
英特尔实验室和宾大医学院使用联邦学习改善脑肿瘤检测
英特尔实验室(Intel Labs)和宾夕法尼亚大学佩雷尔曼医学院(Perelman School of Medicine at the University of Pennsylvania)近日发布了一项联合研究,该研究使用联邦学习(一种分布式机器学习和人工智能方法)来帮助医疗和研究机构发现恶性脑肿瘤。
据说这项研究是有史以来规模最大的医学类联邦学习研究,所使用的全球数据集是前所未有的。该项目使用了来自六大洲71个机构的数据,能够将脑肿瘤检测提高33%。
英特尔认为,由于美国各州和国家数据隐私法律(包括Health Insurance Portability and Accountability Act,HIPAA)的规定,长期以来数据可访问性一直是医疗领域面临的一个问题。由于HIPAA法案,在不损害患者健康信息的情况下,大规模的医学研究和数据共享几乎是不可能的。英特尔的联邦学习硬件和软件符合数据隐私问题,并通过机密计算保护数据完整性、隐私和安全性。
这次英特尔实验室和宾大医学院的研究涉及在分散式系统中处理大量数据,使用英特联邦学习技术与Intel Software Guard Extensions相结合,消除阻碍癌症和疾病研究等方面合作过程中存在的数据共享障碍。该系统通过将原始数据保存在数据持有者的计算基础设施中来解决数据隐私问题,并且只允许通过发送到中央服务器或聚合器的数据(而不是数据本身)进行模型更新计算。
该研究报告高级作者、宾大医学院病理学与检验医学和放射学助理教授Spyridon Bakas解释说:“在这项研究中,联邦学习显示了它作为范式转变的潜力,通过允许访问文献中考虑过的最大规模和最多样化的胶质母细胞瘤患者数据集,来实现多机构之间的合作,同时所有数据始终保留在每个机构内。我们输入机器学习模型的数据越多,模型就会变得越准确,这反过来可以提高我们理解和治疗罕见疾病例如胶质母细胞瘤的能力。”
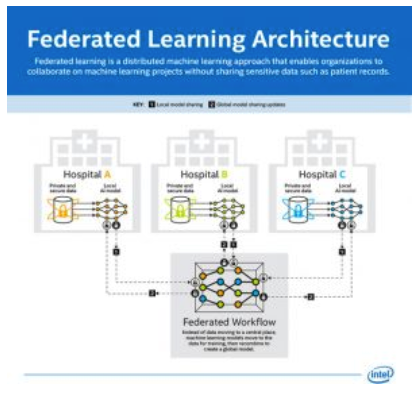
访问大量医疗数据(包括那些超过了数据生成阈值的数据集)是该技术的关键。这项研究证明了大规模联邦学习的有效性,以及释放多站点数据孤岛之后医疗行业可以实现的潜在好处。
英特尔的技术优势则体现在帮助及早发现疾病,改善生活质量或者延长患者的寿命。
英特尔实验室首席工程师Jason Martin说:“正如我们与宾大医学院的研究表明,联邦学习在众多领域具有巨大潜力,尤其是在医疗领域。联邦学习能够帮助敏感信息和数据,这为未来的研究和合作打开了一扇大门,尤其是在无法访问数据集的情况下。”
在完成这项研究之后,英特尔实验室和宾大医学院创造了一个概念证明,使用联合学习从数据中获取知识。该解决方案可以显着影响医疗和其他研究领域,特别是在不同类型的癌症研究方面。
好文章,需要你的鼓励


AI投资有望在2026年获得真正回报的原因解析
尽管全球企业AI投资在2024年达到2523亿美元,但MIT研究显示95%的企业仍未从生成式AI投资中获得回报。专家预测2026年将成为转折点,企业将从试点阶段转向实际部署。关键在于CEO精准识别高影响领域,推进AI代理技术应用,并加强员工AI能力培训。Forrester预测30%大型企业将实施强制AI培训,而Gartner预计到2028年15%日常工作决策将由AI自主完成。

清华团队让机器学会“透视眼“:用视频AI破解透明物体深度估计难题
清华团队开发DKT模型,利用视频扩散AI技术成功解决透明物体深度估计难题。该研究创建了首个透明物体视频数据集TransPhy3D,通过改造预训练视频生成模型,实现了准确的透明物体深度和法向量估计。在机器人抓取实验中,DKT将成功率提升至73%,为智能系统处理复杂视觉场景开辟新路径。

2026年软件定价大洗牌:IT领导者必须知道的关键变化
2026年软件行业将迎来定价模式的根本性变革,从传统按席位收费转向基于结果的付费模式。AI正在重塑整个软件经济学,企业IT预算的12-15%已投入AI领域。这一转变要求建立明确的成功衡量指标,如Zendesk以"自动化解决方案"为标准。未来将出现更精简的工程团队,80%的工程师需要为AI驱动的角色提升技能,同时需要重新设计软件开发和部署流程以适应AI优先的工作流程。

ByteDance推出全新混合专家模型训练法:让AI专家团队各司其职,大幅提升大语言模型性能
字节跳动研究团队提出了专家-路由器耦合损失方法,解决混合专家模型中路由器无法准确理解专家能力的问题。该方法通过让每个专家对其代表性任务产生最强响应,同时确保代表性任务在对应专家处获得最佳处理,建立了专家与路由器的紧密联系。实验表明该方法显著提升了从30亿到150亿参数模型的性能,训练开销仅增加0.2%-0.8%,为混合专家模型优化提供了高效实用的解决方案。
2022
12/06
13:34
分享
点赞

稚晖君发布全球最小全身力控人形机器人,上纬启元开启个人机器人时代
2026年软件定价大洗牌:IT领导者必须知道的关键变化
Linux 在 2026 年将势不可挡,但一个开源传奇可能难以为继
CES 2026趋势展望:全球最大科技展五大热门话题预测
人工智能时代为何编程技能比以往更重要
AI颠覆云优先战略:混合计算成为唯一出路
谷歌发布JAX-Privacy 1.0:大规模差分隐私机器学习工具库
谷歌量子AI发布新型优化算法DQI:量子计算优化领域的重大突破
缓解电动汽车里程焦虑:简单AI模型如何预测充电桩可用性
Titans + MIRAS:让AI拥有长期记忆能力
Gemini为STOC 2026大会理论计算机科学家提供自动化反馈
夸克AI眼镜持续升级:首次OTA,支持89种语言翻译
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
