
CPU、GPU、FPGA、AI芯片,各种XPU哪家强?一篇文章看懂芯片产业格局 原创
2021年开年虽然业界面临“缺芯”问题,但是众多半导体厂商的新品发布却是此起彼伏,“你方唱罢我登场”。
……
GTC 2021上,英伟达宣布进军CPU,实现CPU、GPU、DPU“3U一体”
英特尔发布用于数据中心的第三代至强可扩展处理器Ice Lake以及其产品组合
AMD EPYC进化到代号“米兰”的第三代
Arm 发布最新一代架构Arm v9,更早些时候Arm推出了面向数据中心的Neoverse平台
……
一时间,原本泾渭分明的数据中心芯片市场变得错综复杂,XPU(CPU、GPU、DPU等各种服务器处理器的统称)成为半导体芯片厂商竞争的新赛道,一条清晰的竞争主线也逐渐明显——各大芯片企业都在构建自己的多元化产品能力。
半导体巨头们围绕XPU展开了积极布局的同时,在市场驱动下,各个细分领域的XPU厂商也纷纷发力,APU、TPU、IPU等各种加速芯片百花齐放,地平线、寒武纪、中科驭数等厂商涌现。特别是在外部断供以及国产化趋势下,国产厂商也迎来发展契机,比如龙芯、飞腾、鲲鹏等在积极构建产品与技术生态。
算力就是生产力
面对层出不穷的XPU,站在更为宏观的视角看,这已经不简单只是厂商之间的技术、产品、市场之争,其背后代表了一种对先进生产力之间的追逐。
人类社会每一次科技跃迁,其本质都是计算力的突破与进化,每一次新文明的进阶,都是计算方式和载体变迁带来社会效率提升的结果。如果说在工业时代电力是基础设施,是经济社会发展的动力保障,那么,随着人类社会迈入数字经济时代,算力正在扮演相似角色。
根据中国信息通信研究院今年发布的《中国数字经济白皮书》,2020年中国数字经济规模达到39.2万亿元人民币,占GDP比重为38.6%。数字经济的基础是对数据进行处理,也就是利用大大小小各种规模的数据中心——从几十台服务器的小规模数据中心到几十万到上百万台规模的超大型数据中心提供的算力,运行各种软件来提供各种服务以支撑企业的生产经营和消费者的各种消费服务。由于计算力的大小代表了对数据处理能力的强弱,因此,计算力自然成为数字经济的核心要素,是核心生产力。
IDC发布的《2020全球计算力指数评估报告》也表明,计算力与经济增长紧密相关,计算力指数平均每提高1个点,数字经济和GDP将分别增长3.3‰和1.8‰。
当前,各个国家的数字经济占比将持续提升,而数字经济和算力需求处于循环增强的状态,同时,新兴技术的投入与算力投入相关性极高,算力为新兴技术应用提供基础保障,新兴技术的发展进一步推动算力提升,其中物联网、人工智能和大数据的相关性最为显著,新兴技术和算力呈现相互拉动效应。
正是看到了算力在数字经济发展中的重要作用,全国一体化算力网络国家枢纽节点建设也于近期正式启动,其将成为中国数字经济发展的新基座。
总之,算力不仅仅是一个技术指标,而是先进生产力的代表。未来,算力与数字经济共促共进的关系将进一步强化:即算力不断发展推动数字经济持续向前,数字经济持续向前加重对算力的支撑依赖,“算力经济时代”正在到来。
计算场景多样化催生XPU
站在产业格局看,芯片厂商令人眼花缭乱的市场活动背后是它们对数据中心市场的野心,而这野心又归结为看上计算场景的复杂多元化带来的市场机会。
从超算系统到桌面到云到终端,都离不开各种不同类型指令集和体系架构的计算单元,如CPU、GPU、DSP、ASIC、FPGA等。由于各种不同的处理器采用不同的架构和不同指令集使得它们在处理具体计算场景是有着不同的表现,导致计算多元化的出现。
比如,GPU芯片是单指令、多数据处理,采用数量众多的计算单元和超长的流水线,主要处理图像领域的运算加速;FPGA适用于多指令,单数据流的分析,可提供强大的计算力和足够的灵活性;ASIC是为实现特定场景应用要求时,而定制的专用AI芯片,在功耗、可靠性、体积方面都有优势,尤其在低功耗的移动设备端,基于以上优势,ASIC芯片更多的用于端或边缘侧。
其实,计算多元化是早已有之,比如x86取代IBM Power、HP PA-RISC、Sun SPARC成为数据中心霸主。但是随着深度学习崛起,GPU受到重视,在数据中心呈现出强劲的增长趋势。同时,Arm服务器、RISC-V的崛起,又使得数据中心开始了新的多元化进程。
芯片多元化的背后是应用场景的复杂化导致通用计算技术和通用芯片越来越不能满足业务需求,特别是新涌现的计算场景对于计算芯片指令集、架构的要求是不一样的,这样就导致之前一直使用的通用CPU已经无法满足多元化计算场景要求,这也是计算芯片的种类越来越多的重要原因,而CPU+GPU、CPU+FPGA、CPU+GPU+FPGA等组合效能更好,通用计算被迫向异构计算演进。
比如,海量数据的处理需要更高密度的计算能力,而通用计算在效能上明显不能满足要求。一方面,采用通用处理器需要更多处理器,成本高昂;另一方面,更多处理器带来更高发热,带来了更多的制冷需求,这些最终都指向了高成本,而在某些场景下(如一些人工智能)GPU、FPG比CPU具有更高的性价比,而在一些细分的人工场景下AI专用芯片比GPU、FPG的表现还要优异,比如IPU处理稀疏矩阵的数据类型时效能就有明显优势。
芯片种类多的另外一个原因是芯片代工模式的普及,现在芯片设计、制造的关键环节都有开源开放的软件、工具或代工企业可以利用,例如RISC-V,这也推动了更多创新厂商切入芯片领域。
腾讯云异构计算研发副总监宋吉科认为,异构计算崛起的主要原因两个:人工智能类应用的崛起,工作负载类型多样更加多样化,对应芯片架构需要量身定制;从互联网到移动互联网,芯片产业的供应链也在发生变化,特别是Arm的IP设计模式,推动了台积电等代工厂在制程工艺上的快速发展,从而各种Fabless(IC设计)芯片厂商有了更多的市场机会。
在计算产业变革的背景下,“CPU包打天下”一去不复返,异构计算即XPU的发展成为大势所趋。我们看到众多头部半导体厂商推出多元化的芯片产品,不断延展业务边界,而创新公司也不示弱,它们在没有历史包袱的情况下,纷纷针对不断涌现的业务场景推出了专属性的芯片产品,让整个芯片市场迎来“百家争鸣”时刻。
x86市场的“混战”
在当今XPU市场,通用计算芯片占据的市场份额和市场需求量是最大的,毕竟作为“全能选手”,不管是x86还是Power或者Arm,它们的计算生态也是最为成熟的,相关的技术产品也在持续迭代,上演了x86、Power、Arm通用计算市场的“三国杀”,甚至于我们如果用白热化来形容当前的x86市场,也一点也不为过。毕竟作为最成熟的计算架构,x86伴随着半导体产业的成长,特别是英特尔与AMD近期新品的发布更是让x86市场平添了很多“火药味”。
在数据中心市场,英特尔是毫无争议的带头大哥,英特尔CPU在数据中心市场处于垄断地位。据英特尔2021年第一季度业绩显示,第三代英特尔至强可扩展处理器出货量超过20万颗。
同时,阿里云、平安科技、腾讯云等英特尔生态伙伴已经基于第三代至强可扩展平台开展了诸多实践,比如在腾讯游戏的3D人脸建模中,借助第三代英特尔至强可扩展处理器的VNNI技术,可以加速4.24倍以上,这意味着原有基于3D人脸建模的各种优化、缓存、预处理环节可以直接跳过,直接提供照片就能够生成3D模型。
在用户端,第三代英特尔至强可扩展处理器也赢得了众多互联网企业的青睐,例如快手与英特尔展开合作,结合英特尔至强可扩展处理器平台和傲腾持久内存,快手推荐系统的性能得到大幅提升,同时也能支持更多复杂算法,总拥有成本(TCO)降低了30%。
虽说英特尔至强的市场地位如此坚固,但是随着异构计算的崛起,英特尔感受到了来自GPU、FPGA的强力挑战。为了应对这些挑战,近些年英特尔调整了市场战略,不再以处理器为中心,而是以数据为中心,这体现为从CPU到XPU、从芯片(Silicon)到平台、从传统IDM到现代、更灵活的IDM。特别是在IDM 2.0的愿景中,英特尔在代工业务中以更加开放心态支持X86内核、ARM、RISC-V生态系统、IP的生产。
英特尔中国研究院院长宋继强表示,异构集成是推动摩尔定律继续发展的重要方式。英特尔转型为包含多种计算架构XPU的公司,并在此基础上推出了适配的软件,并构建相应的生态,引领异构计算的发展。
如果说英特尔采取了大而全的策略,以产品组合赢得整体优势,比如第三代英特尔至强可扩展处理器与英特尔傲腾内存存储解决方案、英特尔以太网连接解决方案等共同组成的以数据为中心的产品组合才是英特尔的王炸,那么AMD则是重点突破,以点带面。
虽然同为x86市场的缔造者,但长期以来AMD是作为英特尔的陪衬存在,尤其是在服务器市场几乎没有多少存在感。AMD自然不甘心,先后发起了多次挑战,而近几年AMD在数据中心芯片的进步业界有目共睹。特别是第三代AMD EPYC处理器在技术领先性方面做足了文章,为行业带来了诸多改变,比如性能、成本、生态等。
AMD总裁兼CEO苏姿丰(Lisa Su)说,数据中心处于发展进化过程中,单一产品无法满足数据中心的需求,AMD能够提供具有融合、匹配数据中心需要的各种IP的能力。
自EPYC(霄龙)处理器问世以来,AMD与众多合作伙伴展开密切合作,截止到今年,将推出超过100款服务器产品及400多个实例,几乎涵盖了所有的应用场景和解决方案。
例如在超算领域,AMD EPYC处理器支持的超级计算机已经在全球高性能计算TOP 500强榜单中占据多席,并为斯图加特高性能计算中心的HLRS “HAWK”、德国天气预报服务公司(DWD)的NEC SX-AURORA TSUBASA、苏黎世联邦理工学院(ETH Zurich)的ETH ZURICH EULER VI、圣地亚哥超级计算机中心(SDSC)的DELL EXPANSE、英国国家研究创新局(UKRI)的CRAY ARCHER2、法国国家高性能计算组织(GENCI)的JOLIOT-CURIE等等超算系统提供服务。
此外,AMD公司与美国橡树岭国家实验室(ORNL)和Cray公司联合打造Frontier,其基于下一代AMD EPYC霄龙处理器、Radeon Instinct加速卡、ROCm异构计算软件三大平台,运行峰值可达每秒1.5exaflops(百亿亿次),是实验室有史以来打造的性能最强的超级计算机。
基于此,2020年Q4季度 Mercury Research的报告中AMD在服务器CPU市场份额达到了7.1%,今年Q1季度进一步增长到了8.9%。
如今芯片厂商不光在制程工艺上进行迭代,还在封装工艺上持续创新。比如英特尔推出了EMIB技术和Foveros技术,其中EMIB是一种高密度的2D平面式封装技术,可以将不同类型、不同工艺的芯片IP灵活地组合在一起,类似一个松散的SoC;Foveros技术首次为处理器引入了3D堆叠式设计,是大幅提升多核心、异构集成芯片的关键技术,可以实现芯片上堆叠芯片,而且能整合不同工艺、结构、用途的芯片。
而在Computex 2021上,AMD宣布将Chiplet封装技术与芯片堆叠技术相结合,为未来的高性能计算产品创造出了3D Chiplet架构。这项封装技术突破性地将AMD创新芯片架构与3D堆叠技术相结合,并采用了业界领先的混合键合方法,与现有的3D封装解决方案相比,可提供超过200倍的2D芯片互连密度和15倍以上的密度。通过与台积电(TSMC)紧密协作,与目前的3D解决方案相比,这项行业前沿的技术能耗更低,是世界上超灵活的活性硅堆叠技术。
如上所述,我们看到当前x86市场的竞争程度更加激烈,虽然市场格局没有太大的变化,但是市场情绪也在慢慢变化。所以不管是英特尔还是AMD,唯有技术创新,匹配用户需求,紧跟时代要求,才能在市场中立于不败之地。
Power和Arm发起挑战
在通用计算领域,用“傲视群雄、睥睨天下”来形容x86处理器一点儿也不过分,但这并意味着其他类型处理器就甘拜下风,比如Power和Arm就向x86处理器发起了强力挑战,近年来不管是Power还是Arm都一直在不断进化,为用户提供了多样化的选择。
对于Power,如果是业界资深人士,一定会有一种历史感涌上心头。虽然被x86压制,但是Power的生命力还是非常强大的,也在持续迭代。毕竟在存量市场上Power还是有很强的优势,很多Power承载的都是关键行业的核心和关键业务。
实际上,Power从来就没有甘心把霸主之位拱手相让于x86,重新昔日荣光的梦想虽然有些遥远,但并没放弃。目前Power处理器已经迭代到采用7nm工艺的Power10,并广泛应用于IBM主机产品和Power服务器产品,而在国内,浪潮商用机器作为POWER中国区独家代言人,承担起了重振Power雄风的重任。浪潮商用机器在不断拓展Power架构的创新应用,让Power在当今计算架构市场有着一席之地。
Power架构主打关键计算,面向关键应用核心云承载平台、关键业务主机、云原生创新型应用。这也是其与x86区别客户定位的重要特征。比如,浪潮K1 Power产品线就主打高可靠性、高性能、高安全和数据强实时一致性的“三高一强”特性,致力于打造关键应用的高可靠和高性能的安全平台。
浪潮商用机器有限公司总经理胡雷钧表示,作为一种纵向扩展系统,在支撑核心应用系统方面,K1 Power的性价比最高,是最可靠的技术选择。同时,围绕POWER处理器的国产化,浪潮商用机器提供了面向关键应用系统的丰富产品。
如果说Power是高大上,那么我们对Arm架构的认知则是从移动终端开始的。ARM处理器架构开启了移动时代,而且过去五年基于Arm架构的设备出货量超过1000亿,其影响力已经遍布移动终端。但是现在Arm架构也在“出圈”,这要从Arm v9架构谈起。
Arm v9架构基于Arm v8,并增添了针对矢量处理的DSP、机器学习、安全等技术特性。
众所周知,由于高能效、低功耗等特点,Arm在移动设备和物联网市场得到广泛应用。其实在基础设施领域,Arm已经耕耘超过10年,并推出了专门面向数据中心的服务器芯片架构Arm Neoverse,在HPC、云计算以及5G等市场取得了不俗的成绩,不仅在AWS有Graviton以及Graviton2这样的芯片正式投入商用,Oracle也已经宣布计划将Ampere Altra用于其云基础设施,而在HPC领域,不仅有世界最快超级计算机日本富士通Fugaku这样的用户,而且印度也宣布研发基于Neoverse的超级计算机。
凭借合作伙伴生态系统和商业模式,Arm架构已经在云、管、边、端等场景中无处不在。新的Arm v9架构的推出也是Arm瞄准下一个计算革命的诚信之作,必将在未来多云化的计算市场闯出更为广阔的天地。
加速计算的“黄金时代”
虽然通用计算是主流,并会在未来相当长一段时间内作为一种成熟稳定、发展缓慢的技术而存在。但是不管是GPU还是FPGA等加速芯片也正在迎来自己的黄金时代。
IDC发布的《中国半年度加速计算市场(2020下半年)跟踪》报告显示,2020年加速服务器市场规模达到32.0亿美元,同比2019年增长52.8%。其中GPU服务器依旧占主导地位,拥有86.3%的市场份额,市场规模达到27.6亿美元,同比增长37.3%。同时FPGA等非GPU加速服务器以434.0%的增速占有近15%的市场份额,市场规模达到4.4亿美元。
在GPU市场,英伟达是毋庸置疑的王者,但是英伟达并没有局限于GPU,宣布收购Arm之后,英伟达将自身的触角伸向了CPU、DPU等XPU领域。
我们知道GPU是英伟达的“主业”,但是凭借一系列的收购,英伟达也在向其他XPU拓展,在GTC 2021大会上,英伟达推出了CPU、DPU和GPU的”组合拳“,帮助用户打造完全可编程的单一AI计算单元。
前面我们谈到在云计算、企业和边缘数据中心、超级计算、PC等其他市场中,Arm也开始崭露头角。而依靠收购Arm,英伟达与Arm之间的协同有了更多想象空间,比如英伟达的DPU(Data Processing Unit,数据处理单元)就内置了Arm核心,可实现具有突破性的网络、存储和安全性能。
不管是CPU还是DPU、GPU,很明显,英伟达正在将自己业务边界不断延展,也就是不再局限于以GPU为中心,而是以计算为核心,覆盖多样化的计算工作负载。随之而来的就是客户选择的灵活性,同时整个计算芯片市场也将迎来新的格局。
在加速计算市场,灵活的FPGA已然异军突起。例如微软通过英特尔FPGA加速Azure云服务、必应和其它数据中心服务中的实时人工智能、网络及其它应用或基础设施。
虽然国际国内市场的FPGA厂商挺多,但是FPGA市场的主要玩家便是英特尔与赛灵思,而在AMD在宣布收购赛灵思之后,FPGA市场之间的格局更具看点。
英特尔和赛灵思对于FPGA市场是两种不同的技术路线,这很大程度是取决于他们背后的技术储备和对于FPGA的定位。对于英特尔而言,它旗下有CPU、GPU、Movidius VPU、FPGA等多种面向不同场景的计算平台。所以在英特尔这里,“FPGA就是FPGA”,只不过是一种实现AI算法的途径而已。而在Xilinx这里,FPGA就是它的全部。为了适应更大的市场,Xilinx需要“FPGA不止是FPGA”。所以就诞生了ACAP这样“超越了FPGA”的新型器件。
除了技术产品策略,英特尔和赛灵思之间的竞争因为AMD对赛灵思的收购有了更多故事可讲。这应该是AMD是对英特尔收购Altera的应对,不过对应AMD而言,这可以丰富自身产品线和强化竞争力,还有对FPGA芯片与CPU、GPU的技术融合尝试探索以及未来市场的先行布局。
从加速计算市场我们可以看到加速计算其实与通用计算市场有着千丝万缕的联系,也就是CPU、GPU、FPGA之家具备内在联系,半导体厂商在产品布局方面是将这三者放到一起的,从而更好地为用户提供充沛的算力。
专用芯片的“争奇斗艳”
AI芯片市场随人工智能发展持续火爆,根据Gartner的测算和预测,预计2023年全球AI芯片市场规模将达到343亿美元。
虽然目前通用计算芯片和GPU加速芯片是主流,但是DPU、VPU、TPU、IPU以及各种专用芯片也在迅速崛起,面向特定应用抢占细分市场。
在诸多“PU”中,DPU是最受关注的芯片类型之一,一方面是因为DPU巨大的市场前景,另一方面是因为有英伟达、英特尔这样的巨头参与。可以预见,未来DPU的应用将越来越广泛。业内人士甚至乐观地估计,DPU可能会成为CPU、GPU之外的第三个热点。
简单地说,CPU相当于一个通才,它长处是什么都能干,但效率不高,而GPU、DPU相当于专才,专门干一件或者一类事情,因此效率最高。对CPU、GPU和DPU的区别,DPU初创公司中科驭数创始人兼CEO鄢贵海有个形象的比喻:如果把一台计算机或服务器比作一个团队,CPU相当于这个团队的“大管家”,负责思考并处理各种业务;GPU是“美工”,专攻图像处理;DPU则相当于“前台”,负责打包、拆包“数据包”,提升整个团队的工作效率。
中科驭数2018年成立,今年中科驭数发布了其下一代DPU芯片计划,将基于自研的KPU(Kernel Processing Unit)芯片架构,围绕网络协议处理、数据库和大数据处理加速、存储运算、安全加密运算等核心功能,推出新一代DPU芯片。
目前中科驭数提供网络、数据库、风控等硬件加速解决方案,与上交所、金证股份、360数科等金融行业客户一起加速DPU的应用落地,算力的灵活组合满足金融用户的定制化需求。
例如金证股份已有的行情系统在交易繁忙阶段(如开盘等情况),系统延迟达到51us,而且抖动非常大。而在应用基于中科驭数KPU架构的极速行情系统后,系统延迟降低一个数量级,并且系统都能保持在20ns以下,为交易客户提供了先机。
所谓“英雄所见略同”,星云智联CEO于勇认为,未来的数据中心将不再以通用CPU为核心,而是解构成GPCPU、GPU、TPU、FPGA、DSP等异构算力资源池,以及SSD和磁盘等存储资源池。“未来十年,全球云计算和数据中心基础架构将迎来颠覆性变革,基于DPU的统一通信服务平台(CAAS)是未来架构的核心引擎。”
除了DPU,现在业界的另外一个热词就是IPU,就在近日,英特尔推出XPU产品的最新成员——基础设施处理器(IPU),具体来说,IPU是一种可编程网络设备,扩展了智能网卡功能,这有点类似NVIDIA的DPU。
不过业界对于IPU的定义也不尽相同,Graphcore的IPU是指Intelligence Processing Unit,智能处理器。在Graphcore高级副总裁兼中国区总经理卢涛看来,CPU和GPU都不是专门为AI而设计。而IPU是专为AI应用设计,其强大的并行处理能力确保了快速训练模型的实现,并能进行实时操控。
当计算系统变得更加专用化之后,分层就会显现,异构的进程就会加快。随着工作负载类型的细分以及半导体产业链的变化,未来新型专用加速器会越来越多,以更好地满足不同场景的需求。
国产芯片的“弯道超车”
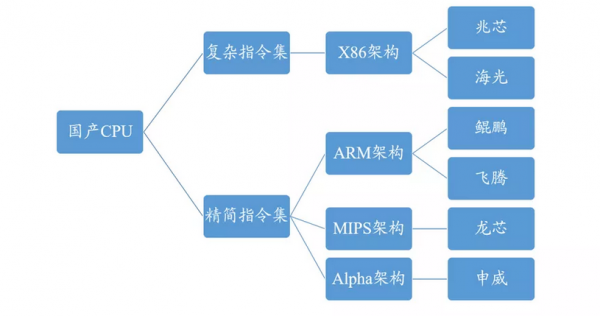
在当前计算产业面临变革之际,我们看到中国厂商的机会也在出现。在新环境和新技术驱动下,国产CPU正处于奋力追赶的关键时期,以飞腾、鲲鹏、海光、龙芯、兆芯、申威等为代表的厂商正全力打造“中国芯”。
以华为为例,其聚焦鲲鹏和昇腾,构建全场景多样性智能计算平台。自2019年华为发布计算战略以来,鲲鹏计算产业生态蓬勃发展,不仅构建了完整的生态体系,并且鲲鹏行业解决方案已在国计民生行业核心系统获得了规模化应用。
鲲鹏计算产业的能力输出,离不开其“硬件开放、软件开源、使能合作伙伴”的技术生态战略。基于鲲鹏生态,各行各业可快速上手基于华为鲲鹏和昇腾处理器的IT基础设施及行业应用,包括PC、服务器、存储、操作系统、中间件、虚拟化、数据库、云服务及行业应用等,在大数据与人工智能场景,发挥其架构优势,释放多元算力。
到目前为止全国已落地24家生态创新中心、12家OEM整机伙伴、2700多家合作伙伴、5700多个解决方案认证、40万鲲鹏开发者,在各行业中已有成熟应用案例,包括电信、互联网、安平、能源、金融、交通、制造、政务等。
目前在国际环境、产业政策、市场需求的联合驱动下,一大批国产CPU厂商奋楫前行,在工艺、性能、生态建设等多个方面不断取得突破,产业布局、资金投入、技术研发、人才培养等各个方面都在快速进步。
未来会有更多的中国优秀芯片企业涌现出来,国产芯片的水平也一定会弯道超车。我们在全球芯片产业链上的话语权,也一定会越来越大!
面向未来的前沿计算
既要脚踏实地,又要仰望星空。如果说前面说到的各种XPU已经近在眼前,那么英特尔和IBM在神经拟态计算(类脑计算)和量子计算的前沿研究给予我们的可能是希望,它们带来的前所未有的创新成果,为计算的未来带来了新的想象空间。
神经拟态计算模拟的是大脑的计算模式,包含很多并行计算和异步计算,不需要提前进行数据训练,可以在工作的过程中自我进行学习,大幅提升效率和能耗。
英特尔已经推出由768个Loihi组成的神经拟态计算系统Pohoiki Spring,拥有1亿个神经元,并成立了神经拟态计算社区,推动神经拟态计算落地。
量子计算已经成为全球科技领域关注的焦点,英特尔推出了代号为“Horse Ridge”的低温控制芯片,实现了对多个量子位的控制,可以实现更大的量子系统扩展。
除了英特尔,我们看到IBM在量子计算领域也在积极布局——2016 年,开放量子云平台,接入5比特的量子芯片Canary ;2019 年,IBM实现了27个比特的量子芯片Falcon;前不久,IBM 向其IBM Q Network成员发布了65个比特的量子处理器Hummingbird。
从2000年起,IBM开始探索超导量子位这一技术路线,2021年,IBM将突破100比特的关卡,推出127比特的Eagle处理器。在Eagle处理器上,IBM引入并发实时经典计算能力,这将允许执行更广泛的量子电路和代码。
除了量子计算,IBM近日发布了全球首个2纳米芯片制造技术,再次引领了半导体行业的潮流。
在英特尔、IBM等均先后投入量子运算领域发展, NVIDIA在GTC 2021也宣布推出名为cuQuantum的开发工具组,让开发者能透过此开发工具组配合NVIDIA GPU进行量子运算特性模拟加速。
困境与挑战
展望未来,随着XPU战略的推进,各大半导体厂商以自身优势产品为依托,不断探索算力的跨界融合,这一趋势也将延续下来。
不过,芯片架构五花八门,指令集不同,无法兼容,而面向芯片的编程库又跟芯片绑定,灵活性差。小公司只做了其中一个环节,这造成生态的纵向不通;大公司希望构建封闭的系统,这造成了生态的横向不通。
芯片从制造出来到大规模用起来,往往还隔着一个巨大的生态鸿沟。芯片应用一般都面临着开发者学习成本高、用户应用迁移困难、芯片制造公司难以上规模的困难和挑战。
在有些芯片造出来后,面向开发者的帮助文档、调试工具或者交流问答社区建设不足,导致开发者学习时间长,难度大,如果学习多个芯片,难度更大,开发者的学习积极性下降。而对于芯片的最终使用者来说,由于芯片指令集或芯片架构的差异,导致编程库、编程模型、算法框架无法有效的横向拉通,致使大量的应用迁移困难,可能只是1%的小小的依赖,就会导致适配工作前功尽弃,进一步带来计算的复杂性。
而芯片供应商如果想解决开发者的问题、想解决使用者的问题,则往往需要投入比芯片研发成本高数十倍的推广费用。
不管是英特尔还是英伟达,他们的硬件产品只是一方面,他们也在将自身定位一家软件公司。例如英特尔内部有超过1万人在围绕芯片的配套支撑、应用适配、优化调优做工作。英伟达提供一系列基于NVIDIA AI以及用于仿真、协作和自主机器训练的软件,尤其是公司的CUDA软件环境更是通过长期的大规模投入,才打造了其GPU在HPC和AI方面的领先地位。
软件是释放异构计算性能的重要一环。英特尔一直也在FPGA、ASIC、GPU和CPU的多种算力产品XPU基础上开发适配的软件,推出了开源的跨架构开发模型oneAPI。
软件开发人员可以使用oneAPI开放式跨架构编程来优化其应用程序,从而避免了专有模型的技术和经济负担。英特尔oneAPI工具包通过高级编译器、库以及分析和调试工具帮助实现处理器的卓越性能、人工智能和加密功能。
英特尔架构、图形和软件集团副总裁兼中国区总经理谢晓清表示,英特尔的战略是希望能够把IA生态系统的开发者最大限度地无缝链接到oneAPI所支持的异构计算领域,为英特尔的XPU战略打下一个坚实的软件基础。
其实,AMD在异构计算整合方面也早有布局,并选择了四步走的持续性战略,其中第四步是架构和系统整合,从硬件到软件完全实现异构计算支持。
2012年,AMD成立了一个HSA(异构系统架构)基金会,拉了ARM、Imagination、联发科、德州仪器、三星等众多一线大厂一同上阵,主推一个叫做OpenCL的异构编程框架。
2015年,AMD宣布名为“Boltzmann计划”的新款开发工具套件,协助用户更简单地开发兼具高性能与低耗能的异构计算系统。“Boltzmann计划”利用HSA架构优势,发挥CPU与AMD FirePro GPU计算资源,通过软件同时释放极致计算效率。
综上所述,XPU不能仅仅是XPU,它不是硬件简单的物理堆砌,而要考虑到其中的互联互通,跨架构的软件协同,只有软硬件协同发展,才能更好的发挥出产品应有的价值。
谁“朋友圈”大
“单兵作战”的效果往往不如“军团作战”,其中的奥秘就是“协同作用”。举例来说,飞机作战,如果只是轰炸机单兵作战,虽然攻击性很强,却缺乏保护体系,需战斗机协同作战,以保护轰炸机的安全。
产品组合以及解决方案才是芯片厂商竞争力的重要表现,这一方面是厂商自身的丰富产品组合,例如XPU便是重要策略。另一方面,芯片厂商的生态建设,积极扩大“朋友圈”。如果产品是一家企业的根本,那么生态活动则是“众人拾柴火焰高”。
英特尔公司副总裁兼至强处理器与存储事业部总经理Lisa Spelman表示,对于英特尔来说,提供满足客户需求的产品组合,这是非常巨大的差异化的竞争优势,这是英特尔数据中心战略的核心。
“我们的关注点是通过产品组合传递客户价值。我们现在要将产品提升到系统层面的解决方案。英特尔新增加的产品和解决方案都是作为整个平台的延续给客户提供价值和解决问题。”Lisa Spelman说。
为了让产品方案化,英特尔还推出了英特尔精选解决方案和英特尔市场就绪解决方案,帮助客户加速云、人工智能、企业端、高性能计算、网络、安全和边缘应用上的部署。其中近80%的英特尔精选解决方案将在今年年底前完成更新为搭载第三代英特尔至强可扩展处理器。
其实不光英特尔,我们看到不管是Arm还是英伟达等厂商,都在积极构建生态圈。例如Arm生态系统在移动和嵌入式方面一直很强大。从Arm架构发展历程来看,通过社区建设增强用户认知度,打造成熟的生态系统是其取得成功的关键因素。
同时,Arm借助v9的推出也在向其他计算领域延展。通过将全面计算的设计原则应用在包含汽车、客户端、基础设施和物联网解决方案的整个IP组合中,Arm v9系统级技术将遍及整个IP解决方案,并改善个别IP。
英伟达也一样,其也在积极发展软硬件一体化的组合,并借助合作伙伴生态系统在HPC和AI等领域拓展更为广阔的空间。例如借助英伟达企业合作伙伴计划(NPN),英伟达在全球范围内拥有超1500名合作伙伴,提供加速网络、分解式网络以及软件定义的网络,以满足 AI、云和高性能计算快速增长的需求。
总之,借助生态系统将自身的XPU产品组合以及与合作伙伴联合打造的解决方案触达用户是半导体厂商赢得市场的关键。
结语
数字时代对计算力提出了前所未有的要求,算力将成为新的生产力。
这反映到产业层面,众多芯片厂商竞相切入XPU的赛道。展望未来,通用计算市场稳中求变,不管是x86、Power、Arm等在保持既有技术优势的同时,也在不断适配和拓展新的应用场景。
对于GPU、FPGA等加速计算芯片市场,随着AI类工作负载成为主流,他们的发展空间巨大,但是这些加速芯片需要与通用计算芯片协同工作才能更好地发挥其自身价值,这也预示着类似英特尔、AMD、英伟达、Arm等厂商会在通用计算和加速计算两个市场展开积极布局。
对于ASIC专用芯片市场,虽然这是一个相当长尾的市场,但是该市场的创新活跃度是最高的,成为众多创新创业公司的目标领域。虽然他们现在还不是市场主流,但是在满足客户定制化的需求方面,ASIC芯片的重要性是不言而喻。
国产芯片的发展任重道远,但是在外部环境和国家政策的驱动下,国产芯片的被重视程度会越来越高,但是国产半导体芯片厂商的成长之路注定是不平坦的。
虽然神经拟态计算(类脑计算)和量子计算还处于研究探索阶段,但是其展示了未来的无限可能。随着相应研究投入的持续增加,相关应用也会涌现,这点也值得我们持续关注。
在全景展现XPU产业之际,我们也看到芯片厂商需要在软硬件协同、生态构建等方面还有巨大的改善空间,他们需要倾听客户和用户的声音,通过需求驱动产品和技术的发展。
站在数字经济发展的新阶段,算力的价值日渐凸显。随着大数据、人工智能、边缘计算等技术的发展,计算架构的“新黄金十年”已经开启,计算产业正在迎来新的发展机遇。
展望未来,XPU市场将呈现百花齐放的局面,各种芯片在各自的赛道发挥自身独特的价值。同时各种计算架构之间在聚焦自身优势的同时,也在相互融合协同,形成了“你中有我,我中有你”的局面。
好文章,需要你的鼓励



牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

美国多源电子患者数据采集方法研究综述
随着医疗数据数字化与互操作性的进步,跨机构纵向患者数据的研究应用成为可能。本研究通过对20位领域专家的访谈,识别出8种数据收集方法,涵盖智能手机应用、结构化数据导出、区域/全国研究查询及聚合数据源等。研究发现,各方法均有其优缺点,无单一最优方案。参与者中介交换方式可绕过复杂治理安排,但存在数据缺口;全国性网络尚不支持研究查询。公共政策的持续推进将对该领域发展起关键作用。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。

