
你笔下的诗,我们用AI帮你画出来
细说起来,AI应该是这几年最火爆的话题之一。在很多领域,AI已经可以部分取代之前只能由人类担任的工作,例如机器翻译有了AI加持后,译文的质量在很多场景下已经可以直接使用,但在艺术和绘画,这个体现人类独创性思维的领域,很难想象AI能和人类的想象力和手艺一较高下。
然而在2022年8月31日,这一“人类自信”似乎受到了挑战,由AI生成的画作《空间歌剧院(Théâtre D'opéra Spatial)》在美国科罗拉多州博览会的数字艺术类美术比赛中获得第一名。该奖项的授予引起很大争议,有人感叹“艺术的死亡在我们眼前展开”,也有人表示“凭借AI作品获奖并不能证明你就是艺术家”。对此,创作者表示自己并没有违反任何规则,提交作品时也标注出了所使用的AI绘画平台。两位评委事后更是表示不知道该标注指的是AI工具,但即使知道了也不会改变自己的选择。

图片AI生成画作《空间歌剧院(Théâtre D'opéra Spatial)》。
伴随着AI绘画工具的飞跃性发展,AI生成图片的质量和速度都有了显著提升。今年8月,AI绘画算法Stable Diffusion宣布开源,它生成速度极快,且具有较高的艺术性和观赏性,这更加使人怀疑:AI绘画是否会取代部分人类绘画?
虽然有此担忧,但是对于“把苍白的文字转为绚丽的图画”,这样的新鲜体验大部分人是不吝尝试的。国内外有不少科技公司都提供了这样的工具,为普通的“手拙党”提供一次妙笔生花的机会,也通过AI绘图的联想为专业绘图设计师提供更多的设计灵感。基于此,近期UCloud优刻得的GPU云主机也上线了AI绘画stable diffusion平台,在UCloud控制台创建GPU云主机时,在镜像市场选择“AI绘画stable diffusion平台”镜像,然后点击【立即创建】,机器创建成功之后,连接GPU云主机,就已完成所有前期配置。然后输入您心中的描述,例如:“A dream of a distant galaxy, by Caspar David Friedrich, matte painting trending on artstation HQ”,执行一下prompt命令,AI即可输出您心中“设计”的图片,示例图片如下:


(更多详细操作步骤见附录)
苏轼评王维诗曾言:“味摩诘之诗,诗中有画,观摩诘之画,画中有诗”。中国古典审美特别强调“诗情”与“画意”完美融合。对于一部分朋友们来说,心中纵有万千美景,无奈手拙难画一线,只能凝缩于几行文字,无法通过美妙的图片直抒胸臆,而AI绘画平台恰好提供这个工具。细想一下:“远看山有色,近听水无声”如果通过图片展示,应该也是一副赏心悦目的图卷吧。
也许Stable Diffusion目前还不能作为生产力工具,但不可否认,它让设计变得简单,也为设计方式带来更多多样化元素,让普通人打开了 AI 绘画的可能性。所以我们推荐大家实际部署玩下,让自己拥有更多的可能!
附录:UCloud的GPU云主机的AI绘画stable diffusion平台实践手册
体验步骤
1.创建一台GPU云主机
创建GPU云主机时,镜像选择“AI绘画stable diffusion平台”,操作路径:镜像市场——>AI绘画stable diffusion平台,便捷安装stable diffusion,镜像内置环境:CentOS 7.8。
推荐机型:GPU型云主机 T4S、V100S、P40
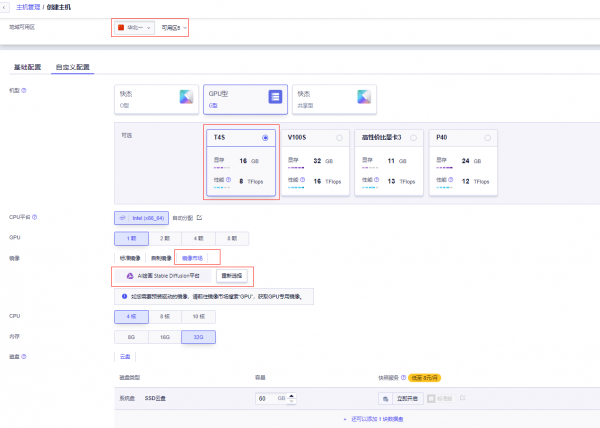
说明:
内存请选择32GB及以上,否则模型加载时可能会触发OOM。
绑定EIP并在外网防火墙放行TCP 8888端口。
2.虚机内部启动jupyter
nohup jupyter notebook &
目的在于后续可以在web页面浏览生成的图片,也可在web页面直接编写python交互式程序。
若需要开机自启,可以自行通过rc.local或systemctl配置。
3. 使用stable diffusion
3.1 方式一:使用stable diffusion的sample script
3.1.1 切换conda环境
conda activate ldm
3.1.2 执行sample脚本
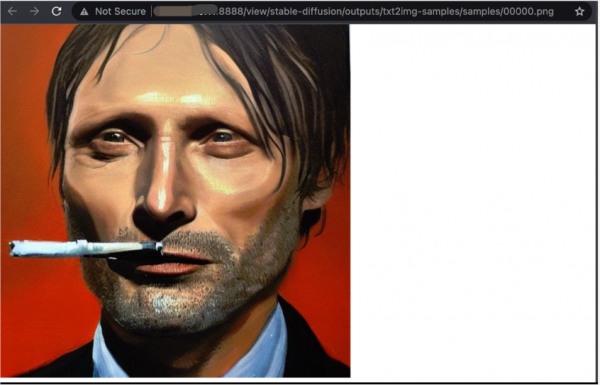
执行脚本,输入您预想图画的描述,即可得到图片(以下以“a painting of Mads Mikkelsen smoking”为例),生成的图片在 /root/stable-diffusion/outputs/txt2img-samples/目录下。
cd stable-diffusion
python scripts/txt2img.py --rompt "a painting of Mads Mikkelsen smoking"
3.1.3 使用jupyter页面查看
根据外网ip地址,访问http://EIP:8888img
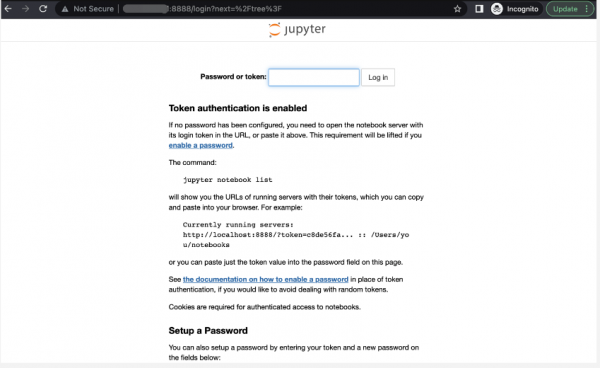
输入token(在/root/.jupyter/jupyter_notebook_config.py中查看c.NotebookApp.token的配置,可自行修改。)
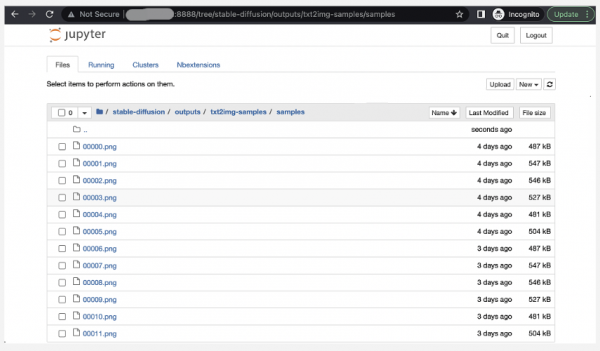
根据导航点击预览图片。
3.2 方式二:使用stable diffusion的lib
3.2.1 切换到指定目录
cd /root/demo
CopyErrorSuccess
3.2.2 执行python test.py
需确保在ldm的conda环境中运行。
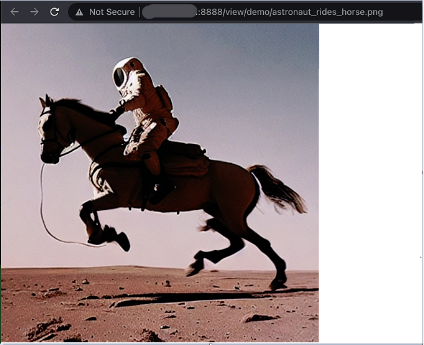
以下以生成图片“astronaut_rides_horse.png”为例做演示。
test.py
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"./stable-diffusion-v1-4").to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt)["sample"][0]
image.save("astronaut_rides_horse.png")
3.2.3 使用jupyter页面查看
来源:业界供稿
好文章,需要你的鼓励


数据中心最新动态:2026年7月
全球数据中心建设需求持续高涨。北美方面,美国数据中心建设支出年化达510亿美元,微软在威斯康星州开放33亿美元设施,亚马逊和谷歌宣布在密苏里州合计投资250亿美元。欧洲方面,SoftBank将在法国建设5GW AI数据中心,投资额达750亿欧元。亚太地区,AirTrunk计划在印度投资210亿美元建设3GW数据中心。中东与非洲地区也有多项大规模项目落地。

当AI做“陪练老师“:弗吉尼亚理工大学等机构用大模型的“解题日记“预测考题难度
这项研究提出Epi2Diff方法,通过将大型推理模型的解题思考过程拆解为认知片段序列,提取过程特征预测考题对人类的难度,在四个真实考试数据集上超越了所有对比基线。

企业如何在边缘端与云端之间合理分配AI算力
随着企业将AI融入机器人、工业设备等物理基础设施,边云协同架构正成为关键课题。以Luminous Robotics和先正达为例:前者在太阳能农场部署的机器人每秒做出10次决策,数据定期上传云端持续优化模型;后者通过Cropwise平台整合卫星、无人机、拖拉机传感器数据,辅助农民完成约150项农业决策。两家公司均强调,边缘端负责实时响应,云端负责模型训练与更新,同时保持人工监督以确保安全与准确性。

南京大学联手阿里巴巴:让AI图像生成变得更“聪明“,一个让图像生成模型真正理解画面的新框架
南京大学与阿里巴巴提出MIMFlow,将掩码图像建模与标准化流端到端融合,让生成模型专注语义建模,以更少参数和更少令牌在ImageNet上取得FID 2.50的优异表现。

