人: 但Hopper GPU扩展了显存带宽,显存容量却没有提高。
Nidhi Chappell: 这确实是个挑战。所以英伟达也在努力尝试增加内存容量。否则用户就会将目光投向CPU内存容量,尝试把部分负载交给CPU处理,所以系统的均衡性是最重要的。
主持人: 我一直开玩笑说,Grace Arm CPU是一款非常有用的可编程控制器,负责操控Hooper GPU的480 GB DDR5内存块。这一容量要远高于速率为3 TB/秒的80 GB HBM3,但HBM内存的价格是普通LPDDR5X内存的3倍。我觉得在Hooper GPU上引入5 TB/秒的传输带宽应该会很有趣,比如采用512 GB甚至是1 TB的堆叠HBM3内存。我知道这样的组合成本会高出天际,但这应该也能省下一些GPU吧?
Nidhi Chappell: 有趣的是,在某些情况下,模型是可以适应内存的,所以内存并不是瓶颈。我还是觉得增加GPU数量更有意义,因为这样能加快处理速度。我们可以降低精度、观察稀疏性、寻求将模型引入GPU的不同方式,借此摸清自己到底需要多大的内存带宽。
但可以肯定的是,模型训练的时间越长、所使用的数据集越大,模型的精确度就越高。所以真正的目标就是用更大的数据集进行更长时间的训练,结合大量参数来改善收敛效果,让最终成果能够更加精确。正因为如此,我们才需要更多的GPU,这样基础设施就能适应更大的模型、更大的模型又能带来更精确的结果。
主持人: 在运行OpenAI GPT-3或GPT-4的时候,你观察过GPU的资源利用率吗?虽然微软不一定要买,但Hopper GPU的售价确实定在了2万到3万美元之间,用户肯定希望尽量提高资源利用率、让它物有所值。
Nidhi Chappell: 您确实非常了解HPC领域啊。我来打个比方,在HPC中执行同步作业时,会大量占用CPU。AI也是如此,这是一项高度要求同步的工作,每个GPU都会得到充分利用。这又回到了系统架构问题,只要系统架构能保证网络不成为瓶颈,那么GPU的利用率就会非常高。现在的情况也确实如此,它的工作非常协调,所以这些昂贵的资源维持着很高的利用率。我们当然不能让它闲着,对吧?我们也在确保维持很高的利用率。
主持人: 再来比较H100和A100,它们的差别就是用2到2.5倍的成本来购买3倍的性能。对于没有大规模负载需求的用户来说,A100就足够了。A100 GPU也做了自己的设计取舍,牺牲的就是一部分速度。换言之,只要愿意花更长的时间来训练模型,那整个成本就会更低。类似于整个训练周期要持续3个月,但训练成本只相当于原先的一半。
Nidhi Chappell: 所以微软才会提供一系列产品组合。有些客户在开发基础模型时对性能更加敏感,他们就更适合使用Hopper、享受微软提供的规模化基础设施资源。但也有些客户更适合用A100进行微调或小规模训练/推理。A100不会过时,它只会被重新投入其他工作,因为它会落入新的价格点、再次找到适合自己的对应市场区间。
好文章,需要你的鼓励

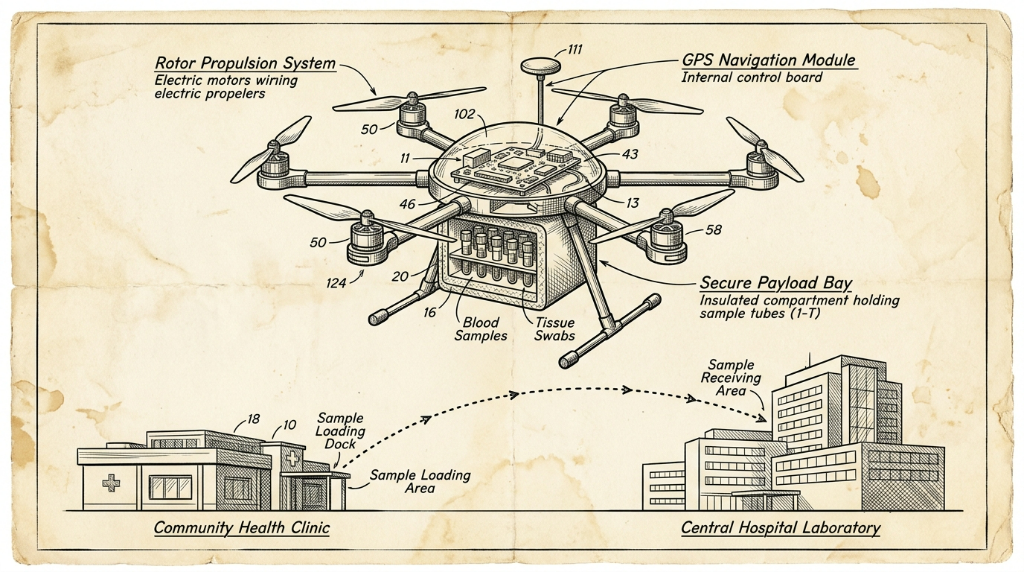
英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2023
03/22
17:14
分享
点赞

WAIC2026 现场直击:开普勒顶流人气王,麒麟系列火爆出圈
面壁智能将密度定律带入具身智能
龙磁科技拟投3.58亿元扩建越南永磁铁氧体基地
首创一层Scale-up网络256卡全互联,摩尔线程MTT C256超节点为万卡及十万卡级集群夯实底座
从高血压诊疗入手,北京安贞医院让医疗大模型走出聊天框
西门子肖松:以场景为牵引,推动工业AI从单点实效迈向生产力跃迁
打造Token极致性价比 新华三震撼亮相2026世界人工智能大会
机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
