
全国仅两家!曙光深度学习开源平台入列国家AI重大工程
2018年3月5日上午,十三届全国人大一次会议在人民大会堂开幕,国务院总理李克强在政府工作报告中再提“人工智能”。
报告提出:实施大数据发展行动,加强新一代人工智能研发应用,在医疗、养老、教育、文化、体育等多领域推进“互联网+”。发展智能产业,拓展智能生活。运用新技术、新业态、新模式,大力改造提升传统产业。

这是继2017年后,“人工智能”再次被写入政府工作报告。
全国仅两家!曙光深度学习开源平台入列国家AI重大工程
2018年初,国家发改委公布了《2018年“互联网+”、人工智能创新发展和数字经济试点重大工程支持项目名单》,曙光信息产业股份有限公司联合中国科学院计算技术研究所、北京市商汤科技开发有限公司、云宏信息科技股份有限公司、成都索贝数码科技股份有限公司申报的“面向深度学习应用的开源平台建设及应用”项目成功入选,成为全国仅有的两家获国家支持的深度学习应用开源平台建设者之一。
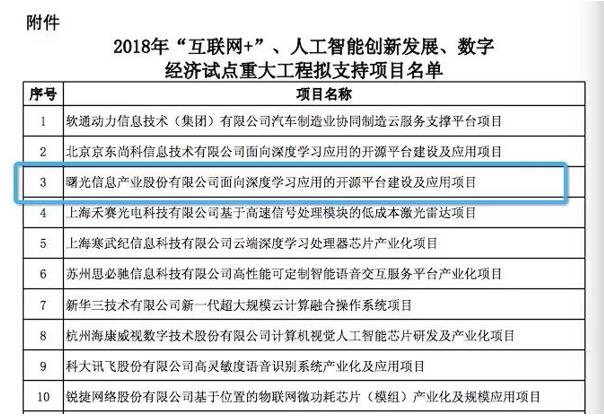
此次面向深度学习应用的开源平台重大项目,标志着我国在国家级AI开源平台建设中迈出了重要的一步,平台的建设将集中整合优势企业的产业领先资源,突破我国人工智能产业发展瓶颈,夯实产业发展基础,带动国产算法、软件、应用协同发展,助推人工智能行业应用,提升国产技术产品和服务的竞争力。能够成功入围也彰显了曙光在AI领域强大的技术研发实力和生态整合能力。通过该平台的建设和推广,曙光公司也将更好地发挥人工智能时代的赋能者角色。
打造人工智能的“安卓系统”,促进中国AI技术创新发展
作为人工智能创新发展的核心技术研发平台之一,面向深度学习应用的开源平台是建设人工智能生态的关键环节之一,“开源”明确了其开放属性,“平台”则强调其通用属性,其重要性可形象地比喻为人工智能领域的“安卓系统”。
目前我国人工智能领域软件生态面临很大挑战,深度学习开发难度大、开发环境不完善,且资源标准不统一,异构资源复杂,这些都为软件开发设置了较高的门槛,提升了开发成本,严重制约了开发的速度和丰富程度。而市场被国外相关产品和技术框架占据,国内产业生态的发展阻力重重,不打破这种局面,我国人工智能发展难以实现突破,通过人工智能实现“换道超车”也有沦为空想之虞。
基于在人工智能及深度学习领域百余项专利等核心前沿技术,依托覆盖深度学习指令集、核心算法库、软件栈、计算框架以及应用开发的全技术链强大的科研能力,以及开源深度学习框架和开源大数据软件等软件开源基础,曙光将全面构建面向深度学习应用的开源平台。该平台将支持CPU、GPU、FPGA等多类型异构硬件,提供完整的开发协议栈,配套开发工具,有效降低开发难度。这就像是给人工智能的开发者提供了一个“安卓系统”,统一的开源平台可以促进上下游产业链对接,开发难度的降低可望促使应用创新进一步繁荣,这将进一步促进国产算法、软件、应用的协同发展,提升国产技术产品和服务的竞争力,对构建人工智能国产生态链,提升信息安全保障,具有重要的现实意义和推动作用。
作为联合申报单位中唯一的科研院所,中科院计算技术研究所将充分发挥高性能计算机研究中心的在深度学习相关高性能算法设计及优化的优势,调动计算所旗下寒武纪人工智能芯片的亮点资源,在软、硬两大核心能力上为平台提供核心技术支持。
构建开放计算服务平台,像云一样提供和享用AI服务
人工智能的发展离不开应用场景的支撑,并且跟大规模设备资源、支撑算法库、训练库等平台级资源密不可分,在这方面,国内的平台资源严重不足,也大大制约了人工智能应用的开发和产业发展。曙光无可比拟的计算资源优势以及超大规模平台运营管理能力,遍布全国的网络服务资源为开源平台的建设和应用提供了强有力的保障。
通过建设和整合超过40家城市云服务中心,10余家先进计算中心以及地球数值模拟装置等城市大脑和科学大脑资源,曙光将构建一个庞大的人工智能开放计算公共平台,以及一个统一的服务门户,提供运营服务的同时,辅以算法训练及模型配置等强大的计算服务,和超过100PB的跨媒体、多模态数据服务,最大程度地满足开发者资源需求的问题。同时,通过加强与各科研院所和应用厂商的合作,开展不少于10类以上的人工智能应用验证,涵盖图像处理、语音处理、自然语言理解等典型的人工智能应用领域。
作为国内深度学习第一厂商,商汤科技目前已拥有国内最大的深度学习集群,通过自主研发建立了国内顶级的深度学习超算中心。凭借在高性能异构基础算法库、深度学习大规模训练系统等方面的先动优势,商汤科技将在联合项目中承担算法训练库建设和跨媒体数据关联的重任。
有了强大的技术保障、资源优势和运营能力,曙光计划在建设周期内帮助地方政府、各类企业、科研院校等孵化超过100个项目,旨在让全国各地区各领域的开发者和用户,能像在公共云计算平台一样,方便地开发AI应用、取用AI服务。
人工智能开放计算服务平台的建设,将为各类人工智能应用提供创新沃土,创新应用籍此得到孵化和应用,这对于加强我国人工智能产业渗透能力,促进人工智能与实体经济深度融合,推动我国区域产业升级和各行各业的创新发展具有标杆性意义。
曙光公司副总裁沙超群表示,自2017年 “数据中国智能计划”发布以来,曙光的人工智能业务捷报频传,增长迅猛。此次在诸多竞争对手中胜出,作为人工智能的国家队承建国家级面向深度学习应用的开源平台,对曙光AI而言将是又一契机。曙光将加快探索出一条独特的产学研一体化发展道路,为建立更完善的产业生态不断努力,更好为产业和经济发展赋能。
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2018
03/08
09:28
分享
点赞

边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
Moonshot即将发布的Kimi K3有望赶超Anthropic Opus 4.8
OpenAI 为何开始卖 ChatGPT 品牌篮球?
DoorDash推出命令行工具,开发者可借助AI智能体直接下单
