
AI基准测试MLPerf推理V1.1发榜 浪潮获15项冠军蝉联榜首
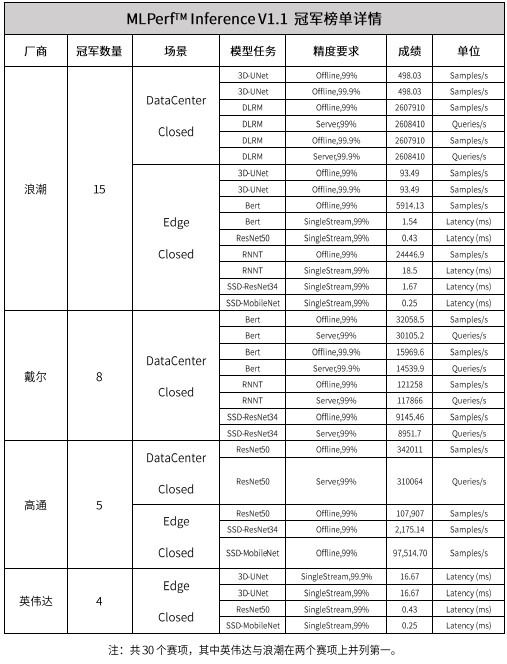
9月23日,全球权威AI基准评测MLPerf™公布最新榜单Inference(推理) V1.1,在最受关注的固定任务(Closed)测试中,浪潮获得15项冠军,戴尔、高通、英伟达分别获得8项、5项和4项冠军。
MLPerf™是影响力最广的国际AI性能基准评测,由图灵奖得主大卫•帕特森(David Patterson)联合顶尖学术机构发起成立。2020年,非盈利性机器学习开放组织MLCommons基于MLPerf™基准测试成立,其成员包括谷歌、Facebook、英伟达、英特尔、浪潮、哈佛大学、斯坦福大学、加州大学伯克利分校等50余家全球AI领军企业及顶尖学术机构,致力于推进机器学习和人工智能标准及衡量指标。目前,MLCommons每年组织2次MLPerf™ AI训练性能测试和2次MLPerf™ AI推理性能测试,为用户衡量设备性能提供权威有效的数据指导。
MLPerf™推理V1.1 AI基准测试固定任务(Closed)包括数据中心(共16个项目)和边缘(共14个项目)两大场景。在数据中心场景下设置6个模型,分别是图像识别(ResNet50)、医学影像分割(3D-UNet)、目标物体检测(SSD-ResNet34)、语音识别(RNN-T)、自然语言理解(BERT)以及智能推荐(DLRM),其中Bert、DLRM和3D-Unet设有高精度(99.9%)模式。除3D-UNet模型任务只考察Offline离线推理场景性能外,其他模型任务按照Server在线推理和Offline离线推理两种应用场景分别进行性能测试。边缘场景AI模型在数据中心场景的6个模型基础上删减了智能推荐(DLRM)模型,并增加目标物体检测(SSD-MobileNet)模型,所有模型均有Offline离线推理场景和SingleStream单流推理两个场景。
固定任务(Closed)要求参赛各方使用相同模型和优化器,这对于实际用户评测AI计算系统性能具备很强的参考意义,也一直是MLPerf™中角逐最激烈及主流厂商最关注的领域。此次共有英伟达、英特尔、浪潮、高通、阿里巴巴、戴尔、HPE等19家厂商参与到固定任务(Closed)测试竞赛中,其中数据中心场景收到了754项成绩提交,边缘场景收到了448项成绩提交,共1199项成绩提交。
在固定任务的全部30个项目中,浪潮获得15项冠军,位居冠军数量第一,这也是浪潮连续第四次位居MLPerf™ AI基准测试冠军数量榜首。
此次MLPerf™的开放任务(Open)赛道允许参赛方对模型进行任意处理,参加者有cTuning、Krai等6家厂商,数量较上届有下降。此外,本次MLPerf™还共有NVIDIA、浪潮、高通以及戴尔等5家厂商在功耗任务上提交了结果,功耗评测或将成为未来MLPerf™的关注重点之一。
来源:业界供稿
好文章,需要你的鼓励


三祥科技拟1100万美元购入美国代顿厂房,汽车流体管路向液冷与悬架延伸
今天讲的出海案例是三祥科技,这家汽车流体管路厂商拟由北美子公司出资1100万美元,购买美国俄亥俄州代顿工业厂房。

英伟达让AI画图学会“改稿“——一种让图像生成模型懂得自我纠错的新技术
英伟达NLD-Image通过词条编辑机制和分组交叉熵目标,解决了掩码离散扩散模型无法自我纠错及大词典训练困难两大核心问题,实现了高分辨率图像生成的速度与质量双突破。

斯巴鲁新款电动SUV销量已超越Solterra
斯巴鲁今年推出了两款全新电动SUV——Trailseeker和Uncharted,上市仅数月便已超越老款Solterra的销量。2026款Solterra也经历大幅升级,续航提升至288英里,新增14英寸触控屏及电池预热系统,寒冷天气下可在35分钟内从10%充至80%。Trailseeker起售价39,995美元,功率达375马力,可拖拽3,500磅;Uncharted起售价34,995美元,定位更紧凑运动。三款车型均基于斯巴鲁与丰田的合作平台开发。

清华大学如何用“海量免费截图“训练出媲美顶尖AI的电脑操作助手?
清华大学提出GUICrafter,通过自动提取网页交互信号代替人工标注,用不到竞争对手千分之一的数据量,训练出性能相当甚至更优的GUI操作智能体。
2021
09/23
09:30
分享
点赞

三祥科技拟1100万美元购入美国代顿厂房,汽车流体管路向液冷与悬架延伸
烛光映红土,科技启童心——中国电子学会科技志愿服务活动江西行
斯巴鲁新款电动SUV销量已超越Solterra
SpaceX疑似向投资者展示AI手持设备原型,马斯克否认
Meta计划对外出租AI基础设施,股价大涨近9%
Instagram算法定制功能升级,用户可更精准掌控内容偏好
AI时代Chiplet设计中不可或缺的可观测性层
从传统CRM迈向智能化客户互动的转型之路
Wonder与Zipline合作,无人机送餐服务将于2027年在德克萨斯州上线
无人机卫星通信突破:轻量化终端助力野火响应
Google承认AI发展速度已超过电网脱碳速度
欧盟拟将AWS和Azure列为数字市场"守门人"
