
浪潮AI服务器创全球权威MLPerf基准测试18项AI性能纪录
美国东部时间10月21日,全球备受瞩目的权威AI基准测试MLPerf公布今年的推理测试榜单,浪潮AI服务器NF5488A5一举创造18项性能纪录,在数据中心AI推理性能上遥遥领先其他厂商产品。
MLPerf是当前全球最具影响力的AI计算基准评测组织,由图灵奖得主大卫·帕特森(David Patterson)联合谷歌、斯坦福、哈佛大学等单位共同成立,每年组织全球AI训练和AI推理性能测试并发榜。此次MLPerf的AI推理基准测试有全球23家公司和单位参与,在数据中心及边缘等场景进行AI计算产品的性能比试。今年MLPerf训练榜单已于7月公布。
浪潮NF5488A5获数据中心AI性能绝对优势
此次浪潮NF5488A5一举创造18项MLPerf推理性能纪录,成为创纪录最多的AI服务器。今年的测试中,数据中心AI性能最受关注,全部参与机构提交了507项性能测试数据。浪潮NF5488A5创下了数据中心22个赛项中的13项性能纪录以绝对优势领先,NVIDIA DGX取得了5项数据中心性能纪录。而在此前的MLPerf训练榜单中,NF5488A5在最核心的Resnet50训练任务中也创下了性能纪录,单机性能高居榜首。
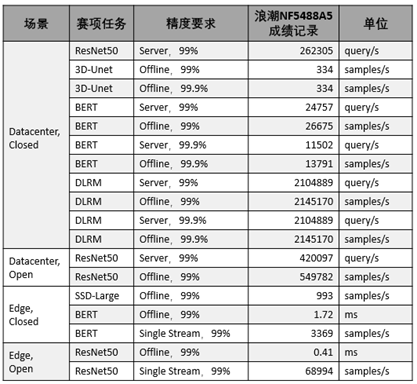
浪潮NF5488A5创造18项MLPerf推理性能纪录
性能大幅提升3倍,全栈AI能力优势凸显
在此次基准测试中,浪潮AI服务器NF5488A5在开放优化(Open)和固定任务(Closed)的ResNet50基准性能测试中,均表现优异,相比2019年MLPerf推理榜单的服务器最好性能提升高达3倍。
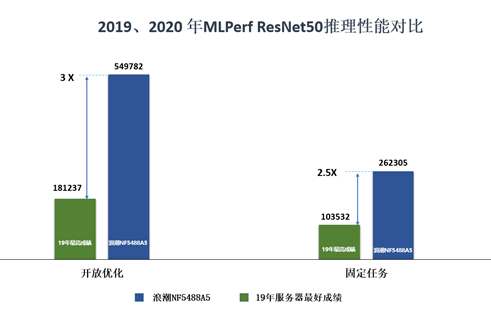
MLPerf ResNet50推理性能2019 VS 2020对比
NF5488A5是浪潮自研的新一代AI服务器,是此次MLPerf全球竞赛中唯一可以在4U空间内支持8块安培架构A100芯片实现NVLink高速互联的AI服务器。浪潮NF5488A5在系统拓扑上采用了超低延迟设计,支持PCIe 4.0全链路极致优化,高频通信单元采用一级拓扑最近连接,最大限度提升处理器到AI芯片间的通信性能。同时,通过配置NUMA节点,确保每颗处理器与其直连的GPU之间通信性能最优,最大限度降低通信延迟。此外,NF5488A5通过深度优化系统结构设计,确保设备可在高温环境下稳定运行。
本次基准测试中,浪潮展示出了卓越的AI计算软硬件协同优化能力。在硬件层面,通过对CPU、GPU硬件性能的精细校准和全面优化,使CPU性能、GPU性能、CPU与GPU之间的数据通路均处于对AI推理最优状态;在软件层面,结合GPU硬件拓扑对多GPU的轮询调度优化使单卡至多卡性能达到了近似线性扩展;在深度学习算法层面,结合GPU Tensor Core 单元的计算特征,通过自研通道压缩算法成功实现了模型的极致性能优化,在精度无损的情况下性能提升近2倍。
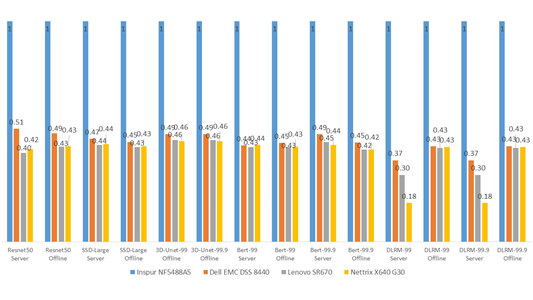
各服务器MLPerf AI推理性能对比(以浪潮NF5488A5为基准,越高越好)
浪潮是全球领先的AI计算领导厂商,其AI服务器在中国的市场份额已连续三年保持在50%以上。浪潮致力于AI计算平台、资源平台和算法平台的研发创新,并通过元脑生态与AI领先企业共同推进AI产业化和产业AI化进程。
来源:业界供稿
好文章,需要你的鼓励


AI智能体漏洞挖掘成本骤降,Anthropic呼吁AI防御
Anthropic发布SCONE-bench智能合约漏洞利用基准测试,评估AI代理发现和利用区块链智能合约缺陷的能力。研究显示Claude Opus 4.5等模型可从漏洞中获得460万美元收益。测试2849个合约仅需3476美元成本,发现两个零日漏洞并创造3694美元利润。研究表明AI代理利用安全漏洞的能力快速提升,每1.3个月翻倍增长,强调需要主动采用AI防御技术应对AI攻击威胁。

NVIDIA联手多所高校推出SpaceTools:AI机器人有了“火眼金睛“和“妙手回春“
NVIDIA联合多所高校开发的SpaceTools系统通过双重交互强化学习方法,让AI学会协调使用多种视觉工具进行复杂空间推理。该系统在空间理解基准测试中达到最先进性能,并在真实机器人操作中实现86%成功率,代表了AI从单一功能向工具协调专家的重要转变,为未来更智能实用的AI助手奠定基础。

Spotify年度盘点2025首次推出多人互动功能“盘点派对“
Spotify年度总结功能回归,在去年AI播客功能遭遇批评后,今年重新专注于用户数据深度分析。新版本引入近十项新功能,包括首个实时多人互动体验"Wrapped Party",最多可邀请9位好友比较听歌数据。此外还新增热门歌曲播放次数显示、互动歌曲测验、听歌年龄分析和听歌俱乐部等功能,让年度总结更具互动性和个性化体验。

机器人学会“三思而后行“:中科院团队让AI机器人告别行动失误
这项研究解决了现代智能机器人面临的"行动不稳定"问题,开发出名为TACO的决策优化系统。该系统让机器人在执行任务前生成多个候选方案,然后通过伪计数估计器选择最可靠的行动,就像为机器人配备智能顾问。实验显示,真实环境中机器人成功率平均提升16%,且系统可即插即用无需重新训练,为机器人智能化发展提供了新思路。
2020
10/26
10:12
分享
点赞

AI智能体漏洞挖掘成本骤降,Anthropic呼吁AI防御
Spotify年度盘点2025首次推出多人互动功能"盘点派对"
英国SAP用户因商业套件重启授权迷局感到困惑
AWS发布Graviton5定制CPU,为云工作负载带来强劲性能
美光放弃Crucial品牌:告别消费级存储市场
手机里的NPU越来越强,为什么AI体验还在原地踏步?
如何使用现有基础设施让数据做好AI准备
IT领导者快问快答:思科光网络公司首席数字信息官Craig Williams分享AI转型经验
Anthropic CEO警告AI行业泡沫化,批评"YOLO"式投资
雅虎利用AI实时总结橄榄球比赛精彩内容
押注AI智能体,奇奇科技跨越十年的“换挡”与远航
联想天禧AI及创新终端设备在2025 AIE博览会获两项大奖,引领个人AI体验创新
