
IBM GDPS 五种高可用&灾备方案比较及选择 原创
企业数据中心的灾备和业务连续性解决方案的架构和实施对于企业已经越来越重要。企业需要参考业界实践来制订或实施切合自身实际情况的方案,或对现有的实现进行改进提高。本文主要介绍IBM GDPS解决方案家族和实际应用在站点双活或站点快速切换实施上的一些实践。
数据中心,顾名思义是数据为王。数据正在成为新的自然资源。这不仅是互联网时代最与众不同的资源,也是互联网时代企业竞争优势的基础。数据对每一个公司的差别化竞争优势,都蕴藏着巨大的潜能。如何利用好数据已然成为最热门的话题之一。然而千万不能忽视了根本的根本,那就是如何保护好源数据。准确鲜活的源数据,才是真正有价值的宝藏。保护好数据,就是保护了自己的宝藏、自己的生命线。
简而言之,灾难恢复就是指利用技术,管理手段以及相关资源确保既定的关键数据,关键数据处理系统和关键业务在灾难发生后可以恢复的过程。一旦灾难发生,灾难备份中心就必须要在确定的时间内接替生产中心的运营,恢复既定范围内的业务运作,保障企业业务连续性。
近代的IT实践也证明了,数据安全对于业务连续性的重要性,是一个企业生死存亡的大事。虽然欧美很多金融机构早在大数据信息时代来临之际就着手进行灾难备份并加强对业务连续性系统的建设工作,但是直到911事件发生之后,金融行业才开始真正重视灾备能力的建设,并投入大量人力物力提升业务连续性水平。911事件中,金融机构聚集的世贸大厦里的大量数据化为乌有,这是对所有金融机构的重大挑战:
德意志银行(Deutsche Bank)早在1993年就制定了严谨可行可信的业务连续性计划(BCP),灾难发生后,德意志银行调动4000多名员工及全球分行的资源,短时间内在距离纽约30公里的地方恢复了业务运行,得到了客户和行业的好评。
摩根士丹利(Morgan Stanley)在25层办公场所全毁、3000多员工被迫紧急疏散的情况下,半小时内就在灾备中心建立了第二办公室,第二天就恢复了全部业务,可谓金融灾备的典范。
与之相反,纽约银行(Bank of New York)在数据中心全毁,通讯线路中断后,缺乏灾备系统和有力的应急业务恢复计划, 造成一系列连锁反应,关掉相关分支机构。
据IDC(International Data Center,国际数据中心)的统计数字表明,美国在2000年以前的10年间发生过灾难的公司中,有55%当时倒闭,剩下的45%中,因为数据丢失,又有29%也在两年之内倒闭,生存下来的仅占16%。
另据统计,金融业在灾难后信息系统停机2天所受的损失为日营业额的50%,如果两个星期内无法恢复信息系统,75%的公司将业务停顿,43%的公司将再也无法开业,没有实施灾难备份措施的公司,60%将在灾难后2-3年间破产。
其实人们早在1970年代就萌发了灾备恢复的念头,1980年代就开始有了为客户提供灾难恢复的数据中心公司成立,客户的灾备意识也有了较大的增长,相关灾难恢复计划的法律法规也开始制定。在1990年著名的千年虫让人们在发展灾备恢复计划的基础上又认识到了业务连续性的重要性。然而,没有教训,决心就不坚定。上面的血泪教训终于让人们痛定思痛、痛下决心,在数据中心灾难备份功能和业务连续性要求上有了更加明确、强制的合规要求。随着互联网的崛起,电子商务的蓬勃发展,数据比以往显得更加重要。各大企业和组织在数据灾备和业务连续性的问题上,已经不是仅仅满足监管要求而已,而是要做得更好。保障数据安全性、提高业务连续性在愈发激烈的竞争中已经变得不可或缺。
IBM主机自1964年正式推向市场以来,一直在世界经济活动中起到了重要的作用。众多的关键客户在IBM主机的支持下很好地应对了世界经济起伏变化的各种挑战。同时,这些挑剔地客户也对IBM主机提出了挑剔地要求。在挑剔客户的促进下,基于IBM主机的解决方案也是日臻全面和成熟。
IBM主机在灾备和业务连续性方面的解决方案当然是首选GDPS家族了。GDPS(Geographically Dispersed Parallel Sysplex)是一种多站点或单站点端到端解决方案,能够让用户从一个统一的控制点完成对分布在多个站点的主机系统、磁盘和数据复制等进行自动化的管理和操作,在出现故障场景时自动进行恢复操作。
GDPS还支持多种磁盘复制架构;自动化Sysplex的运维操作;一定程度上兼顾z/OS系统和开放系统的数据;提供开放的架构为客户定制和裁剪提供高度灵活性;GDPS的实施几乎和用户应用无关,用户仍然只需专注自己的业务逻辑的开发,而并不需要花大功夫特意为灾备而进行应用改造。
GDPS家族的解决方案把高可用性和灾备恢复能力提供给广大用户,为客户提供跨中心,跨地域的灾备、双活的解决方案,帮助实现计划内和计划外停机的恢复程序的自动化,以实现近乎连续的可用性和灾难恢复能力。将近20年的客户实践,也使得GDPS家族的产品方案日臻成熟和完善。从为保证中心内磁盘的故障,到两地三中心双活的实现,GDPS为客户提供自动化一键式的解决方案,大大简化生产运维和灾备恢复的复杂度。

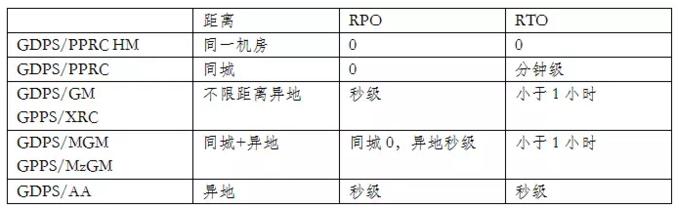
GDPS家族的五大解决方案如上图所示:
GDPS/PPRC HyperSwap Manager提供单一数据中心内部数据的持续可用。RTO=0和RPO=0使得业务系统可以在磁盘系统发生故障的情况下保持连续可用。
GDPS/PPRC方案可以提供同城范围内持续可用和灾备方案。同城的两个数据中心可以是双活模式,通过不同的配置可以得到Active/Standby模式的RPO=0, RTO<1小时;或者Active/Active模式的RPO=0和分钟级的RTO。由于核心的部分是跨站点的Sysplex,因而考虑到性能影响则存在一定的距离限制。
GDPS/GM和GDPS/XRC方案可以提供异地灾备的能力。在不限距离的情况下,实现秒级的RPO和小于1小时的RTO。
GDPS/MGM和GDPS/MzGM是前两种方案的混合体,可以提供完整的两地三中心解决方案。实现同城A/S或A/A模式下RPO=0,RTO<1小时或分钟级的灾备以及异地秒级RPO和<1小时的RTO灾备。
最后一个方案,GDPS/Active-Active方案实现了跨中心的双活和负载调度,实现持续的高可用。设计的出发点是与距离无关。因而采用了基于软件复制技术的数据复制。同时使用Lifeline产品完成智能载荷跨中心调度。GDPS/A-A产品提供了完善统一的管理服务,使得中心间的切换可以达到一键式完成。
以上五个方案分别针对于不同的灾备需求(距离,RPO,RTO):
各位看官您可能也已经注意到了一个事实,那就是仅仅看到几个GDPS解决方案和它们的一些基本功能并不能解决您心中所有疑虑。那么让我们再看一下基于GDPS产品家族在提升业务连续性上的双活实现或站点快速切换的实践方案吧。
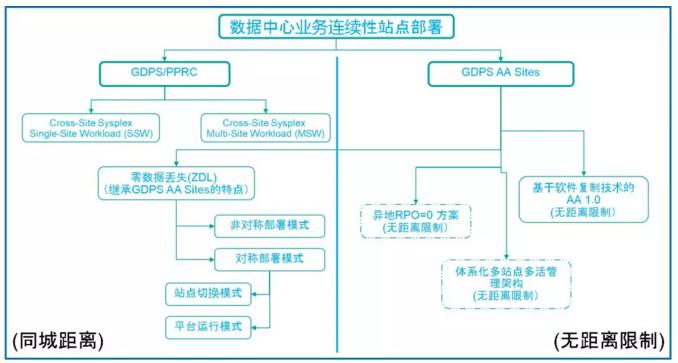
在上图中笔者总结并展望了已经实现的方案和未来可能可以进步的方向。
首先,在业务连续性数据中心业务连续性站点部署的范畴内,我们先以距离为一个主要的考虑维度。那么,就可以分成同城距离内的数据中心部署和无距离限制的部署(也可以称作异地部署,但事实上并不要拘泥于必须要异地,同城范围内也可以使用无距离限制的部署模式)。
基础上,我们有两个GDPS基本解决方案,一个是GDPS/PPRC一个是GDPS/AA 。从最初的技术方案设计上GDPS/PPRC为基础的方案设计就倾向于同城距离的站点部署;而GDPS/AA更适合于无距离限制的部署。因此,在这两大基础上发展出来其他的方案。
同城距离的方案中,Cross-Site Sysplex Single Site Workload是跨站点Sysplex(主机z/OS的集群架构)的部署模式。一个Sysplex分成两个部分分别部署在两个站点;数据层面通过磁盘同步数据复制技术PPRC(Peer to Peer Remote Copy)实现同步。用户的工作负载部署在主磁盘所在的主站点。当主站点故障时,GDPS自动实现站点切花和系统恢复。实现灾备快速切换。计划内可以进行应用无感知的站点切换。
Cross-Site Sysplex Multi-Site Workload同样是跨站点Sysplex的部署模式。和Single Site Workload不同的地方就是在两个站点都部署用户的工作负载,实现工作负载的两个站点双活。当主站点故障时,GDPS自动实现站点切花和系统恢复。根据不同的具体配置,可以实现计划内/外的应用无感知切换,或计划外RTO一小时内的站点切换。
以上两种方案基本上都采用了GDPS/PPRC的基础方案,只在一些细节配置上进行调整而实现。
在同城距离方案中,还有一支是从GDPS/AA Sites无距离限制的方案中变异来的。那就是GDPS/AA ZDL(Zero Data Loss)方案。这个方案的最大特色是集成了GDPS/AA基础方案的软件复制技术和磁盘复制技术的新特性。在保持了软件复制的灵活性的基础上,通过磁盘同步数据复制做到RPO=0。
ZDL方案在实际部署的时候又可以分成两周部署模式,非对称部署和对称部署。根据用户对业务连续性的要求和实际的站点切换和回切的期望可以选定其中一种进行部署。非对称模式的特点是在主站点到备站点方向进行切换时,无论计划内外均做到零数据丢失。但从备站点回切至主站点时采用计划内的切换手段来保障数据无丢失。顾名思义,对称模式的部署就是双向切换都支持计划内外的零数据丢失。(参见《零数据丢失 -- 开创主机双活数据中心新模式》)
当采用了ZDL对称模式部署时,您就会发现在系统架构层面已经是一个具有相当保护数据能力的业务连续性平台了。在这个平台基础上,根据您对业务连续性和站点间角色的划分,进一步可以做到是站点切换模式还是平台运行的模式。站点切换模式主要从站点接管的角度来看,用户工作负载的部署以其中一个站点为主;而平台运行模式则可以根据不同工作负载的业务连续性要求进行双站点的统一部署和管理。
回到无距离限制的方案,基础的方案就是GDPS/AA基于软件数据复制的方案。然而,从用户的角度一定还有不同的需求。我们也可以设想一下,在异地进行数据中心灾备或双活部署,如果系统层面可以提供一个较好的方式解决由于距离原因而导致的可能数据丢失的问题,那也是很好的。另一个方面,如果有多个数据中心的存在,那么统一地成体系地对多站点进行管理,同时从工作负载的角度进行多活部署,也会更好地发挥多个数据中心的作用,也是值得探寻的一个方向。上图中两个虚线框就想表示这个意思。各位观众心里有什么奇思妙想,也可以一吐为快。欢迎留言。
总之,进行数据中新的灾备建设和业务连续性提升不是一件容易的事情。如果您心里有困惑,那么就让IBM GDPS 20多年的经验来帮助您吧 —— 从企业级灾备规划、业务连续性规划,政策法规、监管要求等等方面,提供包括但不仅限于诸如机房选址、数据中心整体灾备能力、双活多活策略、两地三中心、多地多中心架构部署等的咨询,提供基于GDPS解决方案的规划实施、深度裁剪、性能调优等等的服务。做到让用户清清楚楚地决策、明明白白地花钱,最重要的是达到预期的目标和效果。同时在运维过程中,不会一出问题就怪网络、一有事情就怪临时工开的挖掘机。
本文作者:李洪涛,从事IBM主机相关技术和方案实施工作已有24年的经验。致力于为中国主机客户提供尽心尽力的服务。对业界其他的IT技术和架构也有充满兴趣。
好文章,需要你的鼓励


Siri AI、ChatGPT、Claude真实横评,谁才是最强AI助手?
海外博主做了一次 Siri AI、ChatGPT、Claude 横评。看完之后我最大的感受是,AI 助手的竞争已经不只是模型能力,而是谁离用户更近。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

LMMs-Lab与NTU MMLab联手微软:让AI智能体“一句话自我进化“的秘密
SkillOpt-Lite通过将智能体技能优化形式化为零阶优化问题,提出极简流水线:把执行轨迹存为文本文件,让AI直接用文件系统工具翻日志、找规律、改技能,配合独立验证门控,比复杂的多智能体优化框架跑得更快效果更好,并自然延伸至执行框架自动优化(HarnessOpt),使轻量模型能够超越大模型。
2018
09/13
11:00
分享
点赞

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber、Wayve与Waymo的伦敦无人驾驶出租车大战即将开启
Mobileye计划2027年在美国推出自动驾驶出租车服务
Waymo召回近4000辆无人出租车,原因是其进入高速公路施工区域
特斯拉在奥斯汀开始测试无方向盘无踏板Cybercab量产版
图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
Omdia报告:Dell PowerProtect助力企业三年期网络弹性TCO最高降低61%
“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
