
Neoverse进展顺利,Arm向数据中心发起强力冲击 原创
由于高能效、低功耗等特点,Arm在移动设备和物联网市场得到广泛应用,拥有庞大而且成熟的生态体系,而在传统的以数据中心代表的基础设施市场则是属于英特尔的。能否把Arm的技术优势复制到基础设施领域?
在Arm看来,答案自然是肯定的。Arm正在做这件事情,而且已经做了超过10年了,Neoverse就是ARM进军数据中心市场放出的大招。Neoverse是Arm 2018年首次对外宣布的一个全新产品系列,主要面向5G网络和下一代云端到边缘基础设施,简单地理解就是服务器市场。Neoverse架构有更高级别的性能、安全性和可扩展性,其从微架构设计到芯片、软件和系统进行的全面创新以满足整个计算领域多样化且不断变化的需求。
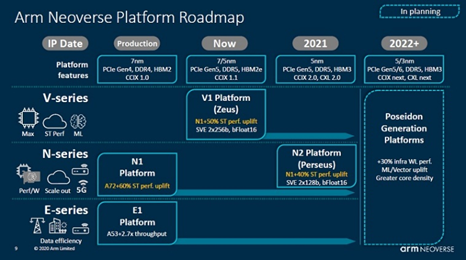
Neoverse包括三个系列,分别是V系列、N系列、E系列,其中V系列主要面向对计算性能要求比较高的场景,E系列主要面向对能耗要求比较高的场景,N系列主要面向对可扩展性要求比较高的场景。2019年上半年,Arm首先推出了Arm Neoverse平台的两款产品,即Neoverse N1平台和E1平台。去年9月Arm更新了Neoverse产品路线图,新增了两款产品,分别是V1和N2平台。而这周Arm解密了Neoverse V1和N2平台的产品细节,也同时发布了CMN-700,作为构建基于Neoverse V1和 N2平台高性能SoC的关键部件。
Neoverse亮相2年来,在HPC、云计算以及5G等市场推广很快,不仅在AWS有Graviton 以及Graviton2这样的芯片正式投入商用,Oracle 也已经宣布计划将 Ampere Altra 用于其云基础设施,而在HPC领域,不仅有世界最快超级计算机日本富士通Fugaku这样的用户,而且印度也宣布研发基于Neoverse的超级计算机。
性能和能效可以兼得
在Arm Neoverse亮相之前,Arm在基础设施市场已经耕耘超过10年。之前很长时间Arm在这个市场的主力是Cortex-A72,它具有非常出色的能效比,单核性能表现也很好,借助Marvell、英伟达、博通和恩智浦等合作伙伴,以智能网卡、DPU 和物联网芯片等形式在网络和边缘应用场景中得到广泛应用。
“我们的用户希望Arm芯片能在基础设施市场表现得更好,性能能进一步提高,并在大规模使用时保证性能。于是就有了现在的 Neoverse N1内核和 CMN-600 Mesh 网络,它在核数增加时依然能保证线性性能扩展,也使得 Neoverse 更加适合云服务。”Arm基础设施事业部高级副总裁兼总经理 Chris Bergey在接受记者采访时表示。
据悉,Neoverse N1的单核性能现在已可以匹敌或超过传统 SMT 线程的性能,而从能效的角度看,则可以节约2/3,从而大大增加了Arm在基础设施市场的应用范围。
如果说Neoverse N1开创了Arm芯片高性能、高能效和可扩展计算的新时代,那么 Neoverse V1 和 N2则让Arm再上一天台阶。与N1相比,Neoverse V1有50%的性能提升、1.8倍的矢量工作负载优化以及4倍的机器学习工作负载优化,同时,Neoverse V1也是Arm强调性能优先的新型计算系列的第一个平台。Neoverse V1 使芯片合作伙伴能灵活地为高度依赖CPU性能和带宽的应用构建计算能力,并为其提供 SoC 设计的灵活性。
秉持性能至上的思维,Neoverse V1 的设计理念创造了Arm迄今为止设计过的最宽微架构。Neoverse V1宽而深的架构,加上SVE指令集使其在单核性能和通过SVE延长代码存活期等方面占据领先优势,并为芯片设计人员提供可实现的灵活性。

Arm在几周前发布了ArmV9 架构,以满足高性能、高安全的新一代计算需求。Neoverse N2平台就是第一个基于Armv9架构的平台,在安全性、能耗以及性能方面都有全面的提升。相比于N1,Neoverse N2在保持相同水平的功率和面积效率的基础上,单线程性能提升了40%。Neoverse N2具备良好的可扩展性,可以横跨从高吞吐量计算到功率与尺寸受限的边缘和5G应用场景,并在这些应用中带来优于N1的表现。
Neoverse N2平台提供了优异的单线程性能和业界领先且能为用户减少TCO的每瓦性能表现。Neoverse N2还是第一个具备SVE2功能的平台,该功能可为云到边缘的性能效率带来巨大的提升。在诸如机器学习、数字信号处理、多媒体和5G等广泛应用场景中,SVE2除了带来大幅性能提升外,还具备了SVE的编程简易性及可移植性等优势。

而CMN-700是CMN-600的进一步提升,CMN-700在每个矢量上进一步提升了性能——从内核的数量、缓存的大小,到附加内存及 IO 设备的数量和类型。通过Arm对CCIX和CXL持续不断的投入,更多的定制选项应运而生,进而使合作伙伴的解决方案具备总线和高核数的可扩展性特色。这将为突破传统的硅限制提供新的机遇,并为紧密耦合的异构计算提供更大的灵活性。
不断壮大的合作伙伴体系
Neoverse产品路线图在去年9月的更新,证明了Arm对Neoverse的承诺。而在市场上,Arm 的Neoverse也得到广泛认可,众多合作伙伴加入到生态系统,其中不乏AWS、Oracle这样的重量级合作伙伴。
AWS的Graviton值得一提。Graviton是基于Neoverse N1平台研发的。目前,AWS Graviton 芯片已经部署于 AWS 的多个服务区域,在 AWS 全球77个区域中的70个区域已经启用基于 Graviton 的 vCPU。对于一款正式发布不到一年的产品,这个进度应该说非常快。据悉,AWS去年新增实例中有近一半是基于 Graviton2 平台。
实际上,不止是AWS,类似的云服务商还有甲骨文。甲骨文计划在Oracle云基础设施上采用Ampere Altra CPU,为各种工作负载提供最佳的性价比。
而在网络方面,Marvell发布了基于Neoverse N2 的OCTEON系列网络解决方案,并预计于2021年底前试产。相较于前一代的OCTEON解决方案,其性能提升高达3倍。
在超算上,Arm处理器也同样收获颇丰,不但有目前位列全球超算500强第一名的日本富士通超级计算机Fugaku这样的成功案例,而且印度电子信息技术部(MeitY)已宣布将加入法国芯片公司 SiPearl 和韩国电子通信研究所( ETRI)的行列,采用Neoverse V1驱动国家级百万兆级高性能计算项目。
在中国,阿里云与腾讯云也已经参与到Arm的生态系统中,阿里云在即将上线的基于Arm架构ECS 实例上完成了测试,结果显示在 SPECjbb 的测试数据中获得了惊艳的表现,且基于Arm架构运行的 DragonWell JDK 性能提高了 50%。腾讯在硬件测试和软件支持方面持续投入,使其在云应用上能采用 Arm Neoverse 技术。
随着这些成功案例的不断推出,后面也将有更多合作伙伴和用户会加入到Arm生态,这些合作伙伴和Arm一起利用 Neoverse 平台的特色,服务于基础设施各个领域,从而在基础设施领域形成X86架构之外新的一级。
来源:至顶网计算频道
好文章,需要你的鼓励


CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
很多人担心被AI取代,陷入无意义感。按照杨元庆的思路,其实无论是模型的打造者,还是模型的使用者,都不该把AI放在人的对立面。

MIT递归语言模型:突破AI上下文限制的新方法
MIT研究团队提出递归语言模型(RLM),通过将长文本存储在外部编程环境中,让AI能够编写代码来探索和分解文本,并递归调用自身处理子任务。该方法成功处理了比传统模型大两个数量级的文本长度,在多项长文本任务上显著优于现有方法,同时保持了相当的成本效率,为AI处理超长文本提供了全新解决方案。

Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
谷歌宣布对Gmail进行重大升级,全面集成Gemini AI功能,将其转变为"个人主动式收件箱助手"。新功能包括AI收件箱视图,可按优先级自动分组邮件;"帮我快速了解"功能提供邮件活动摘要;扩展"帮我写邮件"工具至所有用户;支持复杂问题查询如"我的航班何时降落"。部分功能免费提供,高级功能需付费订阅。谷歌强调用户数据安全,邮件内容不会用于训练公共AI模型。

华为研究团队突破代码修复瓶颈,8B模型击败32B巨型对手!
华为研究团队推出SWE-Lego框架,通过混合数据集、改进监督学习和测试时扩展三大创新,让8B参数AI模型在代码自动修复任务上击败32B对手。该系统在SWE-bench Verified测试中达到42.2%成功率,加上扩展技术后提升至49.6%,证明了精巧方法设计胜过简单规模扩展的技术理念。
2021
04/30
20:14
分享
点赞

联想集团混合式AI实践获权威肯定,CES期间获评“全球科技引领企业”
CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
CES 2026 | 重大更新:NVIDIA DGX Spark开启“云边端”模式
Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
研究发现商业AI模型可完整还原《哈利·波特》原著内容
Razer在2026年CES展会推出全息AI伴侣项目
CES 2026:英伟达新架构亮相,AMD发布新芯片,Razer推出AI奇异产品
通过舞蹈认识LimX Dynamics的人形机器人Oli
谷歌为Gmail搜索引入AI概览功能并推出实验性AI智能收件箱
DuRoBo Krono:搭载AI助手的智能手机尺寸电子阅读器
OpenAI推出ChatGPT Health医疗问答功能
Anthropic寻求3500亿美元估值融资100亿美元
