
又双叒叕破纪录了!NVIDIA打破AI推理性能记录 原创
又打破纪录了!
NVIDIA宣布,其AI计算平台在最新一轮MLPerf基准测试中再次打破性能记录,在这一业内唯一评估硬件、软件和服务的第三方AI性能基准测试中进一步扩大了其领先优势。
如果大家还有印象的是在7月,NVIDIA打破MLPerf基准测试16项AI性能纪录。NVIDIA在测试中用到的产品基于最新NVIDIA Ampere架构以及Volta架构。A100 Tensor Core GPU在加速器的全部八项MLPerf基准测试中展现了最快的性能。在实现总体最快的大规模解决方案方面,利用HDR InfiniBand实现多个DGX A100系统互联的庞大集群——DGX SuperPOD系统在性能上,也开创了八项全新里程碑。
7月份那次的测试表现是NVIDIA在MLPerf训练测试中连续第三次展现了最强劲的性能。2018年12月,NVIDIA首次在MLPerf训练基准测试中创下了六项纪录,次年7月NVIDIA再次创下八项纪录。
众所周知,MLPerf基准测试是业内首套衡量机器学习软硬件性能的通用基准。而这次是NVIDIA在MLPerf推理测试性能表现。AI通常分解成训练和推理两个过程,经过训练(training)的神经网络可以将其所学应用于数字世界的任务——例如识别图像、语词,并可以基于其训练成果对其所获得的新数据进行推导,在人工智能领域,这个过程被成为“推理(inference)”。
从这个意义上说,只有训练和推理都表现优秀才能成为合格的AI。而GPU具备并行计算(同时进行多个计算)能力,既擅长训练,也擅长推理。使用GPU训练的系统可以让计算机在某些应用案例中实现超过人类水平的模式识别和对象检测。训练完成后,该网络可被部署在需要“推理”的领域中。而具备并行计算能力的GPU可以基于训练过的网络运行数十亿的计算,从而快速识别出已知的模式或对象。
NVIDIA在MLPerf训练和推理测试中的上佳表现,从而让NVIDIA AI平台成为“全能选手”,在数据训练与分析、推理等环节释放AI的力量。
AI推理性能的新“高峰”
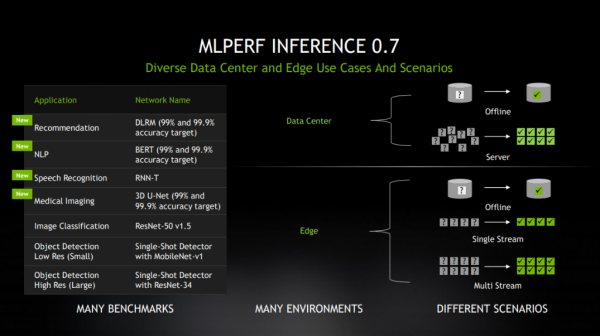
在今年第二轮MLPerf推理测试中,NVIDIA创下了数据中心与边缘计算系统全部六个应用领域的记录。此次测试中,计算机视觉测试从最初的两项扩展到四项,涵盖了AI应用增长最快的领域,包括:推荐系统、自然语言理解、语音识别和医疗影像。
NVIDIA及其11家合作伙伴提交了基于NVIDIA加速平台的MLPerf 0.7的1029个测试结果,占数据中心和边缘类别中参评测试结果总数的85%以上。该平台包含NVIDIA数据中心GPU、边缘AI加速器和经过优化的NVIDIA软件。
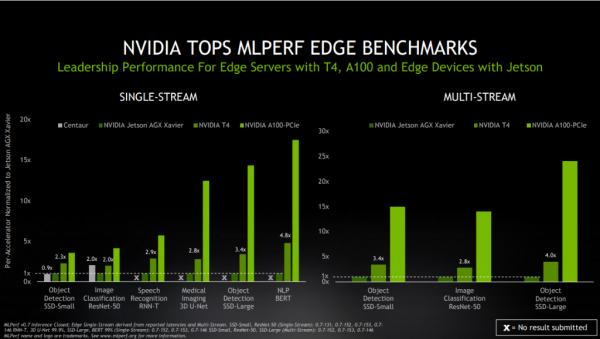
NVIDIA于今年早些时候发布了A100。凭借其第三代Tensor Core核心和多实例GPU技术,A100在ResNet-50测试中的领先优势进一步扩大。在上一轮测试中,它以30倍比6倍的成绩击败了CPU的测试结果。
基准测试结果显示,NVIDIA T4 Tensor Core GPU仍然是主流企业、边缘服务器和高成本效益云实例的可靠推理平台。在同一测试中,NVIDIA T4 GPU的性能比CPU高出28倍。此外,NVIDIA Jetson AGX Xavier已成为基于Soc的边缘设备中最强大的平台。
这些结果离不开高度优化的软件堆栈,包括NVIDIA TensorRT推理优化器和NVIDIA Triton推理服务软件。这两款软件堆栈均可在NGC(NVIDIA的软件目录)中获取。
现在,大多数NVIDIA及其合作伙伴在最新MLPerf基准测试中使用的软件,已可通过NGC获取。NGC中包括多个GPU优化的容器、软件脚本、预训练模型和SDK,可助力数据科学家和开发者在TensorFlow和PyTorch等常用框架上加速AI工作流程。
另外,此次MLPerf Inference 0.7基准测试中,新增了针对数据中心推理性能的推荐系统测试。在该测试中,NVIDIA凭借A100进一步扩大了在MLPerf基准测试中的领先优势,实现了比CPU快237倍的AI推理性能。
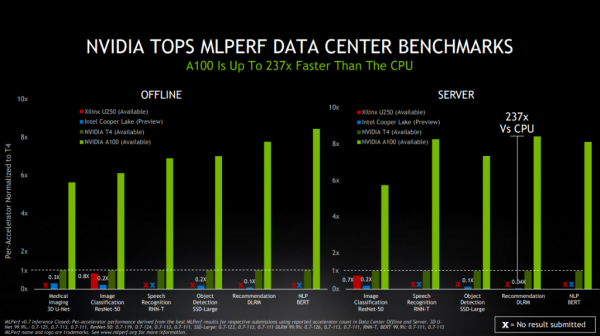
这意味着,一套DGX A100系统可以提供相当于近1000台双插槽CPU服务器的性能,能为客户AI推荐系统模型从研发走向生产的过程,提供极高的成本效益。

NVIDIA Ampere架构是最大“功臣”
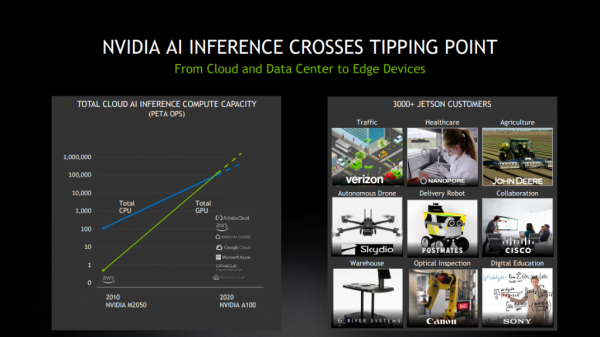
在MLPerf最新结果出炉之际,NVIDIA的AI推理业务也已得到迅速扩展。五年前,只有少数领先的高科技公司使用GPU进行推理。现在,企业可通过各大云和数据中心基础设施供应商来使用NVIDIA的AI平台。各行业都在使用NVIDIA的AI推理平台改善业务运营,提供更多的服务。
此外,NVIDIA GPU首次在公有云中实现了超越CPU的AI推理能力。基于NVIDIA GPU的总体云端AI推理计算能力每两年增长约10倍。从云、数据中心到边缘,NVIDIA AI正在迎来爆发点,而A100是重要载体。A100是首款基于NVIDIA Ampere架构的处理器。得益于其诸多创新,NVIDIA A100集合了AI训练和推理,其性能相比于前代产品提升了高达20倍。
NVIDIA Ampere GPU采用了7纳米制程工艺,包含超过540亿个晶体管,这样的数据足以令人乍舌。而NVIDIA广泛采用的Tensor Core核心也获得了更新,具有TF32的第三代Tensor Core核心能在无需更改任何代码的情况下,使FP32精度下的AI性能提高多达20倍。此外,Tensor Core核心现在支持FP64精度,相比于前代,其为HPC应用所提供的计算力比之前提高了多达2.5倍。
同时,全新Ampere架构搭载了多实例GPU(MIG)、第三代NVIDIA NVLink、结构化稀疏等技术。其中MIG技术可以将单个A100 GPU分割为多达七个独立的GPU,为不同规模的工作提供不同的计算力,以此实现最佳利用率和投资回报率的最大化。
NVIDIA加速计算部门总经理兼副总裁Ian Buck表示:“我们正处在一个转折点,各个行业都致力于更好地利用AI,从而提供新的服务并寻求业务的发展。NVIDIA为MLPerf上取得的成绩付出了巨大的努力,将助力各企业的AI性能提升到新的高度,以改善我们的日常生活。”
好文章,需要你的鼓励


大众汽车推进平价电动车战略,两款新车率先下线
大众汽车旗下ID. Polo与Cupra Raval已在西班牙马托雷尔工厂正式下线投产。两款车型起售价分别为24,995欧元和26,000欧元,均基于MEB+平台打造,搭载37kWh或52kWh电池组,续航里程最高可达454公里。这是大众"电动城市车家族"系列的首批产品,预计今年夏末秋初开始交付。大众集团通过跨品牌资源整合,实现约6亿欧元的成本节约,后续还将推出ID. Cross等新成员。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

三星Health应用迎来AI升级,Galaxy Watch 9发布前夕更新提前揭晓
三星宣布将于6月8日起为Samsung Health应用推出重磅功能更新,赶在Galaxy Watch 9传闻发布之前落地。新版本将引入多项AI驱动的生物特征分析功能,包括:综合心率、血氧、皮肤温度等数据的每日活力评分(Vitals)、结合体成分数据评估长期心脏健康的心脏健康评分、优化训练强度的每日有氧负荷追踪,以及横向对比用户群体的健身指数。此外,应用界面将重新划分为睡眠、营养、活动、正念和体征五大板块,并新增抗氧化指数、年龄指数和听力保护等个性化功能。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。
2020
10/22
10:43
分享
点赞

三星Health应用迎来AI升级,Galaxy Watch 9发布前夕更新提前揭晓
Meta智能眼镜被曝含"人脸识别"追踪代码,隐私风险引发警示
Gemini企业智能体平台的智能体RAG如何实现可靠响应
麻省理工学院AI与计算研讨会:技术进步中不可或缺的人文因素
亚马逊全新数据中心路由架构降低AWS网络能耗40%
iOS 27即将发布,多款iPhone应用将迎来全新设计升级
连接性已成为与计算和存储同等重要的AI基础设施核心要素
开发者仍在等待Meta最新AI模型的API访问权限
迈向Token经济时代,F5以“AI赋能交付”筑基智能新生态
米拉·穆拉提重返公众视野,谨慎发声
特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
智能体网络流量首超真人访问,"死亡互联网"理论引发新争议
