
DeepStream-13:结合IoT信息传输
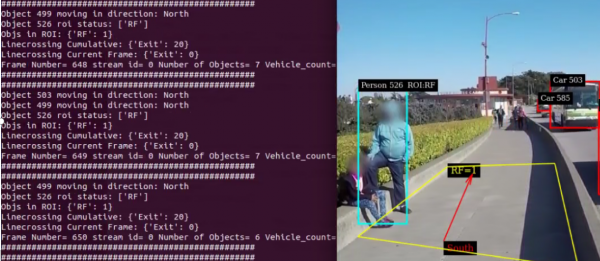
前一篇文章特别介绍DeepStream的nvdsanalytics视频分析插件,能对视频中特定的多边形封闭区域或是某条界线,在“某时间”的动态分析与“某时段”的累积统计数据,甚至包括行进方向的物件统计等等,下图就是nvdsanalytics插件范例的执行结果,图左显示非常多的动态信息,十分强大。
既然nvdsanalytics插件已经帮我们将视频内容转化成字符信息,接下去的重点就是将这些信息上传到一个数据汇总的服务器,这样就能完成一个IoT应用的完整循环。为了实现这样的目的,DeepStream从3.0就提供nvmsgconv与nvmsgbroker这两个插件,分工合作来完成这项信息传递的任务。
本文的范例是deepstream-python-apps下面的deepstream-test4,里面的插件流与前面的几个范例的流程大致相同,因此这里不花时间在插件流部分多做说明,除了最后面的“tee”插件对信息做分流的处理,其余部分都是前面范例中已经详细讲解过的内容。简单整理一下本范例的插件流顺序给大家参考一下,如下所示,:
filesrc -> h264parse -> nvv4l2decoder -> nvstreammux -> nvinfer -> nvvideoconvert -> nvdsosd -> nvmsgconv -> nvmsgbroker -> tee -> queue -> nveglglessink
tee这个Gstreamer开源插件将信息交给nvmsgconv/nvmsgbroker这两个插件去处理与传递,另一个分流则让数据能在本机上的显示器上输出视频画面。
本范例最重要的任务,在于让大家进一步了解并熟悉nvmsgconv与nvmsgbroker的内容与用法,并没有执行nvdsanalytics的视频分析功能,所有重点都聚焦在“信息传送”的插件本身,与前后台设备的部分。
现在就开实验的内容部分。,
- nvmsgconv插件
这个插件的功能就是将前面检测到并存放在缓冲区的信息抽取出来,这是透过插件输入端的Gst buffer、NvDsBatchMeta与NvDsEventMsgMeta带进来(如下图),定义一个用户元数据(user_event_meta,在代码第301行),将base_meta.meta_type设为NVDS_EVENT_MSG_META数据类型,生成的有效负载(NvDsPayload)再以NVDS_PAYLOAD_META类型据附加回输入缓冲区,然后再用pyds.user_copyfunc将数据复制过来就可以。
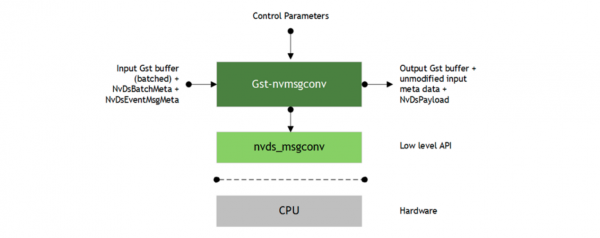
在DeepStream 5.1里的nvmsgconv插件有两种工作模式:
- 完整模式:这是系统默认的工作方式,会以JSON格式生成有效负载,对象检测、分析模块、事件、位置和传感器,提供所有与有效负载相关的单个对象的信息。
- 最小变化量模式:只记录枪后之间的最小变化量,这使得传输到nvmsgbroker插件的信息量最小化,每个有效载荷可以具有帧中多个对象的信息
- nvmsgbroker插件
这个插件的任务,就是将nvmsgconv传送过来的有效负载数据,透过所支持的转接器(adapter)协议上传到指定的接收器去。目前DeepStream 5.1支持Kafka、AMQP与Azure IoT三种转接协议。

本范例使用Kafka这个协议来做示范,至于另外两种协议,在范例目录下也提供参考的配置文件,可以之间进行修改就行。
- 执行范例:请在DeepStream 5.1版本中运行
整个deepstream-test4.py代码结构与deepstream-test1.py差不多,所以代码内容就不花时间讲解,如果有不了解的请参考前面文章的内容。
这个范例有个比较特别的部分,就是需要有“信息产生设备”与“信息接收设备”两部分,当然这两个设备也可以使用同一台来扮演。
为了便于操作,接下来的演示我们将二者都放在同一台Jetson Nano 2GB上执行,但逻辑上将它视为两个设备:
- 信息接收设备:执行 ZooKeeper、Kafka Server、建立test4话题
- 下载Kafka安装包并解压缩:
|
# 在信息接受设备上,这里用Jetson Nano 2GB wget -c https://mirror-hk.koddos.net/apache/kafka/2.8.0/kafka-2.8.0-src.tgz tar -xzf kafka-2.8.0-src.tgz cd kafka-2.8.0-src |
- 启动ZooKeeper服务器:
由于Kafka需要ZooKeeper来进行管理,因此在启动Kafka服务之前,必须先启动ZooKeeper作为后台管理,还好Kafka已经提供可执行的脚本与配置,就不需要额外再下载与编译ZooKeeper。
在启动ZooKeeper之前,还得先为其建立相关的Java数据库,因此这里有几个步骤需要执行:
|
# 开启一个Terminal # 安装 Java 开发包与 curl 下载工具 sudo apt install -y openjdk-8-jdk curl # 建立数据库,大约10分钟时间,可能因为 Java 版本而出错,卸掉 > 8 的版本 ./gradlew jar -PscalaVersion=2.13.5 # 启动 ZooKeeper 服务器, bin/zookeeper-server-start.sh config/zookeeper.properties |
- 启动Kafka服务器,并建立一个名为“test4”的话题(topic):
因为这里使用Jetson Nano 2GB作为Kafka接收器,因此后面的<IP:端口>设置为“localhost:9092”,下面指令的粗体部分内容,必须与后面发送端的“--conn-str=<IP;PORT;TOPIC>内容一致。
|
# 开启第二个 Terminal,启动Kafka服务器 bin/kafka-server-start.sh config/server.properties # 开启第三个 Termianl,创建 test4 话题 bin/kafka-topics.sh --create --topic test4 --bootstrap-server localhost:9092 |
- 启动Kafka的test4话题,执行“接收(consumer)”功能:这里的TOPIC、IP、端口也必须与上面指令是一致的。
|
# 使用第三个终端,启动对话的“接收(consumer)”功能 bin/kafka-console-consumer.sh --topic test4 --from-beginning --bootstrap-server localhost:9092 |
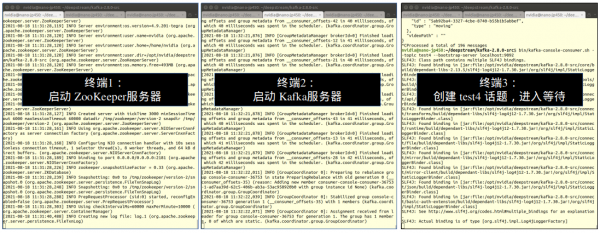
现在Kafka接收器的三个服务都已经处于如下图的接收信息状态:
- 信息发送端:deepstream-test4范例执行设备
- 安装依赖库:在deepstream-test4范例目录下有个README文件,请根据您要使用的通信种类(Azure IOT、Kafka、AMQP)安装依赖库。
这里使用Kafka通讯协议,就清在工作机(Jetson Nano 2GB)上执行以下步骤:
|
# 安装依赖库 sudo apt install -y libglib2.0 libglib2.0-dev libjansson4 libjansson-dev sudo apt install -y librdkafka1=0.11.3-1build1 # 由于执行过程需要 Gst RTSP 服务器,因此得先安装以下的依赖库 sudo apt install -y libgstrtspserver-1.0-dev |
- 执行范例:
执行deepstream-test4.py需要提供以下几个参数:
-i <H264 视频文件>:指定的视频文件,这里只接受一个输入
-p <Proto转接器的库>:这里指定到deepstream/lib/libnvds_kafka_proto.so
--conn-str=<接收器的IP;端口;话题名称>:这里用本机作为接受端,因此IP用“localhost”,端口使用“9092”,话题名称与前面必须对应,使用“test4”,如此这部分的内容为 --conn-str="locolhost;9092;test4"
-s <0/1>:这里选择使用完整表示或简单表示的选项
接下来就算在发送端执行以下指令:
|
# 到 deepstream-test4 工作目录,由于路径过长,因此分两次处理 cd /opt/nvidia/deepstream/deepstream/sources/deepstream_python_apps/ cd apps/deetstream-test4 # 在本目录下建立视频文件与调用库的链接 ln -s ../../../../samples/streams/sample_720p.h264 test.h264 ln -s ../../../../lib/libnvds_kafka_proto.so libnvds_kafka_proto.so # 执行代码 python3 deepstream_test_4.py -i test.h264 -p libnvds_kafka_proto.so \ --conn-str="localhost;9092;test4" -s 1 |
注意这里--conn-str=后面的参数,必须与接收端的设定值一致。最后面的-s参数是选择使用完整信息模式还算简易信息模式。
如果出现“unable to connect to broker library”错误信息,表示没找到 kafka Server,请检查接收端三个服务的状态。
如果一切都调试好,执行后会出现下面状态,左边是用deepstream-test4.py执行推理计算,将信息传送到右边的接收器去进行显示:
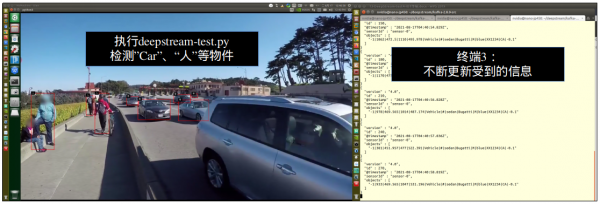
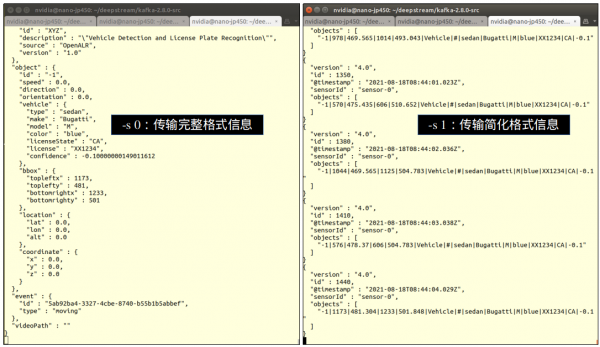
用-s选择传送不同格式的信息,“0”表示使用完整格式(如下图左),“1”则选择简化格式(如下图右),这样就完成IoT信息传送的应用了。
在deepstream-test4.py只调用基础的2类别物件检测器,我们可以自行尝试将deepstream-nvdsanalytics.py与这个范例相结合,就能开发出一个实用性非常高的“AI-IOT视频分析”应用。《完》
来源:业界供稿
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2021
12/07
11:34
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
分析:NVIDIA第二季度财报再次超出预期背后的新问题
释放海量数据新价值,打造智能座舱新体验
Jetson百万开发者故事 | 校企合作推动实现多项工业场景下AI边缘计算应用
华为全屋智能即将惊艳亮相AWE,引领空间智能化新浪潮
Jetson百万开发者故事 | NVIDIA Jetson助力水产养殖企业打造自动化流水线
Jetson百万开发者故事 | 基于Jetson Nano的便携式岩石分类检测系统:地质学家的新利器
Jetson百万开发者故事 | 让AI成为铁路客运站自动扶梯安全管控的关键
Jetson百万开发者故事 | Jetson开发者突破百万,从TK1到Orin我都经历了啥
百万Jetson开发者故事
Jetson百万开发者故事 | NVIDIA Jetson如何成为可移动智能脑机交互平台
